SAS隨機(jī)抽樣以及程序初始環(huán)境
在統(tǒng)計(jì)研究中,針對(duì)容量無(wú)限或者容量很大以至于無(wú)法直接對(duì)其進(jìn)行研究的總體�����,都是通過(guò)從中抽取一部分個(gè)體作為研究對(duì)象�����,以考察總體的特征�����。被抽取的部分個(gè)體稱為該總體的一個(gè)樣本����。從總體中抽取樣本的過(guò)程,稱為抽樣��。
抽樣包括隨機(jī)抽樣和非隨機(jī)抽樣�����。非隨機(jī)抽樣是從總體中抽取指定的個(gè)體����,具有主觀意向性,這里不做討論��。
隨機(jī)抽樣是按照隨機(jī)原則��,保證個(gè)體都有一定概率被抽取到的抽樣方法����。常見(jiàn)的隨機(jī)抽樣方式有:簡(jiǎn)單隨機(jī)抽樣、系統(tǒng)抽樣����、分層抽樣���、整群抽樣、多階段抽樣�、二重抽樣以及比率抽樣。
以下將依次介紹各種隨機(jī)抽樣方法的原理�、應(yīng)用場(chǎng)景及其SAS實(shí)現(xiàn)。在論述之前�����,需要準(zhǔn)備好測(cè)試數(shù)據(jù)���。我們從互聯(lián)網(wǎng)上找了一批數(shù)據(jù)形成一張表���,數(shù)據(jù)的內(nèi)容是國(guó)內(nèi)股票市場(chǎng)各只股票的若干財(cái)務(wù)數(shù)據(jù),字段如下:
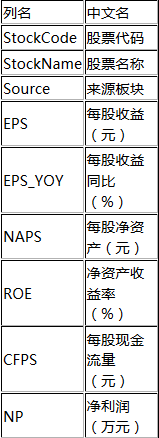
該表共有2472條觀測(cè)(記錄)��,按照Source(來(lái)源板塊)進(jìn)行統(tǒng)計(jì)���,則各組觀測(cè)數(shù)如下:
創(chuàng)業(yè)板 351
滬市主板 948
深市主板 473
中小板 700
數(shù)據(jù)下載地址:http://pan.baidu.com/share/link?shareid=134615&uk=1258687326
構(gòu)建程序初始環(huán)境:
data_null_;
workspace = "D:\SASWorkspace\練習(xí)"; *工作區(qū)根目錄;
call symput("workspace", workspace);
run;
libname Practice"&workspace.\中間數(shù)據(jù)\";
然后把原始數(shù)據(jù)上傳到Practice邏輯庫(kù)中,并命名為MainIndex_2012sea3�。
*為了不破壞原始數(shù)據(jù),把表copy到work邏輯庫(kù)中;
data Work.MainIndex_2012sea3;
setPractice.MainIndex_2012sea3;
run;
下面逐一介紹各種隨機(jī)抽樣方法及其SAS實(shí)現(xiàn)����。
(1)簡(jiǎn)單隨機(jī)抽樣
簡(jiǎn)單隨機(jī)抽樣�����,指從總體中等概率地抽取出n個(gè)個(gè)體組成樣本����。在SAS中�,可以使用surveyselect過(guò)程步來(lái)實(shí)現(xiàn)隨機(jī)抽樣。Surveyselect過(guò)程步的基本格式如下:

在第一個(gè)程序中�����,我們來(lái)實(shí)現(xiàn)最簡(jiǎn)單的場(chǎng)景:從2472條觀測(cè)中隨機(jī)抽取100條�。在程序中,除了必要的data和out選項(xiàng)外��,還需使用method設(shè)置抽樣方法為簡(jiǎn)單隨機(jī)抽樣����,其值為srs;并設(shè)置抽取的樣本容量sampsize
= 100或n = 100���。代碼如下:
*隨機(jī)抽取100條記錄�,保留所有字段,不打印;
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_srs1
method = srs
sampsize =100 /*也可以使用n = 100 */
noprint
;
run;
上面的程序?qū)τ诮Y(jié)果表保留了原始表的所有字段����,如果我們只需要保留其中的某幾個(gè)字段,則可以使用id語(yǔ)句�。
*隨機(jī)抽取100條記錄,只保留StockCode和StockName字段���,不打印;
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_srs2
method = srs
sampsize =100
noprint;
id StockCode StockName;
run;
如果沒(méi)有指定隨機(jī)數(shù)種子(seed)�,則SAS程序會(huì)使用計(jì)算機(jī)的時(shí)間作為種子�����?��?梢允褂胹eed選項(xiàng)設(shè)定隨機(jī)數(shù)初始種子���。Seed的值必須是一個(gè)正整數(shù),否則SAS會(huì)使用計(jì)算機(jī)的時(shí)間作為種子(零或負(fù)整數(shù)的情況)��,或者出錯(cuò)(小數(shù)的情況)����。
*隨機(jī)抽取100條記錄,保留所有字段��,不打印;
*指定隨機(jī)數(shù)種子;
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_srs4
method = srs
sampsize =100
seed =1000
noprint;
run;
在實(shí)際應(yīng)用場(chǎng)景中���,有時(shí)候需要獨(dú)立重復(fù)抽取多組樣本�����,這時(shí)可以使用rep選項(xiàng)�。SAS程序會(huì)以rep設(shè)定的值獨(dú)立重復(fù)抽取若干次樣本��,每組樣本的容量是sampsize或n選項(xiàng)指定的值�����。
*隨機(jī)抽取100條記錄�����,保留所有字段��,不打印;
*指定獨(dú)立重復(fù)抽樣的次數(shù);
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_srs5
method = srs
sampsize =100
rep =3
noprint
;
run;
樣本容量的另一種表述是其占總體的比例�����。比如,抽取10%的樣本�����。這時(shí)我們使用samprate或rate替代sampsize�。Samprate的值可以是正小數(shù),也可以是正整數(shù)��。當(dāng)samprate的值是正小數(shù)時(shí)�,其值在(0,
1]之間,不可為零���;為1時(shí)表示100%��。當(dāng)samprate是正整數(shù)時(shí)�����,表示相應(yīng)的百分比���,如10表示10%,需要注意的是�,整數(shù)1表示100%��,而不是1%����。
*隨機(jī)抽取總體的10%作為樣本��,保留所有字段�,不打印;
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_srs6
method = srs
samprate =0.1/*也可以使用rate =0.1 */
noprint
;
run;
*隨機(jī)抽取總體的10%作為樣本����,保留所有字段,不打印;
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_srs7
method = srs
samprate =10/*也可以使用rate =10 */
noprint
;
run;
有時(shí)候�,我們并不需要把原始表的所有觀測(cè)都作為研究對(duì)象,而只是針對(duì)其中的某一子集來(lái)抽樣�����。比如如果我們只需要研究滬市主板的股票�����,那么只需要在相關(guān)的觀測(cè)中抽取樣本作為研究對(duì)象����。Data選項(xiàng)后面可以使用where=語(yǔ)句來(lái)實(shí)現(xiàn)對(duì)總體觀測(cè)的篩選���。
*如果只想在滬市主板上抽取100個(gè)樣本;
procsurveyselect
data = Work.MainIndex_2012sea3(where=(Source ='滬市主板'))
out = Work.MainIndex_2012sea3_srs8
method = srs
sampsize =100
noprint
;
run;
(2)分層抽樣
分層抽樣是將總體按某種特征分為若干次級(jí)總體(層),再在每一層中進(jìn)行隨機(jī)抽樣�����,把結(jié)果組成一個(gè)樣本的方法��。描述層次特征的變量稱為分層變量,比如在我們的測(cè)試數(shù)據(jù)中���,我們可以使用Source(來(lái)源板塊)變量把原始數(shù)據(jù)分為滬市主板、深市主板���、中小板���、創(chuàng)業(yè)板四類(層)����。Surveyselect過(guò)程步使用strata語(yǔ)句來(lái)指定分層變量����。在抽樣之前,需要對(duì)原始數(shù)據(jù)按照strata指定的分層變量進(jìn)行排序�����。最簡(jiǎn)單的分層抽樣場(chǎng)景是��,最總體中的所有樣本���,指定一個(gè)分層變量,每一層都使用同樣的抽樣比例�。以下是最簡(jiǎn)單分層抽樣場(chǎng)景的代碼:
*由于分層抽樣需要對(duì)原始數(shù)據(jù)進(jìn)行排序,因此我們?cè)購(gòu)?fù)制一張臨時(shí)表;
data Work.MainIndex_2012sea3_tmp;
setWork.MainIndex_2012sea3;
run;
*按照分層變量Source排序;
procsortdata =Work.MainIndex_2012sea3_tmp;by Source;
*用Source分層�,每一層抽取10%的樣本;
procsurveyselect
data = Work.MainIndex_2012sea3_tmp
out = Work.MainIndex_2012sea3_strata1
method = srs
samprate =0.1
noprint;
strata Source; * 使用Source作為分層變量;
run;
如果各層抽取的比例不一樣,則應(yīng)賦予samprate一個(gè)數(shù)組��,數(shù)組的每一個(gè)元素的值分別代表各個(gè)層的抽樣比例��。數(shù)組元素的順序需與分層變量排序后的順序一致����。
*用Source分層���,一共有4層,各層抽取的比例不一樣����,在samprate中定義;
*分層變量Source的排序順序是:創(chuàng)業(yè)板 滬市主板 深市主板 中小板;
procsurveyselect
data = Work.MainIndex_2012sea3_tmp
out = Work.MainIndex_2012sea3_strata2
method = srs
samprate = (0.1,0.3,0.5,0.2)
noprint
;
strata Source; * 使用Source作為分層變量;
run;
同樣,也可以使用sampsize分別指定每一層的抽樣個(gè)數(shù)�����。
*用Source分層���,一共有4層�����,各層抽取的個(gè)數(shù)不一樣�,在sampsize中定義;
*分層變量Source的排序順序是:創(chuàng)業(yè)板 滬市主板 深市主板 中小板;
procsurveyselect
data = Work.MainIndex_2012sea3_tmp
out = Work.MainIndex_2012sea3_strata3
method = srs
sampsize = (10,60,50,30)
noprint;
strata Source; * 使用Source作為分層變量;
run;
如果層數(shù)較多�,且需要對(duì)不同層分別指定抽樣比例或抽樣個(gè)數(shù),則需要建立抽樣表����。抽樣表需要包含分層變量���,以及每一層對(duì)應(yīng)的抽樣比例或抽樣個(gè)數(shù);如果是抽樣比例����,則變量必須命名為_(kāi)rate_,如果是抽樣個(gè)數(shù)���,則變量必須命名為_(kāi)nsize_��。
*按比例分層抽樣,建立抽樣表;
procsql;
create tableWork.Samptab_rate (
Sourcechar(10),
_rate_num
);
insert intoWork.Samptab_rate values ('創(chuàng)業(yè)板',0.1);
insert intoWork.Samptab_rate values ('滬市主板',0.3);
insert intoWork.Samptab_rate values ('深市主板',0.5);
insert intoWork.Samptab_rate values ('中小板',0.2);
quit;
*按比例分層抽樣���,將抽樣表賦值給samprate;
procsurveyselect
data = Work.MainIndex_2012sea3_tmp
out = Work.MainIndex_2012sea3_strata4
method = srs
samprate = Work.Samptab_rate
noprint;
strata Source; * 使用Source作為分層變量;
run;
*按個(gè)數(shù)分層抽樣�����,建立抽樣表;
procsql;
create tableWork.Samptab_size (
Sourcechar(10),
_nsize_num
);
insert intoWork.Samptab_size values ('創(chuàng)業(yè)板',10);
insert intoWork.Samptab_size values ('滬市主板',60);
insert intoWork.Samptab_size values ('深市主板',50);
insert intoWork.Samptab_size values ('中小板',30);
quit;
*按個(gè)數(shù)分層抽樣�,將抽樣表賦值給sampsize;
procsurveyselect
data = Work.MainIndex_2012sea3_tmp
out = Work.MainIndex_2012sea3_strata5
method = srs
sampsize = Work.Samptab_size
noprint;
strata Source; * 使用Source作為分層變量;
run;
(3)系統(tǒng)抽樣
系統(tǒng)抽樣是把總體的個(gè)體進(jìn)行排序�,計(jì)算出抽樣距離,然后按照這一固定的抽樣距離抽取樣本的方法����。第一個(gè)樣本采用簡(jiǎn)單隨機(jī)抽樣的辦法抽取�,此后每隔一個(gè)抽樣距離的大小抽取一個(gè)樣本���。抽樣距離等于總體容量除以樣本容量�。
*每隔10個(gè)抽取一個(gè)1個(gè);
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_sys1
method = sys
sampsize =248/*總體容量2472����,樣本容量248,意味著抽樣距離為10 */
noprint;
run;
在系統(tǒng)抽樣中�����,可以使用控制變量來(lái)對(duì)原始數(shù)據(jù)進(jìn)行排序�。控制變量使用control語(yǔ)句���。SAS程序首先安裝control中的變量排序����,然后采用系統(tǒng)抽樣抽取樣本��。
*每隔10個(gè)抽取一個(gè)1個(gè);
*使用Source作為控制變量���,這樣程序會(huì)對(duì)輸入數(shù)據(jù)按照Source進(jìn)行排序;
procsurveyselect
data = Work.MainIndex_2012sea3
out = Work.MainIndex_2012sea3_sys2
method = sys
sampsize =248
noprint;
control Source;
run;
下面的程序是將系統(tǒng)抽樣與分層抽樣相結(jié)合�����,實(shí)現(xiàn)較為復(fù)雜的抽樣方式��,以滿足實(shí)際應(yīng)用的需求��。在這個(gè)例子中���,程序按照strata指定的變量對(duì)原始數(shù)據(jù)進(jìn)行分層��,在每一層中使用control變量排序���,然后分別進(jìn)行系統(tǒng)抽樣各抽取248個(gè)個(gè)體,因此����,最終的結(jié)果有992條觀測(cè)�。
*分層系統(tǒng)抽樣;
procsurveyselect
data = Work.MainIndex_2012sea3_tmp
out = Work.MainIndex_2012sea3_sys3
method = sys
sampsize =248
noprint;
strata Source;
control EPS;
run;
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330