SPSS分析技術(shù):K-均值聚類分析����;個(gè)體工商戶和小型企業(yè)也應(yīng)該做客戶分級管理,提高市場競爭力
K-均值聚類法的聚類算法與層次聚類法完全不同�。在SPSS軟件中�����,K-均值聚類法是按照如下步驟對個(gè)案進(jìn)行聚類的:
分析者需要事先確定類別數(shù)量����。類別數(shù)量由分析者自行指定(方法名稱中的K就是類別數(shù)量的意思)�����。在實(shí)際分析過程中�����,類別數(shù)量一般需要研究者根據(jù)問題���,反復(fù)嘗試把數(shù)據(jù)分成不同的類別數(shù)的效果并進(jìn)行比較���,從中挑選出最優(yōu)的方案。
根據(jù)分析者指定的類別中心(具體坐標(biāo))����,或者SPSS軟件根據(jù)數(shù)據(jù)的結(jié)構(gòu)中心初步確定每個(gè)類別的初始中心坐標(biāo)����,然后逐一計(jì)算每個(gè)個(gè)案(記錄)到各個(gè)類別初始中心的距離���,按照距離最近原則將記錄歸入相應(yīng)類別,并重新計(jì)算類別的中心點(diǎn)(用均值表示����,也就是方法名稱中均值的含義)。
重復(fù)1和2步驟��,直到達(dá)到收斂標(biāo)準(zhǔn)��,或者達(dá)到分析者事先設(shè)定的迭代次數(shù)�����。
從以上算法過程可以了解����,由于事先指定了類別數(shù)和類別中心,K-均值聚類的運(yùn)行速度明顯的快于層次聚類�,這也是其被稱為快速聚類的原因。與層次聚類法相比��,K-均值聚類法的計(jì)算量非常小����,因此可以有效地處理大量數(shù)據(jù)而不占用太多的計(jì)算機(jī)內(nèi)存空間和時(shí)間�。每個(gè)類別的初始類別中心(坐標(biāo)值)可以由分析者自行輸入����,也可以由軟件根據(jù)數(shù)據(jù)結(jié)構(gòu)確定,這樣就能夠幫助分析者借鑒前人的經(jīng)驗(yàn)����,少走彎路,節(jié)約探索時(shí)間���。
因?yàn)镵-均值聚類的依據(jù)是距離�,所以要求納入聚類的變量都為連續(xù)型變量����,并且要求各變量的量綱和數(shù)據(jù)差異盡量一致,這樣聚類的結(jié)果才可靠�,避免量綱小數(shù)值大的變量數(shù)據(jù)在最終距離數(shù)值上權(quán)重過大。K-均值聚類不能像層次聚類一樣在操作菜單中直接對變量進(jìn)行標(biāo)準(zhǔn)化�����,因此在分析前需要用【分析】-【描述統(tǒng)計(jì)】-【描述】功能對連續(xù)變量進(jìn)行標(biāo)準(zhǔn)化。除了要注意變量數(shù)據(jù)的標(biāo)準(zhǔn)化以外���,還需要考慮變量之間的相關(guān)關(guān)系,這是因?yàn)閺?qiáng)相關(guān)的變量如果同時(shí)納入到聚類分析中����,那么這些變量所共同代表的因素權(quán)重就會遠(yuǎn)遠(yuǎn)高于其它變量,并最終使聚類結(jié)果偏向于該因素��。
排排坐講故事
草堂君今天將介紹K-均值聚類分析應(yīng)用于商家的客戶分級管理�,因此在正式介紹SPSS的操作步驟和結(jié)果解釋之前,特別向大家介紹客戶分級管理的相關(guān)背景知識����,以及客戶分級管理在商業(yè)經(jīng)營上的成功典故。數(shù)據(jù)分析是手段����,落地應(yīng)用才是終極目標(biāo)。
互聯(lián)網(wǎng)的普及使得市場信息越來越透明�����,過去靠市場信息不對稱大發(fā)其財(cái)?shù)纳饣旧蠜]有了生存的土壤(除了中國的“股市”)�����,市場的競爭日趨白熱化,企業(yè)或者改變經(jīng)營策略生存下來����,或者坐以待斃等待被市場淘汰?�;谝陨显?,很多企業(yè)都把注意力放在過去被忽略的客戶身上,力求提供優(yōu)質(zhì)的服務(wù)黏住客戶����,將“以客戶為中心”作為口號,在研發(fā)����、設(shè)計(jì)、市場���、銷售��、服務(wù)等各個(gè)環(huán)節(jié)強(qiáng)調(diào)了解客戶需求�����、滿足客戶需要���。但是����,客戶這么多�����,需求也各不一樣����,應(yīng)該以哪個(gè)或哪類客戶為中心呢���?“以客戶為中心”并不是要將每一個(gè)客戶都作為中心����,企業(yè)的人力���、物力和資金都是有限的����,每一分錢都要花在刀刃上,希望用最少的資源獲得最大的回報(bào)�,這就要求把資源投入到最能夠產(chǎn)生價(jià)值的客戶身上?��?蛻羰欠謱哟蔚?,應(yīng)該將具有最大價(jià)值的客戶放在核心的位置��,盡量滿足他們需求���,具有次要價(jià)值的客戶則處于次要位置�����,這就是客戶分級管理的概念��。
美孚公司是世界最大的非政府油氣生產(chǎn)商和世界最大的非政府天然氣銷售商��,同時(shí)也是世界最大的煉油商之一��,在全球擁有數(shù)萬座加油站和數(shù)以百萬計(jì)的工業(yè)和批發(fā)客戶����。1993年����,美孚公司遭遇銷售收入和利潤雙雙下滑�,這讓美孚公司重新審視其核心的汽油零售業(yè)務(wù)�����。產(chǎn)生這種情況的原因主要有兩方面:一方面是存在全球性的石油供給過剩���,石油行業(yè)的競爭越來越激烈���;另一方面是零售加油業(yè)務(wù)的進(jìn)入門檻比較低���,很多大型零售店和連鎖超市以廉價(jià)汽油為賣點(diǎn)�����,吸引顧客光顧他們的店面��,這給石油公司帶來了日益沉重的價(jià)格壓力��。美孚公司認(rèn)識到�,不能與超市和零售店拼低價(jià)��,而應(yīng)該對客戶進(jìn)行分級管理。美孚公司進(jìn)行了非常系統(tǒng)的客戶行為研究���,篩選出以下幾個(gè)關(guān)鍵行為因素:
便利性要求���。是否要求易于找到加油站。
價(jià)格敏感度�����?��?蛻魧τ谟蛢r(jià)的關(guān)注程度和敏感程度��。
額外服務(wù)力���。愿意享受額外服務(wù)的意愿和能力。
根據(jù)這三個(gè)行為因素�����,美孚公司將客戶分為五類不同的客戶群體:
公路勇士���;一般收入較高�,多為中年男子,習(xí)慣長途駕駛���,偏好全面服務(wù)��,駕車時(shí)喜歡吃零食��。
車手一族����;中高收入駕駛者��,偏好特定的品牌�����,有時(shí)也偏好特定的加油站�����,在加油站偏好自助式服務(wù)���;不怎么購買其他物品。
年輕一代���;開快車�、吃美食、有汽車���,多為朝氣蓬勃�����、經(jīng)常駕車的年輕人����。
家庭主義者�;通常是白天接送孩子的家庭主婦。
價(jià)格導(dǎo)向者�����;對價(jià)格敏感�,經(jīng)常被價(jià)格所吸引。
它們在不同的行為因素上的需求級別不同:
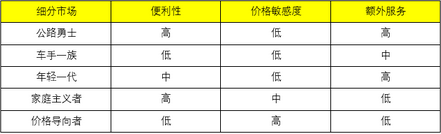
毫無疑問��,美孚公司最主要的目標(biāo)客戶群體是前三類客戶�����。公路勇士、車手一族和年輕一代總計(jì)占到美孚公司客戶總體的接近60%��,但是卻為美孚公司貢獻(xiàn)了86%的利潤�����。這三類客戶都把速度和便利性放在需求的首要位置���,它們有著幾乎一致的服務(wù)要求:快捷的服務(wù)���、能提供幫助的服務(wù)人員,只要這些需求能夠滿足�,他們很樂意為每加侖汽油多付幾個(gè)美分。這對零售加油行業(yè)來說是非?��?捎^的利潤����。通常情況�,零售加油企業(yè)的總收入很高����,但運(yùn)營成本同樣驚人����,每加侖利潤的利潤非常單薄�����,如果考慮到美孚每年要賣出數(shù)十億加侖汽油����,那么所增加的利潤就很可觀了。通過客戶分級研究���,美孚公司發(fā)起了“友好服務(wù)”的品牌活動�����,目的向美孚公司定位的三個(gè)細(xì)分客戶群體提供更友好�����、更潔凈發(fā)��、更安全��、更快速的服務(wù)�����,獲得了利潤的巨大增長����。
由此可見,客戶分級管理是企業(yè)深耕市場��,獲取利潤非常好的手段���??蛻舴旨壒芾碓诂F(xiàn)實(shí)生活中應(yīng)用已經(jīng)非常多了�,例如形形色色的信用卡、會員卡�。信用卡有白金卡、金卡�、普通卡,各種會員卡也常常分金卡會員�����、銀卡會員��,不同級別的卡代表了不同的客戶級別�����,意味著發(fā)卡企業(yè)將會提供不同的服務(wù)��,這些都體現(xiàn)了對客戶進(jìn)行分級管理的思想�。不同的行業(yè)需要關(guān)注的客戶行為因素也不一樣。當(dāng)需要考慮的因素很多時(shí)��,以上簡單的分級方法就行不通了�����,聚類分析就能夠解決這樣的問題�。
案例分析
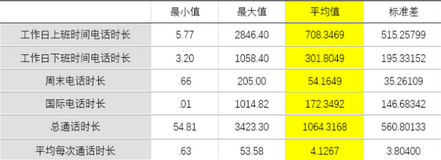
某通信運(yùn)營商為了提升業(yè)績,計(jì)劃實(shí)施客戶分級管理措施����。根據(jù)前期的調(diào)研,認(rèn)為他們的客戶應(yīng)該被分為5個(gè)主要群體�����。公司重點(diǎn)關(guān)注客戶的六個(gè)行為因素:工作日上班時(shí)間通過時(shí)長�、工作日下班時(shí)間通話時(shí)長�、周末通話時(shí)長�����、國際電話時(shí)長和總通話時(shí)長����。隨機(jī)從數(shù)據(jù)庫中選取了3395條記錄,數(shù)據(jù)如下圖所示:
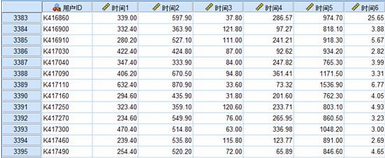
分析思路
根據(jù)前期調(diào)研��,客戶群體應(yīng)該被分為5個(gè)主要類別����,數(shù)據(jù)類型都是連續(xù)型數(shù)據(jù),數(shù)據(jù)量達(dá)到3395條����,因此可以使用K-均值聚類來對這些客戶進(jìn)行分類,然后通過描述性統(tǒng)計(jì)結(jié)果來對每個(gè)類型的客戶進(jìn)行精準(zhǔn)服務(wù)�。對六個(gè)行為因素的數(shù)據(jù)情況進(jìn)行探索性分析,可以得到下面的兩個(gè)結(jié)果:
1�����、工作日上班時(shí)間電話時(shí)長與總通話時(shí)長之間具有線性相關(guān)關(guān)系�����,因此需要對它們進(jìn)行處理,可以用工作日上班時(shí)間電話時(shí)長/總通話時(shí)長作為處理����。
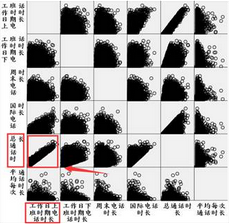
2��、雖然六個(gè)行為因素的單位都是分鐘���,但是數(shù)據(jù)級別差異還是比較大的���,因此需要首先對這六個(gè)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化,可以通過【分析】-【描述統(tǒng)計(jì)】-【描述】實(shí)現(xiàn)���。
分析步驟
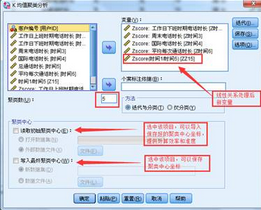
1���、選擇菜單【分析】-【分類】-【K-均值】,在跳出的對話框中進(jìn)行如下操作�,將標(biāo)準(zhǔn)化后的5個(gè)變量選入變量框中,聚類數(shù)填寫5��,其它保持默認(rèn)狀態(tài)��。
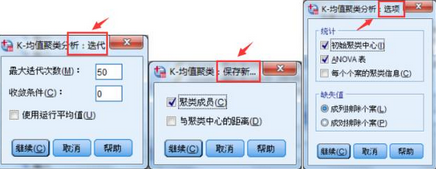
2、分別點(diǎn)擊【迭代】��、【保存】和【選項(xiàng)】按鈕�����,然后依據(jù)實(shí)際需要選中項(xiàng)目�。下圖是聚類分析最基本的幾個(gè)結(jié)果選項(xiàng)。
3�����、點(diǎn)擊確定����,輸出結(jié)果。
結(jié)果解釋
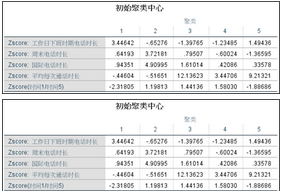
1��、初始聚類中心和最終聚類中心��。這兩個(gè)表格顯示了K-均值聚類的最初聚類中心和最終聚類中心的坐標(biāo)值���。
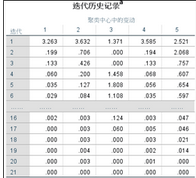
2���、迭代歷史��。結(jié)果顯示���,數(shù)據(jù)經(jīng)過21次迭代計(jì)算后,聚類中心收斂�,聚類結(jié)束。
3�、方差分析結(jié)果����;從方差分析結(jié)果可知,形成的5個(gè)客戶類別�,它們在5個(gè)行為因素上的顯著性小于0.05,都是有顯著性差異的�,說明聚類效果不錯。

4�����、每個(gè)類別的個(gè)案數(shù)����。一般來說,聚類結(jié)果盡量使每類的個(gè)案數(shù)比較接近����,但是這個(gè)也不是一個(gè)絕對的標(biāo)準(zhǔn)�����,如果沒有考慮異常值時(shí)�,有的類別的個(gè)案數(shù)就比較少��。

5�����、五類客戶的行為因素特征描述���;
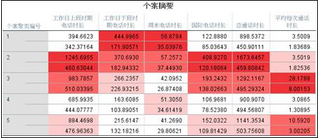
第一類客戶的下班和周末通話時(shí)間最長�,這類客戶共有1147人����。第二類客戶的所有通話時(shí)間都很長的優(yōu)質(zhì)客戶,這類客戶共有628人����。第三類客戶的所有通話時(shí)間都處于中上水平,這類客戶共有42人。第四類客戶的所有通話時(shí)間都較短的客戶����,這類客戶共有1346人。第五類客戶的所有通話時(shí)間都處于中下水平���,這類客戶共有232人��。根據(jù)每類客戶的行為特性不同����,可以退出針對他們的套餐服務(wù)�����,這樣就能做到客戶的分級管理����,優(yōu)化運(yùn)營效率��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330