我用 Python 爬取了全國 4500 個熱門景點����,告訴你國慶哪里去不得�?
金秋九月,丹桂飄香���,在這秋高氣爽����,陽光燦爛的收獲季節(jié)里,我們送走了一個個暑假余額耗盡哭著走向校園的孩子們�����,又即將迎來一年一度偉大祖國母親的生日趴體(無心上班�����,迫不及待想為祖國母親慶生)����。
那么問題來了,去哪兒玩呢�?百度輸了個“國慶”,出來的第一條居然是“去哪里旅游人少”……emmmmmmm��,因缺思廳��。

于是我萌生了通過旅游網(wǎng)站的景點銷量來判斷近期各景點流量情況的想法(這個想法很危險啊)
所以這次的目標呢��,是爬去哪兒網(wǎng)景點頁面,并得到景點的信息��,大家可以先思考下大概需要幾步���。

本文建議有一定 Python 基礎(chǔ)和前端(html����,js)基礎(chǔ)的朋友閱讀�,零基礎(chǔ)可以去看我之前的文。(咳咳����,不能總更小白文,這樣顯得我不(mei)夠(you)專(xue)業(yè)(xi))�����。
百度的地圖 API 和 echarts
因為前幾次爬蟲都是爬一些文本信息��,做一下詞云之類的���,我覺得:沒!意�����!思!了���!這次正好爬的是數(shù)據(jù)�����,我決定用數(shù)據(jù)的好基友——圖表來輸出我爬取的數(shù)據(jù)����,也就是說我要用爬取的景點銷量以及景點的具體位置來生成一些可視化數(shù)據(jù)���。
安利一下百度的地圖 API 和 echarts���,前者是專門提供地圖 API 的工具,聽說好多 APP 都在用它����,后者是數(shù)據(jù)處理居家旅行的好伙伴,用了之后�����,它好,我也好(隱約覺得哪里不對)�。
API 是什么,API 是應(yīng)用程序的編程接口�����,就好像插頭與插座一樣�,我們的程序需要電(這是什么程序?),插座中提供了電���,我們只需要在程序中寫一個與插座匹配的插頭接口��,就可以使用電來做我們想做的事情�����,而不需要知道電是如何產(chǎn)生的�����。
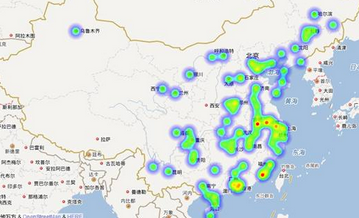
引入數(shù)據(jù)后的百度熱力圖

通過 API 對接的開發(fā)者與服務(wù)商
確定輸出文件
有人可能說����,我已經(jīng)懂了 API 是啥意思了���,可是咋個用呢���。關(guān)于這一點,我很負責(zé)任的告訴你:我也不會��。
但是��!百度地圖提供了很多 API 使用示例���,有 html 基礎(chǔ)�����,大致可以看懂���,有 js 基礎(chǔ)就可以嘗試改函數(shù)了(不會 js 的,我默默地復(fù)制源代碼)�,仔細觀察源代碼,可以知道熱力圖生成的主要數(shù)據(jù)都存放在 points 這個變量中��。
這種[{x:x,x:x},{x:x,x:x}]格式的數(shù)據(jù)��,是一種 json 格式的數(shù)據(jù)�����,由于具有自我描述性,所以比較通俗易懂�,大概可以知道這里的三個值,前兩個是經(jīng)緯度�,最后一個應(yīng)該是權(quán)重(我猜的)。
也就是說�,如果我希望將景點的熱門程度生成為熱力圖,我需要得到景點的經(jīng)緯度����,以及它的權(quán)重,景點的銷量可以作為權(quán)重����,并且這個數(shù)據(jù)應(yīng)該是 json 格式的呈現(xiàn)方式。
echarts 也是一樣滴(*^__^*)����。
爬取數(shù)據(jù)
這次的爬蟲部分是比較簡單的。分析網(wǎng)址(去哪兒景點)→爬取分頁中信息(景點經(jīng)緯度�����、銷量)→轉(zhuǎn)為 json 文件���。
分析去哪兒景點頁的網(wǎng)址���,可得出結(jié)構(gòu):http://piao.qunar.com/ticket/list.htm?keyword=搜索地點®ion=&from=mpl_search_suggest&page=頁數(shù)
這次沒有用正則來匹配內(nèi)容,而使用了 xpath 匹配�����,非常好用�。
def getList():
place = raw_input('請輸入想搜索的區(qū)域、類型(如北京��、熱門景點等):')
url = 'http://piao.qunar.com/ticket/list.htm?keyword='+ str(place) +'®ion=&from=mpl_search_suggest&page={}'
i = 1
sightlist = []
while i:
page = getPage(url.format(i))
selector = etree.HTML(page)
print '正在爬取第' + str(i) + '頁景點信息'
i+=1
informations = selector.xpath('//div[@class="result_list"]/div')
for inf in informations: #獲取必要信息
sight_name = inf.xpath('./div/div/h3/a/text()')[0]
sight_level = inf.xpath('.//span[@class="level"]/text()')
if len(sight_level):
sight_level = sight_level[0].replace('景區(qū)','')
else:
sight_level = 0
sight_area = inf.xpath('.//span[@class="area"]/a/text()')[0]
sight_hot = inf.xpath('.//span[@class="product_star_level"]//span/text()')[0].replace('熱度 ','')
sight_add = inf.xpath('.//p[@class="address color999"]/span/text()')[0]
sight_add = re.sub('地址:|(.*?)|\(.*?\)|��,.*?$|\/.*?$','',str(sight_add))
sight_slogen = inf.xpath('.//div[@class="intro color999"]/text()')[0]
sight_price = inf.xpath('.//span[@class="sight_item_price"]/em/text()')
if len(sight_price):
sight_price = sight_price[0]
else:
i = 0
break
sight_soldnum = inf.xpath('.//span[@class="hot_num"]/text()')[0]
sight_url = inf.xpath('.//h3/a[@class="name"]/@href')[0]
sightlist.append([sight_name,sight_level,sight_area,float(sight_price),int(sight_soldnum),float(sight_hot),sight_add.replace('地址:',''),sight_slogen,sight_url])
time.sleep(3)
return sightlist,place
這里把每個景點的所有信息都爬下來了(其實是為了練習(xí)使用 xpath……)�����。
使用了 while 循環(huán)����,for 循環(huán)的 break 的方式是發(fā)現(xiàn)無銷量時給 i 值賦零,這樣 while 循環(huán)也會同時結(jié)束�����。
地址的匹配使用 re.sub() 函數(shù)去除了 n 多復(fù)雜信息,這點后面解釋
輸出本地文本
為了防止代碼運行錯誤����,維護代碼運行的和平,將輸出的信息列表存入到 excel 文件中了�,方便日后查閱,很簡單的代碼���,需要了解 pandas 的用法���。
def listToExcel(list,name):
df = pd.DataFrame(list,columns=['景點名稱','級別','所在區(qū)域','起步價','銷售量','熱度','地址','標語','詳情網(wǎng)址'])
df.to_excel(name + '景點信息.xlsx')
百度經(jīng)緯度 API
非常悲傷的,(?﹏?)我沒找到去哪兒景點的經(jīng)緯度����,以為這次學(xué)(zhuang)習(xí)(bi)計劃要就此流產(chǎn)了。(如果有人知道景點經(jīng)緯度在哪里請告訴我)
但是���,enhahhahahaha�����,我怎么會放棄呢�����,我又找到了百度經(jīng)緯度 API��。
網(wǎng)址:http://api.map.baidu.com/geocoder/v2/?address=地址&output=json&ak=百度密鑰�����,修改網(wǎng)址里的“地址”和“百度密鑰”�����,在瀏覽器打開�,就可以看到經(jīng)緯度的 json 信息��。
#上海市東方明珠的經(jīng)緯度信息
{"status":0,"result":{"location":{"lng":121.5064701060957,"lat":31.245341811634675},"precise":1,"confidence":70,"level":"UNKNOWN"}}
百度密鑰申請方法:http://jingyan.baidu.com/article/363872eccda8286e4aa16f4e.html
這樣我就可以根據(jù)爬到的景點地址��,查到對應(yīng)的經(jīng)緯度辣����!Python 獲取經(jīng)緯度 json 數(shù)據(jù)的代碼如下:
def getBaiduGeo(sightlist,name):
ak = '密鑰'
headers = {
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
address = 地址
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
觀察獲取的 json 文件,location 中的數(shù)據(jù)和百度 API 所需要的 json 格式基本是一樣�����,還需要將景點銷量加入到 json 文件中,這里可以了解一下 json 的淺拷貝和深拷貝知識��,最后將整理好的 json 文件輸出到本地文件中���。
def getBaiduGeo(sightlist,name):
ak = '密鑰'
headers = {
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36'
}
list = sightlist
bjsonlist = []
ejsonlist1 = []
ejsonlist2 = []
num = 1
for l in list:
try:
try:
try:
address = l[6]
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
except KeyError,e:
address = l[0]
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
except KeyError,e:
address = l[2]
url = 'http://api.map.baidu.com/geocoder/v2/?address=' + address + '&output=json&ak=' + ak
json_data = requests.get(url = url).json()
json_geo = json_data['result']['location']
except KeyError,e:
continue
json_geo['count'] = l[4]/100
bjsonlist.append(json_geo)
ejson1 = {l[0] : [json_geo['lng'],json_geo['lat']]}
ejsonlist1 = dict(ejsonlist1,**ejson1)
ejson2 = {'name' : l[0],'value' : l[4]/100}
ejsonlist2.append(ejson2)
print '正在生成第' + str(num) + '個景點的經(jīng)緯度'
num +=1
bjsonlist =json.dumps(bjsonlist)
ejsonlist1 = json.dumps(ejsonlist1,ensure_ascii=False)
ejsonlist2 = json.dumps(ejsonlist2,ensure_ascii=False)
with open('./points.json',"w") as f:
f.write(bjsonlist)
with open('./geoCoordMap.json',"w") as f:
f.write(ejsonlist1)
with open('./data.json',"w") as f:
f.write(ejsonlist2)
在設(shè)置獲取經(jīng)緯度的地址時�����,為了匹配到更準確的經(jīng)緯度���,我選擇了匹配景點地址,然而��,景點地址里有各種神奇的地址�,帶括號解釋在 XX 對面的,說一堆你應(yīng)該左拐右拐各種拐就能到的�,還有英文的……
于是就有了第三章中復(fù)雜的去除信息(我終于圓回來了!)����。
然而,就算去掉了復(fù)雜信息���,還有一些匹配不到的景點地址�,于是我使用了嵌套 try,如果景點地址匹配不到�;就匹配景點名稱,如果景點名稱匹配不到���;就匹配景點所在區(qū)域��,如果依然匹配不到����,那我……那我就……那我就跳過ㄒ_ㄒ……
身為一個景點�,你怎么能,這么難找呢�!不要你了�����!
這里生成的三個 json 文件�����,一個是給百度地圖 API 引入用的�,另兩個是給 echarts 引入用的。
網(wǎng)頁讀取 json 文件
將第二章中所述的百度地圖 API 示例中的源代碼復(fù)制到解釋器中���,添加密鑰�,保存為 html 文件,打開就可以看到和官網(wǎng)上一樣的顯示效果��。
echarts 需要在實例頁面����,點擊頁面右上角的 EN 切換到英文版,然后點擊 download demo 下載完整源代碼���。
根據(jù) html 導(dǎo)入 json 文件修改網(wǎng)頁源碼�,導(dǎo)入 json 文件�。
#百度地圖api示例代碼中各位置修改部分
<head>
<script src="http://libs.baidu.com/jquery/2.0.0/jquery.js"></script>
</head>
<script type="text/javascript">
$.getJSON("points.json", function(data){
var points = data;
script中原有函數(shù);
});
</script>
這里使用了 jQuery 之后����,即使網(wǎng)頁調(diào)試成功了,在本地打開也無法顯示網(wǎng)頁了���,在 chrome 中右鍵檢查���,發(fā)現(xiàn)報錯提示是需要在服務(wù)器上顯示,可是��,服務(wù)器是什么呢?
百度了一下����,可以在本地創(chuàng)建一個服務(wù)器,在終端進入到 html 文件所在文件夾�,輸入 python -m SimpleHTTPServer,再在瀏覽器中打開 http://127.0.0.1:8000/���,記得要將 html 文件名設(shè)置成 index.html 哦��!

后記
因為注冊但沒有認證開發(fā)者賬號����,所以每天只能獲取 6K 個經(jīng)緯度 API(這是一個很好的偷懶理由)�,所以我選擇了熱門景點中前 400 頁(每頁 15 個)的景點。
結(jié)果可想而知��,(?﹏?)為了調(diào)試因為數(shù)據(jù)增多出現(xiàn)的額外 Bug��,最終的獲取的景點數(shù)據(jù)大概在 4500 條左右(爬取時間為 2017 年 9 月 10 日����,爬取關(guān)鍵詞:熱門景點����,僅代表當(dāng)時銷量)�。
熱門景點熱力圖
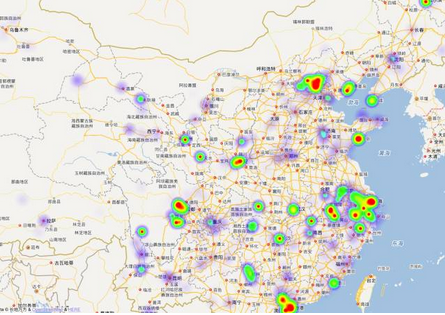
熱門景點示意圖
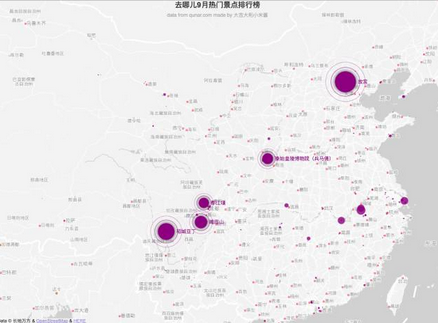
這些地圖上很火爆的區(qū)域�,我想在國慶大概是這樣的

這樣的

還有這樣的

將地圖上熱門景點的銷量 Top20 提取出來,大多數(shù)都是耳熟能詳?shù)牡攸c����,帝都的故宮排在了第一位,而大四川則占據(jù)了 Top5 中的三位��,排在 Top20 中四川省景點就占了 6 位���。
如果不是因為地震�����,我想還會有更多的火爆的景點進入排行榜的~這樣看來如果你這次國慶打算去四川的話�����,可以腦補到的場景就是:人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人人……
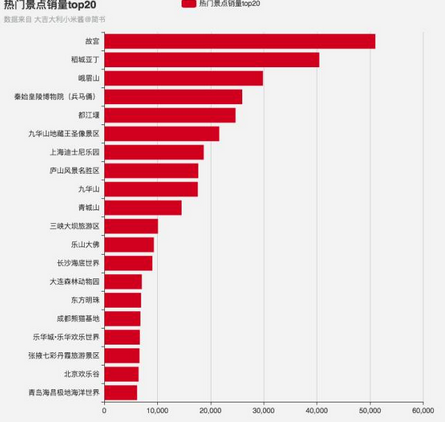
熱門景點銷量Top20
于是我又做了一個各城市包含熱門景點數(shù)目的排行����,沒想到在 4 千多個熱門景點中�����,數(shù)目最多的竟是我大浙江,是第二個城市的 1.5 倍�����,而北京作為首都也……可以說是景點數(shù)/總面積的第一位了���。
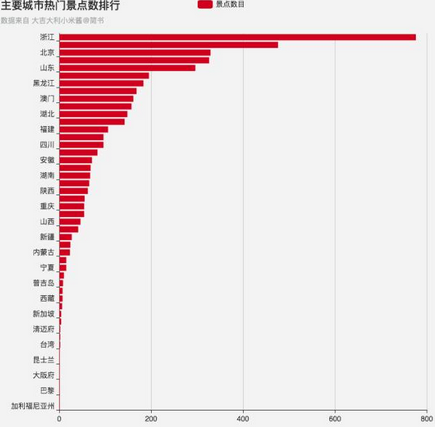
主要城市熱門景點數(shù)
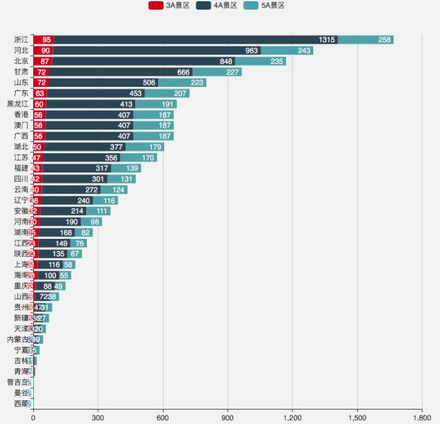
這些城市有辣么多熱門景點�,都是些什么級別的景點呢�����?由下圖看來�����,各城市的各級別景點基本與城市總熱門景點呈正相關(guān)���,而且主要由 4A 景區(qū)貢獻而來�����。
主要城市熱門景點級別
既然去哪些地方人多�,去哪里景多都已經(jīng)知道了�����,那再看看去哪些地方燒得錢最多吧�����。
下圖是由各城市景點銷售起步價的最大值-最小值扇形組成的圓�,其中湖北以單景點銷售起步價 600 占據(jù)首位。
但也可以看到���,湖北的景點銷售均價并不高(在紅色扇形中的藏藍色線條)��。而如果國慶去香港玩��,請做好錢包減肥的心理和生理準備(??ω??)?���。
PS:寫了個網(wǎng)頁,展示百度地圖的熱力圖效果和 echarts 的景點排行榜�����,方便大家查看�。
熱力度效果:http://easyinfo.online
gayhub源碼:https://github.com/otakurice/notravellist/tree/master
寫完這篇文的時候發(fā)現(xiàn) echarts 有針對 Python 的模塊可以引入�����,所以打算去學(xué)一下 Django�����、Flask 之類的 Web 框架�,最近會更一些純理論的意識流文���,大家一起進步吧~
參考資料:
1.地圖API:http://developer.baidu.com/map/reference/index.php
2.echarts:http://echarts.baidu.com/
3.API使用示例:http://developer.baidu.com/map/jsdemo.htm#c1_15
4.json:http://www.runoob.com/json/json-tutorial.html
5.xpath:http://www.runoob.com/xpath/xpath-tutorial.html
6.pandas:http://python.jobbole.com/84416/
7.百度經(jīng)緯度api:http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding
8.淺拷貝和深拷貝:http://python.jobbole.com/82294/
9.html導(dǎo)入json文件:http://www.jb51.net/article/36678.htm
作者簡介:
子科技大學(xué)畢業(yè)的機械設(shè)計喵一枚���,致力于帶領(lǐng) Python 小白們打破《從入門到放棄》的魔咒,夢想成為一名程序媛����,坐標杭州~歡迎公司勾搭。
最后���,懷著敬畏又惋惜的心情紀念一下 WePhone 創(chuàng)始人蘇享茂���,在發(fā)生自殺事件之前我不認識他,我也不希望以這種方式認識他,希望程序員的世界永遠單純�、沒有欺詐�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330