SPSS數(shù)據(jù)分析—t檢驗
SPSS中t檢驗全都集中在分析—比較均值菜單中�����。關于t檢驗再簡單說一下��,我們知道一個統(tǒng)計結果需要表達三部分內容����,即集中性、變異性���、顯著性��。
集中性的表現(xiàn)指標是均值
變異的的表現(xiàn)指標是方差��、標準差或標準誤
顯著性的則是根據(jù)統(tǒng)計量判斷是否達到顯著性水平
由于t分布樣本均值的抽樣分布����,那么基于t分布的t檢驗就是樣本均值的檢驗����,是對均值差異的顯著性檢驗。
t檢驗可以在以下三種分析中使用
1.樣本均數(shù)與總體均數(shù)的差異性分析(單樣本t檢驗)
2.配對設計樣本均數(shù)或兩非獨立兩樣本均數(shù)差異性分析(配對t檢驗)
3.兩獨立樣本均數(shù)差異性分析(獨立樣本t檢驗)
==============================================
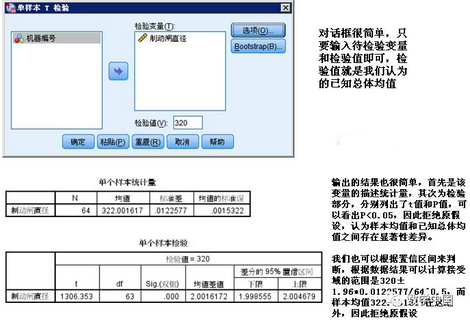
一�、分析—比較均值—單樣本T檢驗
單樣本T檢驗用來分析樣本均值與總體均值的差異,以此來判斷這個樣本來自總體的均值是否等于(大于或小于)某個已知總體的均值��,適用條件是樣本數(shù)據(jù)分布呈正態(tài)分布,小樣本情況下需要檢驗���,大樣本情況下近似正態(tài)�,該方法比較穩(wěn)健����,只要不是嚴重偏態(tài)都可以使用。
二���、分析—比較均值—配對樣本T檢驗
當配對設計的數(shù)據(jù)為連續(xù)變量時����,可以使用配對T檢驗����,配對T檢驗認為如果兩種處理實際上沒有差異,則每對數(shù)據(jù)的差值的總體均值應該為0��,實際上就是已知均值為0的單樣本T檢驗��,因此適用條件也和單樣本T檢驗一樣�����。

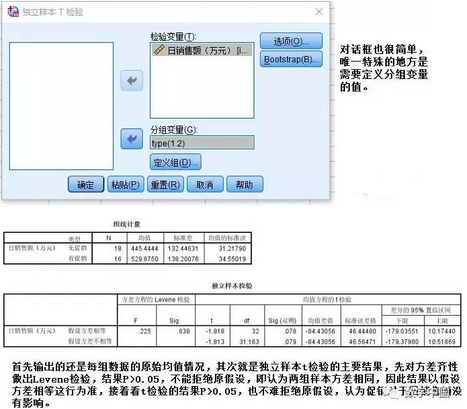
三、分析—比較均值—獨立樣本T檢驗
和配對設計相對應���,獨立樣本t檢驗是針對成組設計�����,數(shù)據(jù)資料被分為兩組,也就是兩個樣本���,它們之間是相互獨立的���,檢驗的目的是判斷這兩個樣本來自的總體均值是否存在差異。由于涉及到兩個總體�,而每個總體的離散程度即方差也不一定相同,因此需要先對兩樣本的方差齊性做出檢驗����,并且根據(jù)結果分為方差相同和方差不同兩種算法。
獨立樣本t檢驗和配對樣本t檢驗的區(qū)別:
1.獨立樣本t檢驗用于檢驗兩個獨立樣本是否來自具有相同均值的總體�,也就是檢驗兩個正態(tài)分布的總體均值是否相等。配對樣本t檢驗用于檢驗兩個相關樣本是否來自具有相同均值的正態(tài)總體�,也就是檢驗兩相關樣本的差值的均值和零均值之間的差異顯著性
2.獨立樣本是指不同樣本均值的比較,配對樣本是相同樣本均值的比較�,例如同一個體的兩次測量���,如果分為實驗組和對照組,那么就應該是獨立樣本�。
3.獨立樣本重點在于獨立,即兩樣本個體之間不存在相關關系����。而配對樣本重點在于相關,樣本個體之間存在相關關系�����,或者干脆就是同一個體�。這種相關關系會導致變異的傳遞,如果直接忽略的話����,會嚴重影響結果的準確性。因此�,雖然表面上看兩種檢驗的假設是類似的,都是兩均值之差=0����,但是正因為相關性的存在,使得實際包含的含義卻不同�����。舉例說明,觀測到服藥前后的體重變化���,屬于配對設計����,由于各個觀察對象在服藥前的體重不全相同����,所以其體重含有服藥前的體重個體變異成分���,而在服藥后���,各個觀察對象的體重下降幅度也不全相同,故存在體重下降幅度的個體變異成分��,因此觀察對象在服藥后的體重中不僅含有體重下降幅度的個體變異成分���,而且還含有服藥前的體重個體變異成分��,故服藥前后的體重資料不獨立���。對于這種不獨立資料的統(tǒng)計分析一般采用變異成分的分解或消除某一個體變異成分的方法進行統(tǒng)計處理的���,配對t檢驗就是采用服藥前后資料相減作為統(tǒng)計分析數(shù)據(jù),因而消除了服藥前體重的個體變異���,使進入統(tǒng)計分析的資料僅含有體重下降幅度的個體變異�。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330