sas信用評分之手動(dòng)對數(shù)值變量分組
上周內(nèi)容已經(jīng)有了預(yù)告��,就是除了我之前發(fā)表的最優(yōu)分段����,我自認(rèn)為比較實(shí)際的分段方法這個(gè)方法我是借鑒了別人的經(jīng)驗(yàn)已經(jīng)根據(jù)自己的業(yè)務(wù)經(jīng)驗(yàn)做的手工分組�,相對于之前的最優(yōu)分組來說,就是因?yàn)槭侵饔^去手動(dòng)去分組����,所以可能分的組別可能更貼近業(yè)務(wù),對于模型后續(xù)的穩(wěn)定性或者跨期驗(yàn)證效果會(huì)好一些�,但是我這不是打臉,就是最優(yōu)分段就是沒用的哈����。最優(yōu)分段在什么下可以使用呢,譬如戶籍地這種情況很多的變量�,你對于分組沒有絲毫的頭緒,那么可以就扔進(jìn)最優(yōu)分組去自動(dòng)分組��。但是這里切記一點(diǎn)�����,當(dāng)數(shù)據(jù)較少的時(shí)候,什么叫數(shù)據(jù)較少��,就是少于20000的時(shí)候��。切記設(shè)置最少的一組至少都要100個(gè)人�,不然就過擬合啦。這樣子的分組��,會(huì)讓模型不穩(wěn)定�����。
那么進(jìn)入正題����。之前已經(jīng)貼過等量分組的代碼。也有人在留言區(qū)說proc rank的過程也可以分組���。等量等寬分組的方法很多��,我也是按照我的經(jīng)驗(yàn)去寫���。但是因?yàn)槲抑懊恐芏紩?huì)貼代碼����,要是這周沒貼�����,會(huì)不會(huì)有些人���,你這么說��,又沒給代碼我還得自己寫代碼,那這篇文章豈不是白寫了嗎�。好吧,介于我這篇文章能有用��,我還是貼代碼�。貼的是數(shù)值的等距分組,因?yàn)樯现艿哪瞧恼碌拇a(頓時(shí)有種自己在寫R包的感覺��。不要罵我臭不要臉):
options compress=yes;
%macro data_split(schema,table_name,N,Y,column);
proc sql;
create table &schema..&table_name._rank(
table_name varchar(100)
,col_name varchar(50)
,rank_name numeric
,low numeric
,up numeric
,cnt numeric
,rate numeric
,n1 numeric
,bad_rate numeric
,woe numeric
,iv numeric
,split_type numeric
);
quit;
proc sql;/*獲得總記錄數(shù)����、總壞客戶數(shù)、總好客戶數(shù)*/
select count(*),SUM(&Y),count(*)-SUM(&Y) into :record_cnt,
:bad_cnt,
:good_cnt
from &schema..&table_name;
quit;
/*2-----不指定分箱的變量,取所有連續(xù)變量*/
%if &column = %str() %then
%do;
proc contents /*獲取輸入數(shù)據(jù)集的所有變量信息*/
data=&schema..&table_name
out=work.&table_name._CONT
noprint;
run;
data work.&table_name._CONT;
set work.&table_name._CONT;
where NAME<>"&Y." AND NAME<>"APPL_ID";
run;/*不包含Y值*/
data _null_;/*獲取輸入數(shù)據(jù)集中的變量個(gè)數(shù)���,并定義宏變量*/
call symput('NUMOBS',put(NUMOBS, 12.));
stop;
set work.&table_name._CONT nobs=NUMOBS ;
run;
%do I=1 %TO &NUMOBS.;/*循環(huán)獲取變量表里面的變量*/
%put &NUMOBS.||&I.;
data _null_;
pointer=&I.;
set work.&table_name._CONT POINT=POINTER;
call symput('col_name', NAME);
call symput('TYPE', put(TYPE, 1.));
stop;
run;
/*僅對數(shù)值變量進(jìn)行逐個(gè)處理*/
%if &TYPE.=1 %then %do;
proc rank data= &schema..&table_name(keep = &col_name &Y) out = data_rank ties = low groups = &N;
var &col_name;
ranks new_rank;
run;
proc sql;
insert into &schema..&table_name._rank(
table_name
,col_name
,rank_name
,low
,up
,cnt
,rate
,n1
,bad_rate
,woe
,iv
,split_type)
select "&table_name"
,"&col_name"
,new_rank
,min(&col_name)
,max(&col_name)
,count(1)
,count(1)/&record_cnt
,sum(&Y)
,sum(&Y)/count(1)
,log((ifn(sum(&Y)=0,0.001,sum(&Y))/&bad_cnt)/((count(1)-sum(&Y))/&good_cnt))
,(sum(&Y)/&bad_cnt-(count(1)-sum(&Y))/&good_cnt)*log((ifn(sum(&Y)=0,0.001,sum(&Y))/&bad_cnt)/((count(1)-sum(&Y))/&good_cnt))
,&N
from data_rank
group by new_rank;
quit;/*將分組的結(jié)果插入rank表�,并計(jì)算每個(gè)變量每個(gè)分組的壞客戶數(shù)、壞客戶占比�����、WOE�����、IV*/
%end;
%end;
%end;
%else
%do;
proc rank data= &schema..&table_name(keep = &column &Y) out = data_rank ties=mean groups = &N;
var &column;
ranks new_rank;
run;
proc sql ;
insert into &schema..&table_name._rank(
table_name
,col_name
,rank_name
,low
,up
,cnt
,rate
,n1
,bad_rate
,woe
,iv
,split_type
)
select "&schema..&table_name"
,"&column"
,new_rank
,min(&column)
,max(&column)
,count(1)
,count(1)/&record_cnt
,sum(&Y)
,sum(&Y)/count(1)
,log((ifn(sum(&Y)=0,0.001,sum(&Y))/&bad_cnt)/((count(1)-sum(&Y)))/&good_cnt))
,(sum(&Y)/&bad_cnt-(count(1)-sum(&Y))/&good_cnt)*log((ifn(sum(&Y)=0,0.001,sum(&Y))/&bad_cnt)/((count(1)-sum(&Y)))/&good_cnt))
,&N
from data_rank
group by new_rank;
quit;
%end;
/*4.將具體分組表轉(zhuǎn)化成用于生成excel數(shù)據(jù)源的格式*/
data &schema..&table_name._rank;
set &schema..&table_name._rank;
if low=" " then low=-1000;
ARRAY var
rank_name
up
;
DO OVER var ;
IF var="" THEN var=-999;
END;
run;
proc sort data=&schema..&table_name._rank;
by col_name;
run;
data &schema..&table_name._rank;
set &schema..&table_name._rank;
by col_name;
clus+1;
if first.col_name then clus=1;
run;
data &schema..&table_name._rank;
set &schema..&table_name._rank;
by col_name;
retain t;
if _n_>1 then low=t;
t=up;
run;
data &schema..&table_name._rank;
set &schema..&table_name._rank;
if clus=1 and rank_name=-999 then low=-1000;
if clus=1 and rank_name=0 then low=-0.1;
if clus=2 and low=-999 then low=-0.1;
run;
proc sql noprint;
create table &schema..&table_name._rank as
(
select t1.table_name,t1.col_name,t1.rank_name,t1.low,case when t2.clus is not null then 10e8 else t1.up end as up
,t1.cnt,t1.rate,t1.n1,t1.bad_rate,t1.woe,t1.iv,t1.split_type,t1.clus
from &schema..&table_name._rank as t1
left join
(
select col_name,max(clus) as clus from &schema..&table_name._rank
group by col_name )as t2
on t1.col_name=t2.col_name
and t1.clus=t2.clus
);
run;/*將最大分組的上限設(shè)置成10e8*/
data &schema..&table_name._rank;
set &schema..&table_name._rank;
testname=compress("("||low||","||up||"]",'');
run;/*將上下限進(jìn)行合并��,生成各分組的取值范圍并去掉了中間的空格*/
/*取類似于excel變量分組的數(shù)據(jù)源*/
proc sql noprint;
create table &schema..&table_name._rank_excel as
(
select * from
(select t1.col_name as col_name1,t1.col_name as col_name2,'' as testname,'' as clus,'' as n,'' as n1
from &schema..&table_name._rank as t1
where clus=1)
union all
(select t2.col_name as col_name2,'' as col_name2,t2.testname,t2.clus,t2.cnt as n,t2.n1
from &schema..&table_name._rank as t2)
)
;
quit;
proc sql noprint;
create table &schema..&table_name._iv as
(select col_name,sum(iv) as iv from &schema..&table_name._rank
group by col_name)
;
quit;
proc sort data=&schema..&table_name._iv;
by descending iv ;
quit;
%mend data_split;
關(guān)于這段代碼中用到的proc rank可以看之前的這篇文章:proc rank過程���。
還是老樣子�,講解一下怎么代碼怎么用����。
data_split(schema,table_name,N,Y,column);
schema:填入你的數(shù)據(jù)集的邏輯庫。
table_name:填入你的數(shù)據(jù)集�����,不帶邏輯庫名。
N:你要分幾組��。
Y:因變量��。
Column:這個(gè)參數(shù)就讓他空就可以了��。我是寫多了�,但是又忘記改回來。
就是你填入這幾項(xiàng)就可以了按以下這個(gè)順序:
%data_split(邏輯庫,表名,分箱數(shù),因變量);
到這里我都是在講代碼�,現(xiàn)在來講手動(dòng)分組的內(nèi)容。首先代碼跑出來有幾張表���,最重要就是這樣表“你的表名__rank”的這種表是重點(diǎn)��。

這是我分10組粗分類的情況�����。我會(huì)將這張表導(dǎo)出成excel.
然后以這個(gè)變量為例哈。
這里注意一件事����。就是low=-1000 up=-999代表就是空值,在最優(yōu)分組中�。空值將成為單獨(dú)的一組,但是我們手動(dòng)分組中就不這么做了�,我們會(huì)將空值放在跟一組與其woe相近的組別在一起。除非真的空值的woe值真的特別突出����,那么就單獨(dú)成為一組,這種情況你就自己判斷哈�����,隨機(jī)應(yīng)變哈��,發(fā)揮你的腦回路的時(shí)候到了���。
回到excel的內(nèi)容:
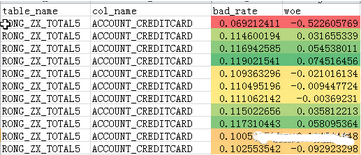
這部分很繁瑣的原因是��,譬如我現(xiàn)在有100多個(gè)變量是iv值是可以達(dá)到我的要求的話��,那么就是我要手動(dòng)分100多個(gè)變量的�,說實(shí)話我覺得這樣子我挺白癡�,但是我又覺得是有用的變量,分組的問題本來就重要����,那就白癡我也要親自分段���。無非就多花幾個(gè)小時(shí)在搞這個(gè)事情。導(dǎo)出excel后�����,為了讓變量的分成可以清晰一些��,我會(huì)利用色階讓我好判斷一些���。
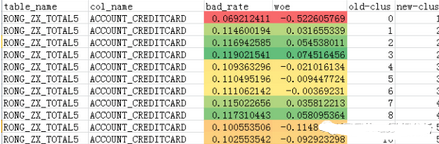
其實(shí)這個(gè)變量是比較好分層的���。按照色階的顏色,我們就把細(xì)分類給分出來了�����。這里為什么對bad_rate和woe都標(biāo)了色階�,是因?yàn)楫?dāng)我在判斷分組時(shí)候會(huì)以woe為主,bad_rate為輔去分組�。
其實(shí)對于我個(gè)人建模�����,分為五組,我還是覺得有點(diǎn)多了����。但是介于這個(gè)變量woe分層情況,所以這樣子看也可以接受����。我剛才說了對于null的組別,是可以跟別的組在一起的�����,但是這里他特立獨(dú)行的一個(gè)顏色���,我也沒辦法把他跟別的組放一起�����。講到空值還有一個(gè)問題�����,就是在連續(xù)變量等量分組時(shí)候�,空值會(huì)被變成獨(dú)立的一組��,那么這時(shí)候,假設(shè)如果你的變量null不是很多���,而且你可以用你別的組別填充的話�,建議填充��。因?yàn)榧僭O(shè)你的數(shù)據(jù)大概有20000���,但是null可能就30個(gè)���,這種占比其實(shí)是很小,你為這30個(gè)特地設(shè)了一個(gè)分組�,你要是覺得可以那也就可以吧,具體聽你的領(lǐng)導(dǎo)的哈�。
回到分組的問題,你分好組之后再回去更新到主表中去算woe��。這部分代碼我就不貼了�,要是你覺得你沒有思路,實(shí)在寫不出來�,你可以找我要。還是那句話�。自己工作自己的作業(yè)自己做,你寫了整個(gè)代碼的架構(gòu)����,你報(bào)錯(cuò)我可以幫你改,但是你什么都沒寫�,直接說你不會(huì)寫,我是不會(huì)幫你��,請粉絲們理解
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330