SPSS統(tǒng)計基礎(chǔ)-單因素方差分析功能的使用
“單因素ANOVA”過程按照單因子變量(自變量)生成對定量因變量的單因素方差分析。方差分析用于檢驗數(shù)個均值相等的假設(shè)����。這種方法是雙樣本t 檢驗的擴(kuò)展�。除了確定均值間存在著差值外����,您可能還想知道哪些均值之間存在著差值。比較均值有兩類檢驗方法:先驗對比和兩兩比較檢驗���。對比是在試驗開始前進(jìn)行的檢驗��,而兩兩比較檢驗則是在試驗結(jié)束后進(jìn)行的��。您也可以檢驗各個類別的趨勢��。
示例����。炸面包圈在烹制過程中吸收的脂肪量各不相同���。我們設(shè)計了一個涉及三種脂肪的實驗:花生油、玉米油和豬油�����。花生油和玉米油是不飽和脂肪�,而豬油是飽和脂肪。除了確定吸收的脂肪量是否因使用的脂肪類型而異外��,您還可以建立一個先驗對比�����,確定吸收的脂肪量是否也因飽和脂肪和不飽和脂肪而異�。
統(tǒng)計量。對于每個組:個案數(shù)�����、均值����、標(biāo)準(zhǔn)差、均值的標(biāo)準(zhǔn)誤�、最小值、最大值和均值的95% 置信區(qū)間���。Levene 的方差齊性檢驗����、每個因變量的方差分析表和均值相等的穩(wěn)健測試、用戶指定的先驗對比以及兩兩比較范圍檢驗和多重比較:Bonferroni�、Sidak、Tukey’s 真實顯著性差異�、Hochberg’s GT2、Gabriel�����、Dunnett�����、Ryan-Einot-Gabriel-Welsch F 檢驗(R-E-G-W F)���、Ryan-Einot-Gabriel-Welsch 范圍檢驗(R-E-G-W Q)����、Tamhane’s T2�、Dunnett’s T3、Games-Howell�����、Dunnett’s C���、Duncan 的多范圍檢驗�����、Student-Newman-Keuls (S-N-K)�、Tukey 的b����、Waller-Duncan、Scheffé 和最小顯著性差異���。
數(shù)據(jù)���。因子變量值應(yīng)為整數(shù),而因變量應(yīng)為定量變量(區(qū)間測量級別)���。
假設(shè)�。每個組是來自正態(tài)總體的獨立隨機(jī)樣本�����。盡管數(shù)據(jù)應(yīng)對稱�����,但方差分析對于偏離正態(tài)性是穩(wěn)健的。各組應(yīng)來自方差相等的總體��。為了檢驗這種假設(shè)��,請使用Levene的方差齊性檢驗���。
獲取單因素方差分析
從菜單中選擇:
分析> 比較均值> 單因素ANOVA...
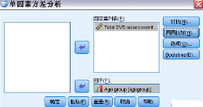
選擇一個或多個因變量��。
選擇一個自變量因子變量����。
單因素ANOVA:對比
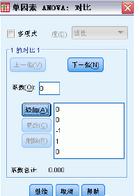
您可以將組間平方和劃分成趨勢成分��,或者指定先驗對比��。
多項式�����。將組間平方和劃分成趨勢成分�����。可以檢驗因變量在因子變量的各順序水平間的趨勢���。例如,您可以檢驗各個順序級別的最高工資水平間的線性趨勢(上升或下降)�。
.度?�?梢赃x擇1 度�、2 度、3 度�、4 度或5 度多項式。
系數(shù)���。用戶指定的用t 統(tǒng)計量檢驗的先驗對比���。為因子變量的每個組(類別)輸入一個系數(shù),每次輸入后單擊添加�����。每個新值都添加到系數(shù)列表的底部���。要指定其他對比組����,請單擊下一個。用下一個和上一個在各組對比間移動���。
系數(shù)的順序很重要���,因為該順序與因子變量的類別值的升序相對應(yīng)。列表中的第一個系數(shù)與因子變量的最低組值相對應(yīng)�����,而最后一個系數(shù)與最高值相對應(yīng)�����。例如���,如果有六類因子變量��,系數(shù)–1�、0�����、0、0���、0.5 和0.5 將第一組與第五和第六組進(jìn)行對比�����。對于大多數(shù)應(yīng)用程序而言,各系數(shù)的和應(yīng)為0�。系數(shù)和不是0 的集也可以使用,但是會出現(xiàn)一條警告消息��。
單因素ANOVA:兩兩比較檢驗
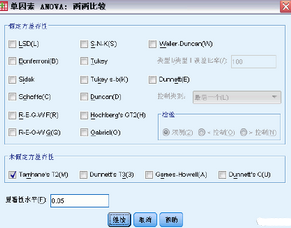
一旦確定均值間存在差值��,兩兩范圍檢驗和成對多重比較就可以確定哪些均值存在差值了�。范圍檢驗識別彼此間沒有差值的同類均值子集。成對多重比較檢驗每一對均值之間的差分���,并得出一個矩陣�,其中星號指示在0.05 的alpha 水平上的組均值明顯不同��。
假定方差齊性
Tukey’s 真實顯著性差異檢驗����、Hochberg’s GT2���、Gabriel 和Scheffé 是多重比較檢驗和范圍檢驗。其他可用的范圍檢驗為Tukey 的b����、S-N-K (Student-Newman-Keuls)、Duncan�����、R-E-G-W F(Ryan-Einot-Gabriel-Welsch F 檢驗)����、R-E-G-W Q(Ryan-Einot-Gabriel-Welsch 范圍檢驗)和Waller-Duncan?����?捎玫亩嘀乇容^檢驗為Bonferroni�、Tukey’s 真實顯著性差異檢驗、Sidak�、Gabriel、Hochberg��、Dunnett、Scheffé 和LSD(最小顯著性差異)�����。
.LSD. 使用t 檢驗執(zhí)行組均值之間的所有成對比較����。對多個比較的誤差率不做調(diào)整。
. Bonferroni.使用t 檢驗在組均值之間執(zhí)行成對比較��,但通過將每次檢驗的錯誤率設(shè)置為實驗性質(zhì)的錯誤率除以檢驗總數(shù)來控制總體誤差率��。這樣���,根據(jù)進(jìn)行多個比較的實情對觀察的顯著性水平進(jìn)行調(diào)整。
.Sidak. 基于t 統(tǒng)計量的成對多重比較檢驗����。Sidak 調(diào)整多重比較的顯著性水平,并提供比Bonferroni 更嚴(yán)密的邊界����。
. Scheffe. 為均值的所有可能的成對組合執(zhí)行并發(fā)的聯(lián)合成對比較。使用F 取樣分布�?��?捎脕頇z查組均值的所有可能的線性組合,而非僅限于成對組合���。
. R-E-G-W F. 基于F 檢驗的Ryan-Einot-Gabriel-Welsch 多步進(jìn)過程���。
. R-E-G-W Q. 基于學(xué)生化范圍的Ryan-Einot-Gabriel-Welsch 多步進(jìn)過程。
S-N-K. 使用學(xué)生化的范圍分布在均值之間進(jìn)行所有成對比較���。它還使用步進(jìn)式過程比較具有相同樣本大小的同類子集內(nèi)的均值對�。均值按從高到低排序�,首先檢驗極端差分。
.Tukey. 使用學(xué)生化的范圍統(tǒng)計量進(jìn)行組間所有成對比較���。將試驗誤差率設(shè)置為所有成對比較的集合的誤差率�����。
.Tukey 的b. 使用學(xué)生化的范圍分布在組之間進(jìn)行成對比較�。臨界值是Tukey's 真實顯著性差異檢驗的對應(yīng)值與Student-Newman-Keuls 的平均數(shù)����。
.Duncan. 使用與Student-Newman-Keuls 檢驗所使用的完全一樣的逐步順序成對比較���,但要為檢驗的集合的錯誤率設(shè)置保護(hù)水平,而不是為單個檢驗的錯誤率設(shè)置保護(hù)水平��。使用學(xué)生化的范圍統(tǒng)計量���。
.Hochberg 的GT2. 使用學(xué)生化最大模數(shù)的多重比較和范圍檢驗����。與Tukey's 真實顯著性差異檢驗相似���。
. Gabriel. 使用學(xué)生化最大模數(shù)的成對比較檢驗�,并且當(dāng)單元格大小不相等時�,它通常比Hochberg's GT2 更為強(qiáng)大。當(dāng)單元大小變化過大時���,Gabriel 檢驗可能
會變得隨意。
.Waller-Duncan. 基于t 統(tǒng)計的多比較檢驗�;使用Bayesian 方法。
.Dunnett. 將一組處理與單個控制均值進(jìn)行比較的成對多重比較t 檢驗��。最后一
類是缺省的控制類別����。另外�����,您還可以選擇第一個類別���。雙面檢驗任何水平(除了控制類別外)的因子的均值是否不等于控制類別的均值。<控制檢驗任何水平的因子的均值是否小于控制類別的均值��。> 控制檢驗任何水平的因子的均值是否大于控制類別的均值�����。
未假定方差齊性
不假設(shè)方差相等的多重比較檢驗有Tamhane 的T2�、Dunnett 的T3、Games-Howell和Dunnett 的C���。
Tamhane 的T2. 基于t 檢驗的保守成對比較�。當(dāng)方差不相等時�,適合使用此檢驗。
Dunnett 的T3. 基于學(xué)生化最大值模數(shù)的成對比較檢驗���。當(dāng)方差不相等時���,適合使用此檢驗��。
Games-Howell. 有時會變得隨意的成對比較檢驗�。當(dāng)方差不相等時�,適合使用此檢驗。
Dunnett 的C. 基于學(xué)生化范圍的成對比較檢驗��。當(dāng)方差不相等時�����,適合使用此檢驗����。
單因素ANOVA:選項
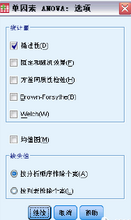
統(tǒng)計量。選擇下列各項的一個或多個:
描述性��。計算每組中每個因變量的個案數(shù)���、均值、標(biāo)準(zhǔn)差�����、均值的標(biāo)準(zhǔn)誤、最小值���、最大值和95% 置信區(qū)間�����。
固定和隨機(jī)效果�����。顯示固定效應(yīng)模型的標(biāo)準(zhǔn)差���、標(biāo)準(zhǔn)誤和95% 置信區(qū)間,以及隨機(jī)效應(yīng)模型的標(biāo)準(zhǔn)誤���、95% 置信區(qū)間和成分間方差估計��。
方差同質(zhì)性檢驗��。計算Levene 統(tǒng)計量以檢驗組方差是否相等�。該檢驗獨立于
正態(tài)的假設(shè)��。
Brown-Forsythe。計算Brown-Forsythe 統(tǒng)計量以檢驗組均值是否相等�����。當(dāng)方差相等的假設(shè)不成立時��,這種統(tǒng)計量優(yōu)于F 統(tǒng)計量�����。
Welch���。計算Welch 統(tǒng)計量以檢驗組均值是否相等���。當(dāng)方差相等的假設(shè)不成立時,這種統(tǒng)計量優(yōu)于F 統(tǒng)計量���。
均值圖�。顯示一個繪制子組均值的圖表(每組的均值由因子變量的值定義)��。
缺失值�����。控制對缺失值的處理�。
按分析順序排除個案��。給定分析中的因變量或因子變量有缺失值的個案不用于該分析�����。而且����,也不使用超出為因子變量指定的范圍的個案。
按列表排除個案����。因子變量有缺失值的個案,或包括在主對話框中的因變量列表上的任何因變量的值缺失的個案都排除在所有分析之外�。如果尚未指定多個因變量,那么這個選項不起作用�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330