機器學(xué)習(xí)項目中的數(shù)據(jù)預(yù)處理與數(shù)據(jù)整理之比較
要點
在常見的機器學(xué)習(xí)/深度學(xué)習(xí)項目里��,數(shù)據(jù)準(zhǔn)備占去整個分析管道的60%到80%����。
市場上有各種用于數(shù)據(jù)清洗和特征工程的編程語言�����、框架和工具����。它們之間的功能有重疊���,也各有權(quán)衡�。
數(shù)據(jù)整理是數(shù)據(jù)預(yù)處理的重要擴展�����。它最適合在可視化分析工具中使用�,這能夠避免分析流程被打斷。
可視化分析工具與開源數(shù)據(jù)科學(xué)組件之間�,如R、Python����、KNIME����、RapidMiner互為補充��。
避免過多地使用組件能夠加速數(shù)據(jù)科學(xué)項目�。因此,在數(shù)據(jù)準(zhǔn)備步驟中利用流式獲取框架或流式分析產(chǎn)品會是一個不錯的選擇�。
機器學(xué)習(xí)和深度學(xué)習(xí)項目在大多數(shù)企業(yè)中變得越來越重要。一個完整的項目流程包括數(shù)據(jù)準(zhǔn)備(data
preparation)�����、構(gòu)建分析模型以及部署至生產(chǎn)環(huán)境��。該流程是一個洞察-行動-循環(huán)(insights-action-loop)�����,此循環(huán)能不斷地改進(jìn)分析模型�。Forrester把這個完整的流程和其背后的平臺稱為 洞察平臺 (Insights Platform)。
當(dāng)你打算使用機器學(xué)習(xí)或深度學(xué)習(xí)技術(shù)來構(gòu)建分析模型時�����,一個重要的任務(wù)是集成并通過各種數(shù)據(jù)源來準(zhǔn)備數(shù)據(jù)集�,這些數(shù)據(jù)源包括比如文件、數(shù)據(jù)庫�、大數(shù)據(jù)存儲、傳感器或社交網(wǎng)絡(luò)等等����。此步驟可占整個分析項目的80%。
本文比較了用于數(shù)據(jù)準(zhǔn)備的幾種方法�����,它們分別是提取-變換-加載(extract-transform-load�����,ETL)批處理�����、流式獲?���。╯treaming
ingestion)和數(shù)據(jù)整理(data wrangling)。同時借助于先進(jìn)的分析技術(shù)和開源框架(如 R ����、 Apache Spark 、 KNIME �、 RapidMiner ),討論了各種不同的選擇及其折中�����。本文還討論了數(shù)據(jù)準(zhǔn)備如何與可視化分析相關(guān)聯(lián)����,以及不同用戶角色(如數(shù)據(jù)科學(xué)家或業(yè)務(wù)分析人員)應(yīng)如何共同構(gòu)建分析模型的最佳實踐。
數(shù)據(jù)準(zhǔn)備=數(shù)據(jù)清洗(Data Cleansing)+特征工程(Feature Engineering)
數(shù)據(jù)準(zhǔn)備是數(shù)據(jù)科學(xué)的核心����。它包括數(shù)據(jù)清洗和特征工程。另外領(lǐng)域知識(domain
knowledge)也非常重要���,它有助于獲得好的結(jié)果�����。數(shù)據(jù)準(zhǔn)備不能完全自動化�,至少在初始階段不能�。通常�,數(shù)據(jù)準(zhǔn)備占去整個分析管道(流程)的60%到80%�����。但是��,為了使機器學(xué)習(xí)算法在數(shù)據(jù)集上獲得最優(yōu)的精確性����,數(shù)據(jù)準(zhǔn)備必不可少���。
數(shù)據(jù)清洗可使數(shù)據(jù)獲得用于分析的正確形狀(shape)和質(zhì)量(quality)��。它包括了許多 不同的功能 ����,例如:
基本功能(選擇����、過濾、去重�、…)
采樣(平衡(balanced)、分層(stratified)��、…)
數(shù)據(jù)分配(創(chuàng)建訓(xùn)練+驗證+測試數(shù)據(jù)集、…)
變換(歸一化�����、標(biāo)準(zhǔn)化����、縮放、pivoting�、…)
分箱(Binning)(基于計數(shù)、將缺失值作為其自己的組處理���、…)
數(shù)據(jù)替換(剪切(cutting)��、分割(splitting)�、合并���、…))
加權(quán)與選擇(屬性加權(quán)����、自動優(yōu)化�����、…)
屬性生成(ID生成、…)
數(shù)據(jù)填補(imputation)(使用統(tǒng)計算法替換缺失的觀察值)
特征工程會為分析選取正確的屬性���。我們需要借助數(shù)據(jù)的領(lǐng)域知識來選取或創(chuàng)建屬性�,這些屬性能使機器學(xué)習(xí)算法正確地工作��。特征工程過程包括:
頭腦風(fēng)暴或特征測試
特征選擇
驗證這些特征如何與模型配合使用
如果需要��,改進(jìn)特征
回到頭腦風(fēng)暴/創(chuàng)建更多的特征��,直到工作完成
請注意���,特征工程已是建模(構(gòu)建分析模型)步驟里的一部分,但它也利用數(shù)據(jù)準(zhǔn)備這一功能(例如提取字符串的某些部分)�。
數(shù)據(jù)清洗和特征工程是數(shù)據(jù)準(zhǔn)備的一部分,也是機器學(xué)習(xí)和深度學(xué)習(xí)應(yīng)用的基礎(chǔ)��。這二者并不是那么容易����,都需要花費功夫。
數(shù)據(jù)準(zhǔn)備會出現(xiàn)在分析項目的不同階段:
數(shù)據(jù)預(yù)處理:從數(shù)據(jù)源獲取數(shù)據(jù)之后直接處理數(shù)據(jù)��。通常由開發(fā)人員或數(shù)據(jù)科學(xué)家實現(xiàn)���,它包括初始轉(zhuǎn)換����、聚合(aggregation)和數(shù)據(jù)清洗。此步驟在數(shù)據(jù)的交互式分析開始之前完成�����。它只執(zhí)行一次�����。
數(shù)據(jù)整理:在交互式數(shù)據(jù)分析和建模期間準(zhǔn)備數(shù)據(jù)����。通常由數(shù)據(jù)科學(xué)家或業(yè)務(wù)分析師完成,以便更改數(shù)據(jù)集和特征工程的視圖���。此步驟會迭代更改數(shù)據(jù)集的形狀��,直到它能很好地查找洞察或構(gòu)建良好的分析模型��。
不可或缺的數(shù)據(jù)預(yù)處理和數(shù)據(jù)整理
讓我們看一看典型的用于模型構(gòu)建的分析流程:
數(shù)據(jù)訪問
數(shù)據(jù)預(yù)處理
探索性數(shù)據(jù)分析(Exploratory Data Analysis)(EDA)
模型構(gòu)建
模型驗證
模型執(zhí)行
部署
步驟2的重點是在構(gòu)建分析模型之前進(jìn)行的數(shù)據(jù)預(yù)處理���,而數(shù)據(jù)整理則用于步驟3和步驟4(在分析數(shù)據(jù)和構(gòu)建模型時��,數(shù)據(jù)整理允許交互式調(diào)整數(shù)據(jù)集)�����。注意����,這三個步驟(2�����、3����、4)都可以包括數(shù)據(jù)清洗和特征工程�����。
以下截圖是“數(shù)據(jù)準(zhǔn)備”���、“數(shù)據(jù)預(yù)處理”和“數(shù)據(jù)整理”這幾個術(shù)語的Google搜索趨勢�?����?梢钥闯觯瑪?shù)據(jù)整理受到了越來越多的關(guān)注:
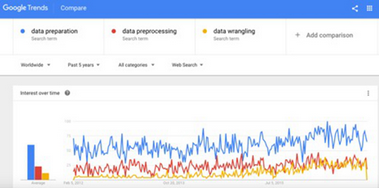
圖1:“數(shù)據(jù)準(zhǔn)備”���、“數(shù)據(jù)預(yù)處理”和“數(shù)據(jù)整理”的Google搜索趨勢
“inline數(shù)據(jù)整理”(inline data
wrangling)是“數(shù)據(jù)整理”的一種特殊形式�����。在inline數(shù)據(jù)整理里�����,你可以利用可視化分析工具�。這些工具不僅能用于可視化和模型構(gòu)建�����,而且還能用于直接交互式整理��。inline數(shù)據(jù)整理有巨大的優(yōu)勢���,如下圖所示:
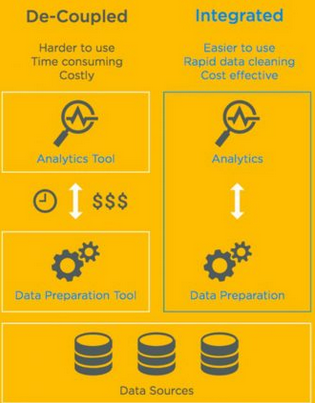
圖2:解耦數(shù)據(jù)預(yù)處理(decoupled data preprocessing)與inline數(shù)據(jù)整理的比較
分析管道中的數(shù)據(jù)預(yù)處理和數(shù)據(jù)整理步驟通常由不同類型的用戶完成��。以下是參與分析項目的各種用戶角色:
業(yè)務(wù)分析師:具有特定領(lǐng)域知識的商業(yè)/行業(yè)專家
數(shù)據(jù)科學(xué)家:數(shù)學(xué)�、統(tǒng)計與編程(數(shù)據(jù)科學(xué)/腳本編寫)專家;能夠編寫底層代碼或使用更上層的工具
平民數(shù)據(jù)科學(xué)家(Citizen Data Scientist):類似于數(shù)據(jù)科學(xué)家��,但處于更上層����;需要使用更上層的工具而非編寫代碼;取決于工具的易用性�����,相關(guān)工作甚至可以由業(yè)務(wù)分析師來完成
開發(fā)者:軟件開發(fā)專家(企業(yè)應(yīng)用程序)
這些用戶必須密切合作����,以便在數(shù)據(jù)科學(xué)項目中取得成功(另見“ 如何避免分析中的反模式:機器學(xué)習(xí)的三個要點 ”,這篇文章能幫你更好地了解這些用戶角色)��。
雖然本文重點是介紹數(shù)據(jù)準(zhǔn)備���,但 一圖勝千言 ,并且人類只能解釋直觀可見的東西而非那些復(fù)雜的非結(jié)構(gòu)化數(shù)據(jù)集���,因此了解數(shù)據(jù)準(zhǔn)備與可視化分析的關(guān)系也非常重要�����。有關(guān)更多細(xì)節(jié)���,請參閱文章 為什么應(yīng)該使用可視化分析來做出更好的決策 �����。目前主要的可視化分析工具有 Qlik ����、 Tableau 和 TIBCO Spotfire ��。
那么可視化分析是如何與數(shù)據(jù)整理相關(guān)聯(lián)的呢���? RITO研究公司的首席分析師 說���,“讓分析師停下他們手里正在進(jìn)行的工作,而去切換到另一個工具是令人發(fā)狂的����。這破壞了他們的工作流程。 他們不得不返回重拾思路���,重新開始���。這嚴(yán)重影響了他們的生產(chǎn)力和創(chuàng)造力”����。
Kaggle的Titanic數(shù)據(jù)集
以下章節(jié)給出了數(shù)據(jù)準(zhǔn)備的幾種備選方案�����。我們將用非常著名的 Titanic數(shù)據(jù)集 (來自于Kaggle)來演示一些實用的例子����。Titanic數(shù)據(jù)集被分為訓(xùn)練集和測試集,它將用于構(gòu)建分析模型���,這些模型用來預(yù)測哪個乘客可能會存活或死亡:

圖3:Kaggle Titanic數(shù)據(jù)集的元數(shù)據(jù)
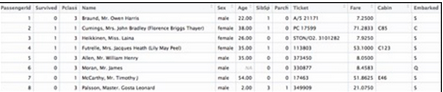
圖4:Kaggle Titanic數(shù)據(jù)集的數(shù)據(jù)行示例
原始數(shù)據(jù)集不能直接用于構(gòu)建分析模型�����。它含有重復(fù)、缺失值以及包含各種不同信息的單元格��。因此����,在應(yīng)用機器學(xué)習(xí)算法時���,需要先將原始數(shù)據(jù)集處理好,以便獲得最佳結(jié)果��。以下是一些數(shù)據(jù)清洗和特征工程的例子:
通過特征提?���。╢eature extraction)創(chuàng)建新列:獲取每位乘客的姓名前綴,從而推斷出其性別�,例如,先生����、夫人、小姐���、大師
通過聚合創(chuàng)建新列�����,以查看每位乘客的旅行團(tuán)中有多少人:“家庭大小= 1 + SibSp + Parch”
通過提取第一個字符來創(chuàng)建新列�����,以便排序和分析艙室:提取“艙室”列的第一個字符
刪除數(shù)據(jù)集中的重復(fù)項��,例如����,乘客既在訓(xùn)練集中又在測試集中
通過填補將數(shù)據(jù)添加到空單元格,以便能夠處理數(shù)據(jù)缺失的行���,例如����,年齡:將“不可用”替換為所有乘客的平均年齡或?qū)⑵潆x散到對應(yīng)的箱(bin)中��;艙室:用“U”(未知)替換空值�����;或應(yīng)用高級填補方法��,例如��, 通過鏈?zhǔn)椒匠痰亩嘀靥钛a (multiple imputation by chained equations)(MICE)
利用數(shù)據(jù)科學(xué)功能�,例如,縮放�����、歸一化���、 主成分分析 (PCA)或 Box-Cox ����,使所有數(shù)據(jù)處于“相似形狀”�����,以便能夠進(jìn)行合理的分析
以下章節(jié)闡述了各種編程語言����、框架和數(shù)據(jù)準(zhǔn)備工具。請注意�����,沒有哪種方案適用于所有問題�����。此外����,這些方案之間也有很多重疊(overlapping)���。因此,根據(jù)用戶角色和用例����,許多問題可以使用不同的方案來解決。
數(shù)據(jù)科學(xué)的數(shù)據(jù)預(yù)處理
一些編程語言是專為數(shù)據(jù)科學(xué)項目而設(shè)計���,或者是對它有非常好的支持��,特別是 R 和 Python����。它們包含了機器學(xué)習(xí)算法的各種實現(xiàn)���,諸如過濾或提取的預(yù)處理功能��,以及諸如縮放����、歸一化或混洗(shuffle)的數(shù)據(jù)科學(xué)功能�����。數(shù)據(jù)科學(xué)家需要編寫相對底層的代碼來進(jìn)行探索性數(shù)據(jù)分析與準(zhǔn)備。與使用Java或C#的傳統(tǒng)編程相反�����,使用R或Python進(jìn)行數(shù)據(jù)預(yù)處理時�����,你不需要編寫太多的代碼���;它更多地是讓你了解統(tǒng)計概念以及算法的數(shù)據(jù)和經(jīng)驗,這些數(shù)據(jù)和經(jīng)驗可用于數(shù)據(jù)預(yù)處理和模型構(gòu)建��。
這些編程語言是為數(shù)據(jù)科學(xué)家準(zhǔn)備數(shù)據(jù)和構(gòu)建分析模型而建立����,它們并不適用于企業(yè)部署(將分析模型部署到具有高規(guī)模和高可靠性的新數(shù)據(jù)中)。因此��,市場上提供了商業(yè)的enterprise
runtime幫助你實現(xiàn)企業(yè)部署��。通常�����,它們支持相同的源代碼,因此你不需要為企業(yè)部署重寫任何東西����。對于R,你可以使用開源的 Microsoft R Open (之前的 Revolution R )�����,或 TIBCO Enterprise Runtime for R �。后者具有不受GPL開源許可證限制的優(yōu)勢,因此你可以使用在任何嵌入式或外部環(huán)境里���。
下面的代碼 摘錄于一個不錯的R教程 ���,它演示了如何使用基本的R語言來預(yù)處理和分析Titanic數(shù)據(jù)集:
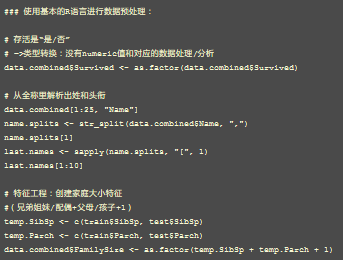
除了對預(yù)處理的基本支持外,這些編程語言還提供了許多額外的數(shù)據(jù)科學(xué)軟件包����。例如,許多數(shù)據(jù)科學(xué)家利用 R中 非常強大的 caret包 來簡化數(shù)據(jù)準(zhǔn)備和減少代碼量���。該軟件包簡化了復(fù)雜回歸和分類問題的模型準(zhǔn)備與訓(xùn)練過程��。它為數(shù)百個現(xiàn)有的R模型實現(xiàn)(在底層使用了各種各樣的API)提供了一個通用接口�����。以下代碼段使用了caret的通用API對Titanic數(shù)據(jù)集進(jìn)行預(yù)處理:
### 使用R caret包進(jìn)行數(shù)據(jù)預(yù)處理:
# 利用caret的preProcess函數(shù)對數(shù)據(jù)做歸一化
preproc.data.combined <- data.combined[, c("ticket.party.size", "avg.fare")]
preProc <- preProcess(preproc.data.combined, method = c("center", "scale"))
# ->你看到的是相對值而非絕對值(即彼此之間的關(guān)系):
postproc.data.combined <- predict(preProc, preproc.data.combined)
另一個用于數(shù)據(jù)預(yù)處理的R包是 dplyr 包��。它不像caret包那樣強大�,并且只專注于操作����、清洗和匯總(summarize)非結(jié)構(gòu)化數(shù)據(jù)。 Dplyr旨在為數(shù)據(jù)操作的 每個基本動作都提供一個函數(shù) :
filter()(和slice())
arrange()
select()(和rename())
distinct()
mutate()(和transmute())
summarise()
sample_n (和sample_frac())
因此���,學(xué)習(xí)和理解許多數(shù)據(jù)操作任務(wù)變得容易�。對于 data.table 包也是這樣���。正如你所見的���,在R語言里你有許多方法來預(yù)處理數(shù)據(jù)集。
數(shù)據(jù)科學(xué)家或開發(fā)者的大數(shù)據(jù)集預(yù)處理
諸如R或Python這樣的編程語言可用于處理小數(shù)據(jù)集�����。但是,它們并不是為處理真正的大數(shù)據(jù)集而創(chuàng)建���;與此同時����,我們經(jīng)常需要分析幾個GB�、TB甚至PB級別的數(shù)據(jù)。類似于 Apache Hadoop 或 Apache Spark 的大數(shù)據(jù)框架則是為處于邊緣的(即數(shù)據(jù)所在位置)彈性擴展(elastic scalability)和數(shù)據(jù)預(yù)處理而創(chuàng)建�。
這些大數(shù)據(jù)框架側(cè)重于“底層”編碼,并且配置起來比R或Python環(huán)境要復(fù)雜得多���。商業(yè)軟件�����,如 Hortonworks �����、 Cloudera ����、 MapR 或 Databricks 可以幫助解決此問題。通常�,數(shù)據(jù)科學(xué)家與開發(fā)人員相互合作來完成大數(shù)據(jù)項目。后者負(fù)責(zé)集群配置���、部署和監(jiān)控����,而數(shù)據(jù)科學(xué)家則利用R或Python API編寫用于數(shù)據(jù)預(yù)處理和構(gòu)建分析模型的代碼����。
源代碼通常看起來與僅使用R或Python的代碼非常相似���,但數(shù)據(jù)預(yù)處理是在整個集群上并行完成的。下面的示例演示了如何使用Spark的Scala API 對Titanic數(shù)據(jù)集進(jìn)行預(yù)處理和特征工程 :
### 使用Scala和Apache Spark API進(jìn)行數(shù)據(jù)預(yù)處理:
# 特征工程:創(chuàng)建家庭大小特征
# (兄弟姐妹/配偶+父母/孩子+1)
val familySize: ((Int, Int) => Int) = (sibSp: Int, parCh: Int) => sibSp + parCh + 1
val familySizeUDF = udf(familySize)
val dfWithFamilySize = df.withColumn("FamilySize", familySizeUDF(col("SibSp"), col("Parch")))
// 為年齡列填充空值
val avgAge = trainDF.select("Age").union(testDF.select("Age"))
.agg(avg("Age"))
.collect() match {
case Array(Row(avg: Double)) => avg
case _ => 0
}
當(dāng)然��,你可以使用Spark的Java或Python API做同樣的事情�。
平民數(shù)據(jù)科學(xué)家的數(shù)據(jù)預(yù)處理
通常,你想要敏捷并且快速得到結(jié)果�。這常常需要在準(zhǔn)備和分析數(shù)據(jù)集時大量地試錯。你可以利用現(xiàn)存的各種快捷易用的數(shù)據(jù)科學(xué)工具���。這些工具提供了:
開發(fā)環(huán)境和運行/執(zhí)行服務(wù)器
使用拖放與代碼生成的可視化“編碼”
集成各種數(shù)據(jù)科學(xué)框架��,如R��、Python或更強大的(諸如Apache Hadoop�、Apache Spark或底層的 H2O.ai )大數(shù)據(jù)框架
數(shù)據(jù)科學(xué)家可以使用這些工具來加速數(shù)據(jù)預(yù)處理和模型建立。此外�,該類工具還幫助解決了數(shù)據(jù)預(yù)處理和機器學(xué)習(xí)算法的實現(xiàn),因此沒有太多項目經(jīng)驗的平民數(shù)據(jù)科學(xué)家也可以使用它們�����。一些工具甚至能夠提出建議���,這些建議有助于用戶預(yù)處理����、顯示和分析數(shù)據(jù)集�����。這些工具在底層人工智能的驅(qū)動下變得越來越智能��。
下面的例子展示了如何使用兩個開源數(shù)據(jù)科學(xué)工具KNIME和 RapidMiner 來預(yù)處理Titanic數(shù)據(jù)集:
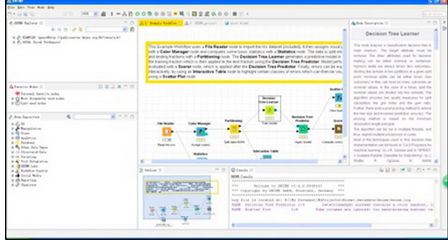
使用KNIME來預(yù)處理Titanic數(shù)據(jù)集
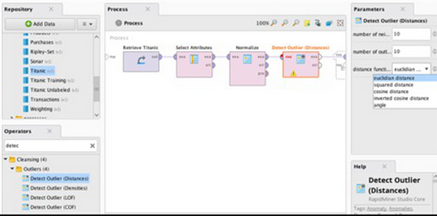
使用RapidMiner來預(yù)處理Titanic數(shù)據(jù)集
你可以使用可視化IDE來配置預(yù)處理�����,而非如前所述的用R或Scala編寫源代碼。對大多數(shù)用戶來說���,這使得數(shù)據(jù)準(zhǔn)備和分析變得更容易�,并且數(shù)據(jù)的維護(hù)和移交也變得更容易�����。
業(yè)務(wù)分析師或平民數(shù)據(jù)科學(xué)家的數(shù)據(jù)整理
數(shù)據(jù)整理(有時也稱為data munging)是一種使用圖形工具的數(shù)據(jù)準(zhǔn)備方法����,該方法簡單直觀。這些工具側(cè)重于易用性和敏捷的數(shù)據(jù)準(zhǔn)備��。因此��,它不一定由開發(fā)人員或數(shù)據(jù)科學(xué)家完成�����,而是所有的用戶都可以(包括業(yè)務(wù)分析師或平民數(shù)據(jù)科學(xué)家)����。 DataWrangler 和 Trifacta Wrangler 是數(shù)據(jù)整理的兩個示例����。
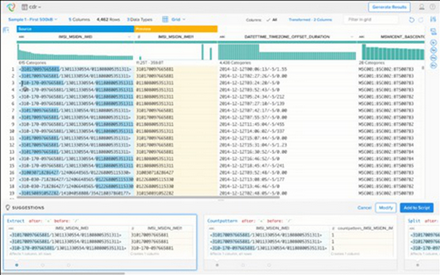
用于數(shù)據(jù)整理的Trifacta
請注意�,這些工具沒有數(shù)據(jù)預(yù)處理框架那么強大�,因此它們經(jīng)常用于數(shù)據(jù)準(zhǔn)備的最后一公里。它們不會替換其它的集成選項��,如ETL(提取-變換-加載)工具����,或使用R、Python��、KNIME��、RapidMiner等進(jìn)行的數(shù)據(jù)預(yù)處理��。
如引言中所討論����,因為數(shù)據(jù)整理與實際數(shù)據(jù)分析相互解耦,所以數(shù)據(jù)整理自身的工具可能會存在一些不足之處���?�?梢暬治龉ぞ咧械臄?shù)據(jù)整理允許在數(shù)據(jù)的探索性分析期間進(jìn)行inline數(shù)據(jù)整理�����。單個的用戶使用單一的工具就能夠完成它�。例如,請參閱TIBCO
Spotfire示例��,它 結(jié)合了可視化分析與inline數(shù)據(jù)整理 (以及其它的數(shù)據(jù)科學(xué)功能來構(gòu)建分析模型):
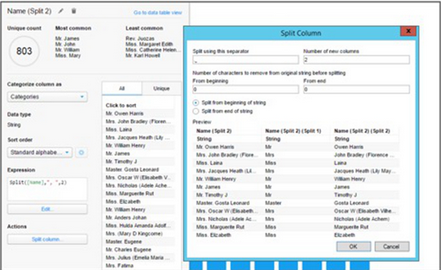
可視化分析工具TIBCO Spotfire中的inline數(shù)據(jù)整理
數(shù)據(jù)整理工具和帶有inline數(shù)據(jù)整理的可視化分析工具可以被每種用戶角色使用:業(yè)務(wù)分析師�、(平民)數(shù)據(jù)科學(xué)家或開發(fā)人員,這些工具能夠加速數(shù)據(jù)準(zhǔn)備和數(shù)據(jù)分析���。
本文重點介紹了用于建立機器學(xué)習(xí)模型的數(shù)據(jù)準(zhǔn)備�����。你可以使用編程語言(如R或Python)�、數(shù)據(jù)科學(xué)工具(如KNIME或RapidMiner)���、數(shù)據(jù)整理(使用DataWrangler或Trificata)或inline數(shù)據(jù)整理(通過TIBCO
Spotfire)��。通常����,在開始這一切之前�����,你需要能夠訪問你擁有的所有數(shù)據(jù)�����,這些數(shù)據(jù)存儲于各種或多或少整理過的數(shù)據(jù)源中(如關(guān)系數(shù)據(jù)庫��、數(shù)據(jù)倉庫�����、大數(shù)據(jù)集群)��。因此����,在以下兩部分,我們將簡要介紹用于數(shù)據(jù)獲?。╠ata
ingestion)的ETL和流式分析工具,通常數(shù)據(jù)獲取還包括數(shù)據(jù)準(zhǔn)備的某些部分���,特別是數(shù)據(jù)聚合和數(shù)據(jù)清洗����。
開發(fā)者的ETL(提取-變換-加載)和DQ(數(shù)據(jù)質(zhì)量,Data Quality)
ETL工具是為開發(fā)者集成各種數(shù)據(jù)源而設(shè)計的�����,它包括了許多遺留和專有(proprietary)接口(如Mainframe或 EDIFACT接口 )�����,這些接口具有十分復(fù)雜的數(shù)據(jù)結(jié)構(gòu)�����。它還包括了數(shù)據(jù)清洗(在上下文中通常被稱為“數(shù)據(jù)質(zhì)量”工具)��,并將重點放在易用性和使用可視化編碼的企業(yè)部署上(類似于如KNIME或RapidMiner的數(shù)據(jù)科學(xué)工具��,但是專注于ETL和數(shù)據(jù)質(zhì)量)����。它們還支持大數(shù)據(jù)框架,如Apache
Hadoop和Apache Spark���。此外�����,它們還為質(zhì)量改進(jìn)提供了開箱即用(out-of-the-box
)的支持��,例如���,地址驗證。ETL和DQ通常在長時間運行的批處理進(jìn)程中實現(xiàn)�,因此如果你需要使用實時數(shù)據(jù)構(gòu)建模型,那么這有時可能會產(chǎn)生負(fù)面影響�。
ETL和DQ工具的例子是一些開源工具,如 Pentaho 或 Talend �,或?qū)S泄?yīng)商 Informatica 。市場正在向更簡單易用的Web用戶界面轉(zhuǎn)移�,這些簡單易用的界面能夠讓其他用戶角色也執(zhí)行一些基本的任務(wù)。
開發(fā)者的數(shù)據(jù)獲取與流式分析
數(shù)據(jù)獲取與流式分析工具可用于在流(stream)中添加和預(yù)處理數(shù)據(jù)����。這些框架允許批量地或?qū)崟r地預(yù)處理數(shù)據(jù)。下圖展示了一個典型的流式分析流程���,它包括數(shù)據(jù)獲取�����、預(yù)處理����、分析、處理和輸出:
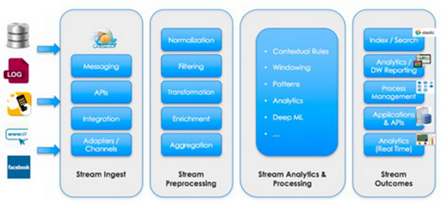
流式分析流程的步驟
目前市場上有各種各樣的框架和工具�����。它們都以這種或那種方式支持類似Hadoop或Spark的大數(shù)據(jù)框架���。舉幾個例子:
數(shù)據(jù)獲取開源框架(僅關(guān)注數(shù)據(jù)獲取和預(yù)處理步驟): Apache NiFi ���、 StreamSets 、 Cask Hydrator
流式處理開源框架(完整的流式分析流程): Apache Storm �、 Apache Flink 、 Apache Apex
流式處理商業(yè)軟件(完整的流式分析流程): Software AG Apama ��、 IBM Streams ���、 TIBCO StreamBase
有關(guān)更多信息�����,請參閱 流式分析框架����、產(chǎn)品和云服務(wù)的比較 。
使用這些工具(包括ETL)的巨大優(yōu)勢是����,你可以使用同一套工具或框架(對歷史數(shù)據(jù))進(jìn)行數(shù)據(jù)預(yù)處理�,以及(對新數(shù)據(jù))進(jìn)行實時處理(以便在變化的數(shù)據(jù)里使用分析模型)。這將會是一個不錯的選擇��,用戶不僅可以保持小而精的工具集���,而且還能通過一套工具同時獲得ETL/獲取和實時處理�。下圖是一個使用TIBCO
StreamBase對Titanic數(shù)據(jù)集進(jìn)行預(yù)處理的例子:
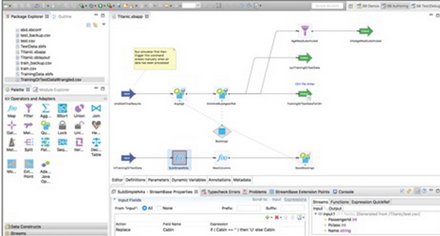
Titanic數(shù)據(jù)集的流式預(yù)處理
對于數(shù)據(jù)獲取和ETL工具����,流式分析的市場正在轉(zhuǎn)向更簡單的Web用戶界面,這些簡單的用戶界面讓其他用戶角色也能執(zhí)行一些基本的任務(wù)���。但這不會取代現(xiàn)有的工具在更高級別用例里的使用���,而是為分析師或數(shù)據(jù)科學(xué)家提供了新的選擇。在沒有開發(fā)人員的幫助下�����,他們能夠更容易和更直接地部署一些規(guī)則、關(guān)聯(lián)或分析模型���。
數(shù)據(jù)準(zhǔn)備是機器學(xué)習(xí)項目成功的關(guān)鍵
使用機器學(xué)習(xí)或深度學(xué)習(xí)技術(shù)構(gòu)建分析模型并不容易�。數(shù)據(jù)準(zhǔn)備占去整個分析管道的60%到80%�����。市場上有各種用于數(shù)據(jù)清洗和特征工程的編程語言�、框架和工具。它們之間的功能有重疊�����,也各有權(quán)衡����。
數(shù)據(jù)整理是數(shù)據(jù)預(yù)處理的重要擴展(add-on)。它最適合在可視化分析工具中使用�����,這能夠避免分析流程被打斷�??梢暬治龉ぞ吲c開源數(shù)據(jù)科學(xué)組件(component)之間���,如R���、Python、KNIME����、RapidMiner互為補充���。
避免過多地使用組件能夠加速數(shù)據(jù)科學(xué)項目�����。因此����,在數(shù)據(jù)準(zhǔn)備步驟中利用流式獲取框架或流式分析產(chǎn)品會是一個不錯的選擇����。我們只需要編寫一次預(yù)處理的步驟,然后將其用于歷史數(shù)據(jù)的批處理中���,從而進(jìn)行分析模型的構(gòu)建��,同時����,還可以將其用于實時處理,這樣就能將我們構(gòu)建的分析模型用到新的事件中��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330