基于R語言利用QQ群進(jìn)行數(shù)據(jù)挖掘案例整理
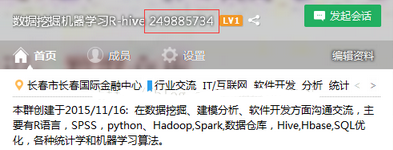
利用QQ群進(jìn)行數(shù)據(jù)挖掘案例����,數(shù)據(jù)源來源于2016年12-2017年大致一個月的QQ群基本數(shù)據(jù),通過對聊天內(nèi)容的分析,了解QQ聊天群資料了解時間����,人群以及關(guān)鍵詞,并構(gòu)建相應(yīng)圖表��、云圖等����,下圖為本人所在提取的QQ群:
以下是R代碼部分:
file.data<-scan("C:/Users/admin/Desktop/數(shù)據(jù)挖掘機器學(xué)習(xí)R-Hive.txt",what="",sep="\n",encoding="UTF-8")

#數(shù)據(jù)清洗
clean<-function(file.data){
data<-data.frame(user.name=c(),time=c(),text=c())
user.name=c();time=c();text=c();
for(i in 6:length(file.data))
{
reg.time<-regexpr("[0-9]{4}-[0-9]{2}-[0-9]{2}[0-9]+:[0-9]+:[0-9]+",file.data[i])
if(reg.time==1){#該行取到了時間信息
data<-rbind(data,data.frame(user.name=user.name,time=time,text=text))
text=c("1")
begin<-reg.time
end<-reg.time+attr(reg.time,"match.length")-1
time=substr(file.data[i],begin,end)
begin=reg.time+attr(reg.time,"match.length")+1
end<-nchar(file.data[i])
user.name<-substr(file.data[i],begin,end)#讀取用戶名信息
}
else{text=paste(text,file.data[i])}
}
return(data)}
data<-clean(file.data)#數(shù)據(jù)結(jié)構(gòu)化

#活躍度計算
d1=table(data[,1])>d = data.frame(word = names(d1),freq = d1,stringsAsFactors = F) ;>d=d[order(d[,3],decreasing=T),]
#由于測試群記錄數(shù)據(jù)量�����,后期效果不是很明顯���。這也是大數(shù)據(jù)火的原因吧����?
>dim(d1)[1] 29>length(data[,1])[1] 164#轉(zhuǎn)換數(shù)據(jù)類型data$name<-as.character(data$user.name)data$text<-as.character(data$text)data$datatime<-as.POSIXlt(data$time)#整理賬期的年����、月、日���、時���、分�、秒部分
> data <- transform(data,
+ year = datatime$year+1900,
+ month = datatime$mon+1,
+ day = datatime$mday,
+ hour = datatime$hour,
+ min = datatime$min,
+ sec = datatime$sec)
>

> d1=table(data[,1])
> d = data.frame(word = names(d1),freq =d1,stringsAsFactors = F) ;
> d=d[order(d[,3],decreasing=T),]
> head(d)
# 活躍度統(tǒng)計

#去掉停用詞
mixseg = worker()
textt=paste(as.character(data[,3]),sep="",collapse ="")
textt<-mixseg<=textt
t=unlist(textt)
cnword<-read.csv("C:/Users/admin/Desktop/幾個停用詞.txt",header=F,stringsAsFactors=F)
cnword<-as.vector(cnword[1:dim(cnword)[1],])#需要為向量格式
t=t[!t%in%cnword]#去停用詞
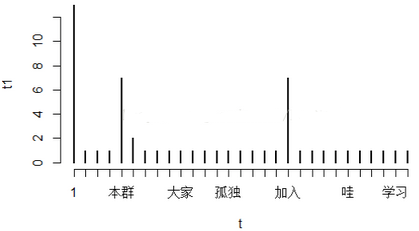
t1=table( t )
plot(t1) 初步查看分詞不是很理想�,繼續(xù)調(diào)整
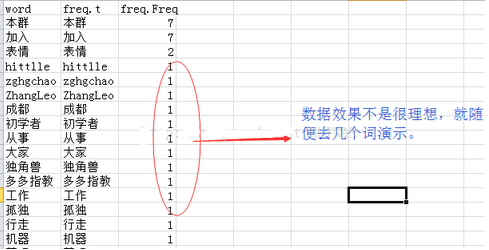
> d1=t1
> d =data.frame(word = names(d1),freq = d1,stringsAsFactors = F) ;
>d=d[order(d[,3],decreasing=T),]
>d=d[nchar(as.character(d$word))>1,]
>write.table(d,"C:/Users/admin/Desktop/幾個停用詞.txt聊天內(nèi)容詞頻排名.csv",sep=",",row.names
= F)
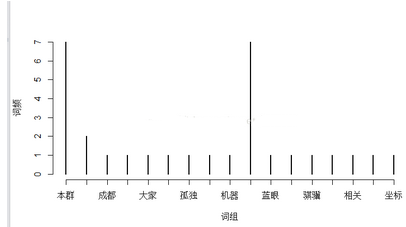
t1=table( t )
>t1=t1[!names(t1)%in%c("男神","女神","你懂的")]#去沒有意義的詞
> library(Rwordseg)
t1=t1[nchar(as.character(names(t1)))==2]
plot(t1,xlab="詞組",ylab="詞頻") #效果實例而已,好的數(shù)據(jù)會有好的效果����。
---------用wordcloud進(jìn)行過程-------------------------------------
#分詞后的詞語頻率匯總
> wdfreq <- as.data.frame(table(t1))
> head(wdfreq)
t1Freq
1 1 14
2 2 1
3 7 2
#頻數(shù)排序 **
wdfreq<-rev(sort(wdfreq$Freq))
------------------------------------------------------
#使用wordcloud2構(gòu)造云圖
wordcloud2(t1,size=2,fontFamily='SegoeUI')
---------用wordcloud進(jìn)行過程-------------------------------------
#分詞后的詞語頻率匯總
> wdfreq <- as.data.frame(table(t1))
> head(wdfreq)
t1Freq
1 1 14
2 2 1
3 7 2
#頻數(shù)排序 **
wdfreq<-rev(sort(wdfreq$Freq))
------------------------------------------------------
#使用wordcloud2構(gòu)造云圖
wordcloud2(t1,size=2,fontFamily='SegoeUI')

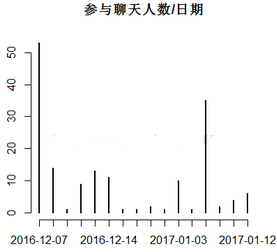
> datax=substr(data[,2],1,10)#得到日期,不要時分秒
> a=table(datax)
> plot(a,xlab="日期",ylab="頻數(shù)",main="參與聊天人數(shù)/日期")
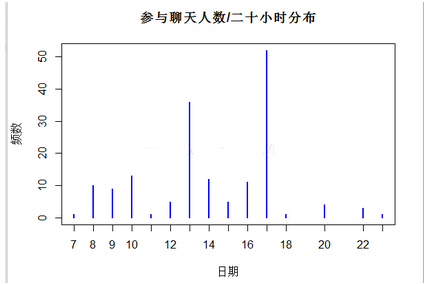
data1=data.frame(user.name=data[,1],data=substr(data[,2],1,10),time=substr(data[,2],12,regexpr(":",data[,2])-1),text=data[,3])
#write.table(data1," C:/Users/admin/Desktop/.細(xì)分?jǐn)?shù)據(jù).csv",sep=",",row.names = F)
a=table(data1[,3])
plot(a,xlab="日期",ylab="頻數(shù)",col=4,main="參與聊天人數(shù)/二十小時分布")
WORDCLOUD2常用參數(shù):
(1)data:詞云生成數(shù)據(jù)����,包含具體詞語以及頻率;
(2)size:字體大小�,默認(rèn)為1,一般來說該值越小�����,生成的形狀輪廓越明顯���;
(3)fontFamily:字體�,如‘微軟雅黑’�;
(4)fontWeight:字體粗細(xì)���,包含‘normal’,‘bold’以及‘600’�;;
(5)color:字體顏色,可以選擇‘random-dark’以及‘random-light’,其實就是顏色色系�����;
(6)backgroundColor:背景顏色�����,支持R語言中的常用顏色��,如‘gray’���,‘blcak’,但是還支持不了更加具體的顏色選擇�����,如‘gray20’�;
(7)minRontatin與maxRontatin:字體旋轉(zhuǎn)角度范圍的最小值以及最大值,選定后����,字體會在該范圍內(nèi)隨機旋轉(zhuǎn)��;
(8)rotationRation:字體旋轉(zhuǎn)比例�,如設(shè)定為1��,則全部詞語都會發(fā)生旋轉(zhuǎn)�����;
(9)shape:詞云形狀選擇��,默認(rèn)是‘circle’��,即圓形�����。還可以選擇‘cardioid’(蘋果形或心形)���,‘star’(星形)���,‘diamond’(鉆石),‘triangle-forward’(三角形)��,‘triangle’(三角形),‘pentagon’(五邊形)����;
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330