SPSS分析技術(shù):二階聚類分析�����;為什么出現(xiàn)大學生“裸貸”業(yè)務���,因為放貸者知道貸款者還不起
今天將介紹一種智能聚類法��,二階聚類法��,在開始介紹之前����,先解答很多人在后臺提出的一個疑問:那就是很多分析者發(fā)現(xiàn)����,對同一套數(shù)據(jù)應用不同的聚類分析方法,其結(jié)果經(jīng)常是不一致的�����,甚至完全不一樣�,到底哪個結(jié)果是“正確”的呢?
草堂君來解釋一下:聚類分析在眾多數(shù)據(jù)分析方法中����,其應用范圍和作用都是非常亮眼的表現(xiàn)���,但是聚類分析與其它數(shù)據(jù)分析方法之間還有一個重要的區(qū)別,就是聚類分析是一種探索性的分析方法��,分析結(jié)果沒有絕對的對錯之分����,只有相對的好壞區(qū)別。聚類分析的結(jié)果是否“漂亮”是由結(jié)果的“有用性”來決定的�����。如何判斷結(jié)果的有用性�����,有以下幾個主觀判斷的方向:
每個類別中個案的數(shù)量盡量接近���。如果分析者聚類分析的目的不是為了發(fā)現(xiàn)異常值��,那么總是希望每個類別中個案(記錄)的數(shù)量盡量接近���。例如��,聚類分析的結(jié)果是大量的記錄集中在一個類別里,這樣的聚類結(jié)果是完全沒有實用性的�����,相當于沒有聚類�。
不同類別間,各個因素(變量)間的差別應該盡量的大��。例如��,對客戶群體進行分類�����,不同類別的客戶在年齡��、性別���、收入等因素間的距離應該盡量大��??梢杂妙悇e作為區(qū)分水平���,對各個因素(變量)做單因素方差分析�����,通過比較F值的大小來得到各個變量在本次聚類分析中的相對重要性�����,F(xiàn)值越大的變量����,對聚類結(jié)果的影響也越大。如果很多變量的單因素方差分析結(jié)果是沒有顯著性差異�,那么聚類分析的結(jié)果很可能是不太好的。
二階聚類法
二階聚類法又稱為兩步聚類法�,是一種智能聚類方法,能夠用于海量和復雜類別結(jié)構(gòu)數(shù)據(jù)的聚類分析����。與前面介紹的層次聚類法和K-均值聚類法相比,二階聚類法有著它們無法比擬的算法優(yōu)勢:
能夠用于二階聚類的變量既可以是連續(xù)型變量��,也可以是離散型變量�。這與層次聚類和K-均值聚類有很大不同,層次聚類需要區(qū)分變量的數(shù)據(jù)類型選擇距離公式����,或?qū)﹄x散型變量進行連續(xù)化處理�����,而K-均值聚類要求更嚴格,只能使用連續(xù)型數(shù)據(jù)�,這也需要對離散型數(shù)據(jù)做連續(xù)化處理。
相比傳統(tǒng)層次聚類和K-均值聚類算法����,兩步聚類法占用的計算機內(nèi)存資源更少,能夠用于海量數(shù)據(jù)的處理且運算速度較快�����。
二階聚類能夠根據(jù)AIC和BIC這兩個統(tǒng)計量在不同類別間的變化�,自動確定最佳的聚類數(shù)目,使聚類結(jié)果更為量化�����。
二階聚類的聚類過程分兩步完成�����。第一步是預聚類,在這一步中���,軟件會對記錄(個案)進行初步聚類���,結(jié)果會給出分析者設置的最大分類數(shù);第二步是正式聚類�,這步將對第一步完成的初步聚類進行再聚類并確定最終的聚類方案,確定最終類別數(shù)的標準是AIC或BIC這兩個統(tǒng)計量��。
預聚類過程����;預聚類過程是通過構(gòu)建和修改聚類特征樹來完成的。聚類特征樹可以想象成生活中的樹枝���,葉子是末端���,連接葉子的是葉枝,連接葉枝的是分支��,鏈接分支的是樹干和根部��。聚類特征樹的葉子、葉枝和分支都帶有自己的特征條目���。每一片葉子代表一個子類����,有多少片葉子就有多少個子類�,葉枝和分支的特征條目是用來指引記錄(個案)進入葉片(子類)的,這些特征條目包括連續(xù)變量的均值和方差以及離散型變量的頻數(shù)���。每個記錄都從樹根部進入聚類特征樹��,然后依照分支和葉枝的特征信息指引找到最接近的葉片(子類),如果某個記錄進入到葉片子類中��,那么該葉片的聚類特征將從新計算���;如果記錄最終沒有找到合適的葉片����,那么該記錄就會自己成為一片葉子����。當所有記錄都通過以上方式進入聚類特征樹,預聚類過程結(jié)束,葉片數(shù)量就是預聚類的聚類數(shù)量�。

正式聚類過程;在正式聚類過程�����,將以預聚類的結(jié)果作為輸入���,對其進行再聚類����,直到達成使用者指定的類別�����。因為這個階段所需處理的類別數(shù)已經(jīng)遠小于記錄的數(shù)量���,所以SPSS采用的是傳統(tǒng)的層次聚類法�����。在層次聚類的每個階段�����,SPSS都會計算每個類別的統(tǒng)計量���,AIC或BIC�,這兩個統(tǒng)計量的值越小�,說明聚類的效果越好。二階聚類法最終會根據(jù)AIC和BIC的大小���,以及類間距離來確定最優(yōu)的類別數(shù)量����。
案例分析
上一篇中����,我們介紹了聚類分析在客戶分級管理上的應用���,舉的例子是電信運營商對客戶群體依據(jù)各種情況下的通話時長來對他們進行分類��,發(fā)現(xiàn)不同類別客戶的通話特點���,然后向不同的客戶類型推出不同的套餐服務,提高運營效率����,獲取更高的利潤��。銀行同樣是客戶非常多的企業(yè)����,聚類分析在這個領域的應用很多��,下面的例子將會介紹���。
開始案例分析之前先說個社會熱點事件�����。前段時間�,很多大學女生赤裸身體拿著身份證的照片在網(wǎng)絡上大范圍傳播�����,由此揭開了大學校園里的裸貸黑幕���。很多大學女生向互聯(lián)網(wǎng)金融機構(gòu)借款�,無需抵押和擔保�����,只需赤裸身體,拿著身份證照幾張照片就能貸款成功�,這些貸款的利息非常高,很多女生逾期無法償還本金和利息��,被追債人員拿著裸照威脅父母替她們還錢����,甚至有的追債人威脅女生“肉償”。從下面案例的聚類分析結(jié)果可以知道���,大學生本來就是違約的高風險群體����,這些互聯(lián)網(wǎng)金融機構(gòu)大肆向大學生提供不需信用審核的高利息貸款的行為����,與高利貸無異�����。

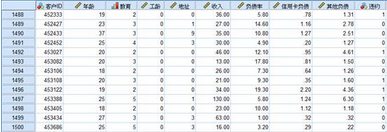
銀行有一套風險評估的模型��,可以對每個客戶進行分類,為每一類客戶打上標簽�。比如你去辦貸款,會先叫你提供一大堆的材料����,采集到你的各種信息以后,將信息放入模型里計算�����,從而確定處在哪個級別���,然后根據(jù)這個級別決定是否給你貸款以及貸款的額度是多少���。信用卡的申辦過程也是如此。當然���,之前中國的信貸業(yè)務曾經(jīng)走過一段多快好省的歲月��,拉著你辦信用卡?�,F(xiàn)在有一份某銀行的1500個客戶的數(shù)據(jù)資料�,記錄了客戶的包括年齡�����、教育程度、工齡���、收入等9個變量信息�����。如下圖所示���,其中有定距變量,也有定類變量�。用二階聚類的方法對這些客戶進行分類。
分析步驟
1���、選擇菜單【分析】-【分類】-【兩步聚類】�,在跳出的對話框中進行如下操作�����,將“教育水平”和“是否曾經(jīng)違約”選入分類變量�����,將其它定距型變量選入連續(xù)變量���;在聚類準側(cè)中選擇BIC����,也可以選擇AIC���。
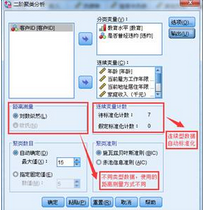
如果只有連續(xù)變量���,距離測量可以使用歐氏距離,也可以使用對數(shù)似然值�����,使用歐式距離和傳統(tǒng)聚類方法的距離測量沒有太大區(qū)別���。如果既有離散變量又有連續(xù)變量���,那么就只能使用對數(shù)似然值來表述個案間的距離了。二階聚類會自動對連續(xù)型變量進行標準化���。聚類數(shù)目可以由軟件自動確定���,也可以由分析者事先指定聚類數(shù)目�。
2��、點擊右上角的【選項】和【輸出】按鈕��。在跳出的對話框中進行如下操作�。選中透視表,能夠在結(jié)果中輸出結(jié)果表格���,否則只能在模型查看器中查看聚類結(jié)果���。選中創(chuàng)建聚類成員變量,聚類結(jié)束后�����,將會新生成一列類別變量��,標明每個個案被歸屬的類別���。
3����、點解確定,輸出結(jié)果�。
結(jié)果解釋
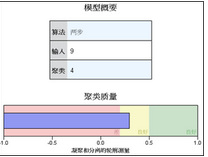
1��、聚類過程表格�����。從后面的表格可以知道����,軟件選擇的最佳聚類數(shù)是6,選擇的依據(jù)可以用聚類過程表格進行說明���。
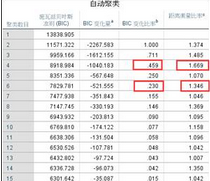
確定最佳類別數(shù)的指標是BIC值��,這個數(shù)值越小代表聚類效果越好�,但這不是唯一的標準���。從結(jié)果可知����,雖然聚類數(shù)達到設定的最大值15時,BIC值最小����,但是BIC值在14類到15類的變化非常小,說明從14類再分成15類意義不大����,因此還需要參考BIC變化量、BIC變化比率這兩個指標����。BIC
變化列的數(shù)據(jù)反映相鄰兩個結(jié)果的BIC值之差,發(fā)現(xiàn)BIC值在聚為4類和6類以后�,BIC值的下降幅度有大幅減少,所以聚為4到6類是比較合理的聚類數(shù)據(jù)�����。距離測量比率表示不同聚類數(shù)目的聚類分析���,兩種結(jié)果的最小類間距離比值�����,比值越大����,說明繼續(xù)分類的意義不大?��?梢园l(fā)現(xiàn)�,距離測量比率的最大值出現(xiàn)在4類��,表示聚成4類的最小類間距離是聚成5類的最小類間距離的1.669倍�,說明5類的最小類間距離太小�,沒有拆分的意義。綜上所述����,軟件選擇4類為最佳聚類數(shù)。
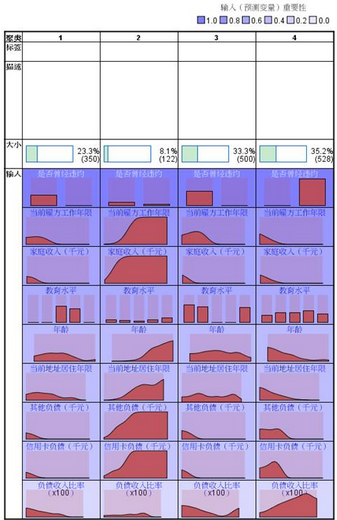
2���、聚類情況���;表明每個類別的聚類數(shù)和比例。
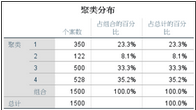
3���、類別的描述統(tǒng)計結(jié)果����;連續(xù)型變量的結(jié)果顯示每個類別的平均值和標準差,分類型數(shù)據(jù)顯示不同類別的頻數(shù)分布���。這些都能夠幫助分析者了解分類結(jié)果的有用性�。限于篇幅�,這里就聚類結(jié)果做過多解釋,如果每個類別的變量特征有顯著性差異��,能夠幫助分析者做制定行動措施����,那么聚類結(jié)果就是有用的。
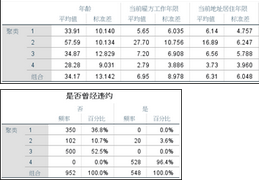
4��、聚類綜合結(jié)果查看器��;鼠標雙擊這兩個圖形區(qū)域�,會跳出結(jié)果查看頁面,里面綜合了各種可視化的聚類結(jié)果����。
5、可視化聚類結(jié)果����;左圖是每個類別包含個案數(shù)和比例的餅圖�;右圖是所有聚類變量在本次聚類分析過程的重要性�,從結(jié)果可知,是否違約這個變量最重要�;
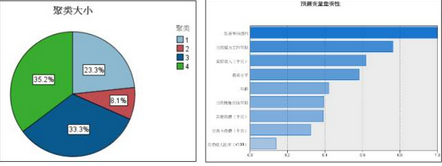
下圖顯示的是每個類別包含個案的描述性統(tǒng)計結(jié)果。以第四個類別為例�,這個類別的客戶基本上都違約了,他們在當前公司的工作時間很短�,家庭收入很低,年齡較小�,在當前居住地的居住年限短,負債數(shù)額不高���,但負債收入比卻很高,以上客戶的特點和裸貸的大學生群體特征很相似��。此外���,這個類別的學歷水平分布很均勻�����,什么學歷的都有�,說明違約與學歷之間沒有直接聯(lián)系。
總結(jié)一下
從以上結(jié)果可以看出�,銀行信貸數(shù)據(jù)能夠很容易得出大學生的還貸違約概率極高,很多互聯(lián)網(wǎng)金融機構(gòu)作“裸貸”業(yè)務����,與沾血的“高利貸”如出一轍。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330