R之KNN算法
KNN(k-Nearest Neighbor)分類(lèi)算法是數(shù)據(jù)挖掘分類(lèi)技術(shù)中較簡(jiǎn)單的方法之一���。所謂k最近鄰,就是k個(gè)最近的鄰居的意思���,說(shuō)的是每個(gè)樣本都可以用它最接近的k個(gè)鄰居來(lái)代表。
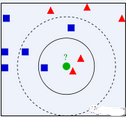
例如��,上圖中��,綠色圓要被決定賦予哪個(gè)類(lèi)����,是紅色三角形還是藍(lán)色四方形?如果K=3�,由于紅色三角形所占比例為2/3,綠色圓將被賦予紅色三角形那個(gè)類(lèi)�,如果K=5,由于藍(lán)色四方形比例為3/5��,因此綠色圓被賦予藍(lán)色四方形類(lèi)�。
KNN分類(lèi)算法�����,是一個(gè)理論上比較成熟的方法���,也是較簡(jiǎn)單的機(jī)器學(xué)習(xí)算法之一。該方法的思路是:如果一個(gè)樣本在特征空間中的k個(gè)最相似(即特征空間中最鄰近)的樣本中的大多數(shù)屬于某一個(gè)類(lèi)別���,則該樣本也屬于這個(gè)類(lèi)別�。KNN算法中��,所選擇的鄰居都是已經(jīng)正確分類(lèi)的對(duì)象�����。該方法在定類(lèi)決策上只依據(jù)最鄰近的一個(gè)或者幾個(gè)樣本的類(lèi)別來(lái)決定待分樣本所屬的類(lèi)別���。
KNN方法雖然從原理上也依賴于極限定理�����,但在類(lèi)別決策時(shí)���,只與極少量的相鄰樣本有關(guān)���。由于KNN方法主要靠周?chē)邢薜泥徑臉颖荆皇强颗袆e類(lèi)域的方法來(lái)確定所屬類(lèi)別的����,因此對(duì)于類(lèi)域的交叉或重疊較多的待分樣本集來(lái)說(shuō),KNN方法較其他方法更為適合���。
KNN算法不僅可以用于分類(lèi)����,還可以用于回歸�����。通過(guò)找出一個(gè)樣本的k個(gè)最近鄰居��,將這些鄰居的屬性的平均值賦給該樣本���,就可以得到該樣本的屬性。更有用的方法是將不同距離的鄰居對(duì)該樣本產(chǎn)生的影響給予不同的權(quán)值(weight)���,如權(quán)值與距離成反比�����。
KNN算法流程:
1. 準(zhǔn)備數(shù)據(jù)���,對(duì)數(shù)據(jù)進(jìn)行預(yù)處理
2. 選用合適的數(shù)據(jù)結(jié)構(gòu)存儲(chǔ)訓(xùn)練數(shù)據(jù)和測(cè)試元組
3. 設(shè)定參數(shù)����,如k
4. 維護(hù)一個(gè)大小為k的的按距離由大到小的優(yōu)先級(jí)隊(duì)列����,用于存儲(chǔ)最近鄰訓(xùn)練元組。隨機(jī)從訓(xùn)練元組中選取k個(gè)元組作為初始的最近鄰元組���,分別計(jì)算測(cè)試元組到這k個(gè)元組的距離���,將訓(xùn)練元組標(biāo)號(hào)和距離存入優(yōu)先級(jí)隊(duì)列
5. 遍歷訓(xùn)練元組集,計(jì)算當(dāng)前訓(xùn)練元組與測(cè)試元組的距離����,將所得距離L與優(yōu)先級(jí)隊(duì)列中的最大距離Lmax
6. 進(jìn)行比較。若L>=Lmax����,則舍棄該元組�,遍歷下一個(gè)元組��。若L < Lmax�����,刪除優(yōu)先級(jí)隊(duì)列中最大距離的元組��,將當(dāng)前訓(xùn)練元組存入優(yōu)先級(jí)隊(duì)列�����。
7. 遍歷完畢��,計(jì)算優(yōu)先級(jí)隊(duì)列中k個(gè)元組的多數(shù)類(lèi)�����,并將其作為測(cè)試元組的類(lèi)別�����。
8. 測(cè)試元組集測(cè)試完畢后計(jì)算誤差率����,繼續(xù)設(shè)定不同的k值重新進(jìn)行訓(xùn)練,最后取誤差率最小的k值�����。
KNN算法優(yōu)點(diǎn):
1. 簡(jiǎn)單�����,易于理解����,易于實(shí)現(xiàn),無(wú)需估計(jì)參數(shù)����,無(wú)需訓(xùn)練;
2. 適合對(duì)稀有事件進(jìn)行分類(lèi)����;
3. 特別適合于多分類(lèi)問(wèn)題(multi-modal,對(duì)象具有多個(gè)類(lèi)別標(biāo)簽),kNN比SVM的表現(xiàn)要好�����;
KNN算法缺點(diǎn):
1.
當(dāng)樣本不平衡時(shí),如一個(gè)類(lèi)的樣本容量很大���,而其他類(lèi)樣本容量很小時(shí)����,有可能導(dǎo)致當(dāng)輸入一個(gè)新樣本時(shí)��,該樣本的K個(gè)鄰居中大容量類(lèi)的樣本占多數(shù)�����。
該算法只計(jì)算“最近的”鄰居樣本����,某一類(lèi)的樣本數(shù)量很大,那么或者這類(lèi)樣本并不接近目標(biāo)樣本��,或者這類(lèi)樣本很靠近目標(biāo)樣本�。無(wú)論怎樣,數(shù)量并不能影響運(yùn)行結(jié)果�����;
2. 計(jì)算量較大���,因?yàn)閷?duì)每一個(gè)待分類(lèi)的文本都要計(jì)算它到全體已知樣本的距離���,才能求得它的K個(gè)最近鄰點(diǎn);
3. 可理解性差�,無(wú)法給出像決策樹(shù)那樣的規(guī)則;
R語(yǔ)言中有kknn的package實(shí)現(xiàn)了weighted k-nearest neighbor����,用法如下:
kknn(formula
= formula(train), train, test, na.action = na.omit(), k = 7, distance =
2, kernel = "optimal", ykernel = NULL, scale=TRUE, contrasts =
c('unordered' = "contr.dummy", ordered = "contr.ordinal"))
參數(shù):
formula A formula object.
train Matrix or data frame of training set cases.
test Matrix or data frame of test set cases.
na.action A function which indicates what should happen when the data contain ’NA’s.
k Number of neighbors considered.
distance Parameter of Minkowski distance.
kernel Kernel to use. Possible choices are
"rectangular" (which is standard unweighted knn),
"triangular",
"epanechnikov" (or beta(2,2)),
"biweight" (or beta(3,3)),
"triweight" (or beta(4,4)),
"cos",
"inv",
"gaussian",
"rank"
"optimal".
ykernel Window width of an y-kernel, especially for prediction of ordinal classes.
scale Logical, scale variable to have equal sd.
contrasts A vector containing the 'unordered' and 'ordered' contrasts to use
kknn的返回值如下:
fitted.values Vector of predictions.
CL Matrix of classes of the k nearest neighbors.
W Matrix of weights of the k nearest neighbors.
D Matrix of distances of the k nearest neighbors.
C Matrix of indices of the k nearest neighbors.
prob Matrix of predicted class probabilities.
response Type of response variable, one of continuous, nominal or ordinal.
distance Parameter of Minkowski distance.
call The matched call.
terms The 'terms' object used.
class包中的knn()函數(shù)提供了一個(gè)標(biāo)準(zhǔn)的kNN算法實(shí)現(xiàn),用法如下:
knn(train, test, cl, k = 1, l = 0, prob = FALSE, use.all = TRUE)
參數(shù):
train matrix or data frame of training set cases.
test matrix or data frame of test set cases. A vector will be interpreted as a row vector for a single case.
cl factor of true classifications of training set
k number of neighbours considered.
l minimum
vote for definite decision, otherwise doubt. (More precisely, less than
k-l dissenting votes are allowed, even if k is increased by ties.)
prob If this is true, the proportion of the votes for the winning class are returned as attribute prob.
use.all controls
handling of ties. If true, all distances equal to the kth largest are
included. If false, a random selection of distances equal to the kth is
chosen to use exactly k neighbours.
kknn的返回值如下:
Factor of classifications of test set. doubt will be returned as NA.
實(shí)例1:
> library(kknn)
> data(iris)
> m <- dim(iris)[1]
> val <- sample(1:m, size = round(m/3), replace = FALSE, prob = rep(1/m, m)) # 選取采樣數(shù)據(jù)
> iris.learn <- iris[-val,] # 建立訓(xùn)練數(shù)據(jù)
> iris.valid <- iris[val,] # 建立測(cè)試數(shù)據(jù)
# 調(diào)用kknn�����,formula Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width
> iris.kknn <- kknn(Species~., iris.learn, iris.valid, distance = 1, kernel = "triangular")
> summary(iris.kknn)
> fit <- fitted(iris.kknn) # 獲取fitted.values
> table(iris.valid$Species, fit) # 建立表格檢驗(yàn)判類(lèi)準(zhǔn)確性

> pcol <- as.character(as.numeric(iris.valid$Species))
> pairs(iris.valid[1:4], pch = pcol, col = c("green3", "red")[(iris.valid$Species != fit)+1])
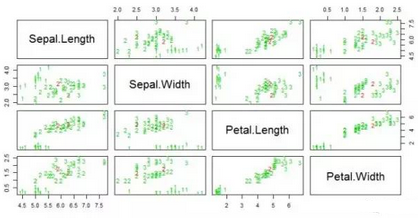
實(shí)例2:
使用UCI機(jī)器學(xué)習(xí)數(shù)據(jù)倉(cāng)庫(kù)(UCI
Machine Learning Repository)的“威斯康星乳腺癌診斷”(Breast Cancer Wisconsin
Diagnostic)的數(shù)據(jù)集�,該數(shù)據(jù)集可以從網(wǎng)站https://archive.ics.uci.edu/ml/獲得。乳腺癌數(shù)據(jù)包括569例細(xì)胞活檢案例�,每個(gè)案例32個(gè)特征。
0. 準(zhǔn)備數(shù)據(jù)
> wbcd<-read.csv('wdbc.data',stringsAsFactors = FALSE)
> str(wbcd)
> wbcd<-wbcd[-1]
> table(wbcd$diagnosis)
> wbcd$diagnosis<-factor(wbcd$diagnosis,levels=c('B','M'),labels=c('Begin','Malignant'))
> round(prop.table(table(wbcd$diagnosis))*100, digits=1)
1. 轉(zhuǎn)換-min-max標(biāo)準(zhǔn)化數(shù)值型數(shù)據(jù)
> normalize <-function(x){
+ return( (x-min(x)) / (max(x)-min(x)) )
+ }
> wbcd_n <-as.data.frame(lapply(wbcd[2:31],normalize))
> #summary(wbcd_n$mqj1)
2. 數(shù)據(jù)準(zhǔn)備-創(chuàng)建訓(xùn)練集和測(cè)試集
> wbcd_train <- wbcd_n[1:469,]
> wbcd_test <- wbcd_n[470:569,]
> wbcd_train_labels <- wbcd[1:469,1]
> wbcd_test_labels <- wbcd[470:569,1]
3. 訓(xùn)練模型
> install.packages('class')
> library(class)
> wbcd_test_pred <-knn(train=wbcd_train, test=wbcd_test, cl=wbcd_train_labels, k=21)
4. 評(píng)估性能
> install.packages('gmodels')
> library(gmodels)
> CrossTable(x=wbcd_test_labels, y=wbcd_test_pred, prop.chisq = FALSE)
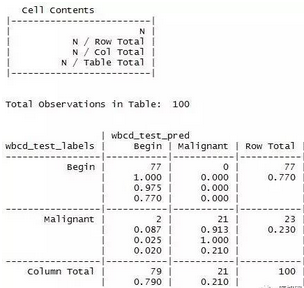
5. 提高模型的性能
5.1 Z-score標(biāo)準(zhǔn)化
> wbcd_z <-as.data.frame(scale(wbcd[-1]))
> wbcd_train <- wbcd_z[1:469,]
> wbcd_test <- wbcd_z[470:569,]
> wbcd_train_labels <- wbcd[1:469,1]
> wbcd_test_labels <- wbcd[470:569,1]
> wbcd_test_pred <-knn(train=wbcd_train, test=wbcd_test, cl=wbcd_train_labels, k=21)
> CrossTable(x=wbcd_test_labels, y=wbcd_test_pred, prop.chisq = FALSE)
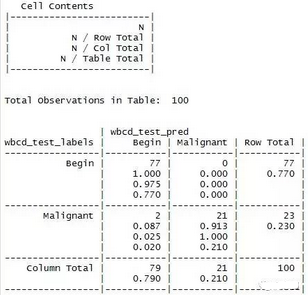
5.2 測(cè)試其他的K值
變換K的大小��,測(cè)試假陰性和假陽(yáng)性����。盡量避免假陰性,但是會(huì)以增加假陽(yáng)性代價(jià)����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330