三張圖讀懂機器學習:基本概念�、五大流派與九種常見算法
機器學習正在進步�����,我們似乎正在不斷接近我們心中的人工智能目標�����。語音識別���、圖像檢測���、機器翻譯、風格遷移等技術已經(jīng)在我們的實際生活中開始得到了應用�,但機器學習的發(fā)展仍還在繼續(xù),甚至被認為有可能徹底改變人類文明的發(fā)展方向乃至人類自身�����。但你了解現(xiàn)在正在發(fā)生的這場變革嗎����?四大會計師事務所之一的普華永道(PwC)近日發(fā)布了多份解讀機器學習基礎的圖表,其中介紹了機器學習的基本概念���、原理�、歷史、未來趨勢和一些常見的算法�����。為便于讀者閱讀���,機器之心對這些圖表進行了編譯和拆分����,分三大部分對這些內容進行了呈現(xiàn)����,希望能幫助你進一步閱讀。
一���、機器學習概覽

1. 什么是機器學習����?
機器通過分析大量數(shù)據(jù)來進行學習��。比如說,不需要通過編程來識別貓或人臉���,它們可以通過使用圖片來進行訓練��,從而歸納和識別特定的目標�。
2. 機器學習和人工智能的關系
機器學習是一種重在尋找數(shù)據(jù)中的模式并使用這些模式來做出預測的研究和算法的門類�����。機器學習是人工智能領域的一部分���,并且和知識發(fā)現(xiàn)與數(shù)據(jù)挖掘有所交集。
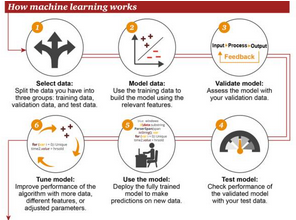
3. 機器學習的工作方式
①選擇數(shù)據(jù):將你的數(shù)據(jù)分成三組:訓練數(shù)據(jù)�����、驗證數(shù)據(jù)和測試數(shù)據(jù)
②模型數(shù)據(jù):使用訓練數(shù)據(jù)來構建使用相關特征的模型
③驗證模型:使用你的驗證數(shù)據(jù)接入你的模型
④測試模型:使用你的測試數(shù)據(jù)檢查被驗證的模型的表現(xiàn)
⑤使用模型:使用完全訓練好的模型在新數(shù)據(jù)上做預測
⑥調優(yōu)模型:使用更多數(shù)據(jù)����、不同的特征或調整過的參數(shù)來提升算法的性能表現(xiàn)
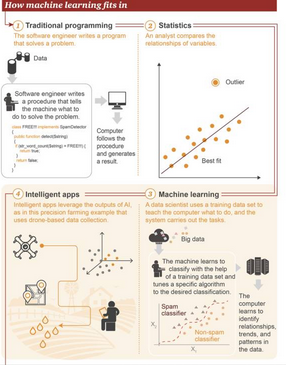
4. 機器學習所處的位置
①傳統(tǒng)編程:軟件工程師編寫程序來解決問題。首先存在一些數(shù)據(jù)→為了解決一個問題�,軟件工程師編寫一個流程來告訴機器應該怎樣做→計算機遵照這一流程執(zhí)行,然后得出結果
②統(tǒng)計學:分析師比較變量之間的關系
③機器學習:數(shù)據(jù)科學家使用訓練數(shù)據(jù)集來教計算機應該怎么做���,然后系統(tǒng)執(zhí)行該任務����。首先存在大數(shù)據(jù)→機器會學習使用訓練數(shù)據(jù)集來進行分類,調節(jié)特定的算法來實現(xiàn)目標分類→該計算機可學習識別數(shù)據(jù)中的關系����、趨勢和模式
④智能應用:智能應用使用人工智能所得到的結果,如圖是一個精準農業(yè)的應用案例示意��,該應用基于無人機所收集到的數(shù)據(jù)

5. 機器學習的實際應用
機器學習有很多應用場景�����,這里給出了一些示例�����,你會怎么使用它��?
快速三維地圖測繪和建模:要建造一架鐵路橋���,PwC 的數(shù)據(jù)科學家和領域專家將機器學習應用到了無人機收集到的數(shù)據(jù)上�����。這種組合實現(xiàn)了工作成功中的精準監(jiān)控和快速反饋�。
增強分析以降低風險:為了檢測內部交易,PwC 將機器學習和其它分析技術結合了起來���,從而開發(fā)了更為全面的用戶概況��,并且獲得了對復雜可疑行為的更深度了解���。
預測表現(xiàn)最佳的目標:PwC 使用機器學習和其它分析方法來評估 Melbourne Cup 賽場上不同賽馬的潛力。
二��、機器學習的演化

幾十年來����,人工智能研究者的各個「部落」一直以來都在彼此爭奪主導權?,F(xiàn)在是這些部落聯(lián)合起來的時候了嗎?他們也可能不得不這樣做�����,因為合作和算法融合是實現(xiàn)真正通用人工智能(AGI)的唯一方式�����。這里給出了機器學習方法的演化之路以及未來的可能模樣。
1. 五大流派
①符號主義:使用符號��、規(guī)則和邏輯來表征知識和進行邏輯推理��,最喜歡的算法是:規(guī)則和決策樹
②貝葉斯派:獲取發(fā)生的可能性來進行概率推理���,最喜歡的算法是:樸素貝葉斯或馬爾可夫
③聯(lián)結主義:使用概率矩陣和加權神經(jīng)元來動態(tài)地識別和歸納模式���,最喜歡的算法是:神經(jīng)網(wǎng)絡
④進化主義:生成變化,然后為特定目標獲取其中最優(yōu)的����,最喜歡的算法是:遺傳算法
⑤Analogizer:根據(jù)約束條件來優(yōu)化函數(shù)(盡可能走到更高,但同時不要離開道路)�,最喜歡的算法是:支持向量機
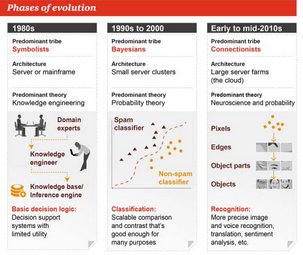
2. 演化的階段
1980 年代
主導流派:符號主義
架構:服務器或大型機
主導理論:知識工程
基本決策邏輯:決策支持系統(tǒng),實用性有限
1990 年代到 2000 年
主導流派:貝葉斯
架構:小型服務器集群
主導理論:概率論
分類:可擴展的比較或對比�����,對許多任務都足夠好了
2010 年代早期到中期
主導流派:聯(lián)結主義
架構:大型服務器農
主導理論:神經(jīng)科學和概率
識別:更加精準的圖像和聲音識別��、翻譯��、情緒分析等
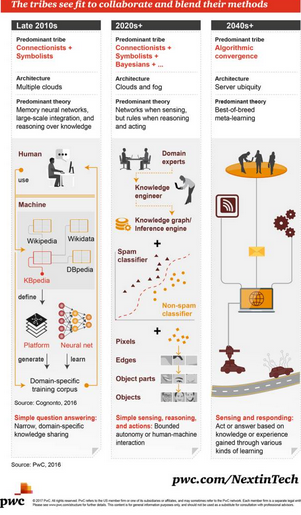
3. 這些流派有望合作�����,并將各自的方法融合到一起
2010 年代末期
主導流派:聯(lián)結主義+符號主義
架構:許多云
主導理論:記憶神經(jīng)網(wǎng)絡、大規(guī)模集成���、基于知識的推理
簡單的問答:范圍狹窄的����、領域特定的知識共享
2020 年代+
主導流派:聯(lián)結主義+符號主義+貝葉斯+……
架構:云計算和霧計算
主導理論:感知的時候有網(wǎng)絡�����,推理和工作的時候有規(guī)則
簡單感知�、推理和行動:有限制的自動化或人機交互
2040 年代+
主導流派:算法融合
架構:無處不在的服務器
主導理論:最佳組合的元學習
感知和響應:基于通過多種學習方式獲得的知識或經(jīng)驗采取行動或做出回答
三、機器學習的算法

你應該使用哪種機器學習算法���?這在很大程度上依賴于可用數(shù)據(jù)的性質和數(shù)量以及每一個特定用例中你的訓練目標。不要使用最復雜的算法���,除非其結果值得付出昂貴的開銷和資源��。這里給出了一些最常見的算法���,按使用簡單程度排序���。
1. 決策樹(Decision Tree):在進行逐步應答過程中,典型的決策樹分析會使用分層變量或決策節(jié)點���,例如�,可將一個給定用戶分類成信用可靠或不可靠����。
優(yōu)點:擅長對人、地點���、事物的一系列不同特征�����、品質���、特性進行評估
場景舉例:基于規(guī)則的信用評估、賽馬結果預測

2. 支持向量機(Support Vector Machine):基于超平面(hyperplane)�,支持向量機可以對數(shù)據(jù)群進行分類。
優(yōu)點:支持向量機擅長在變量 X 與其它變量之間進行二元分類操作��,無論其關系是否是線性的
場景舉例:新聞分類�、手寫識別����。
3. 回歸(Regression):回歸可以勾畫出因變量與一個或多個因變量之間的狀態(tài)關系�。在這個例子中,將垃圾郵件和非垃圾郵件進行了區(qū)分��。
優(yōu)點:回歸可用于識別變量之間的連續(xù)關系���,即便這個關系不是非常明顯
場景舉例:路面交通流量分析���、郵件過濾

4. 樸素貝葉斯分類(Naive Bayes Classification):樸素貝葉斯分類器用于計算可能條件的分支概率。每個獨立的特征都是「樸素」或條件獨立的�,因此它們不會影響別的對象。例如�,在一個裝有共 5 個黃色和紅色小球的罐子里,連續(xù)拿到兩個黃色小球的概率是多少�?從圖中最上方分支可見,前后抓取兩個黃色小球的概率為 1/10���。樸素貝葉斯分類器可以計算多個特征的聯(lián)合條件概率。
優(yōu)點:對于在小數(shù)據(jù)集上有顯著特征的相關對象���,樸素貝葉斯方法可對其進行快速分類
場景舉例:情感分析�����、消費者分類
5. 隱馬爾可夫模型(Hidden Markov model):顯馬爾可夫過程是完全確定性的——一個給定的狀態(tài)經(jīng)常會伴隨另一個狀態(tài)��。交通信號燈就是一個例子�����。相反���,隱馬爾可夫模型通過分析可見數(shù)據(jù)來計算隱藏狀態(tài)的發(fā)生���。隨后,借助隱藏狀態(tài)分析���,隱馬爾可夫模型可以估計可能的未來觀察模式�����。在本例中��,高或低氣壓的概率(這是隱藏狀態(tài))可用于預測晴天�����、雨天���、多云天的概率��。
優(yōu)點:容許數(shù)據(jù)的變化性�����,適用于識別(recognition)和預測操作
場景舉例:面部表情分析�、氣象預測
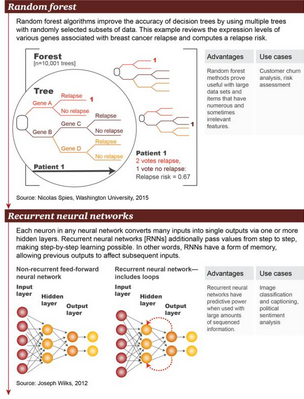
6. 隨機森林(Random forest):隨機森林算法通過使用多個帶有隨機選取的數(shù)據(jù)子集的樹(tree)改善了決策樹的精確性����。本例在基因表達層面上考察了大量與乳腺癌復發(fā)相關的基因,并計算出復發(fā)風險�����。
優(yōu)點:隨機森林方法被證明對大規(guī)模數(shù)據(jù)集和存在大量且有時不相關特征的項(item)來說很有用
場景舉例:用戶流失分析�、風險評估
7.
循環(huán)神經(jīng)網(wǎng)絡(Recurrent neural network):在任意神經(jīng)網(wǎng)絡中,每個神經(jīng)元都通過 1
個或多個隱藏層來將很多輸入轉換成單個輸出����。循環(huán)神經(jīng)網(wǎng)絡(RNN)會將值進一步逐層傳遞��,讓逐層學習成為可能。換句話說�,RNN
存在某種形式的記憶,允許先前的輸出去影響后面的輸入�����。
優(yōu)點:循環(huán)神經(jīng)網(wǎng)絡在存在大量有序信息時具有預測能力
場景舉例:圖像分類與字幕添加����、政治情感分析

8.
長短期記憶(Long short-term memory,LSTM)與門控循環(huán)單元神經(jīng)網(wǎng)絡(gated recurrent unit
nerual network):早期的 RNN
形式是會存在損耗的�����。盡管這些早期循環(huán)神經(jīng)網(wǎng)絡只允許留存少量的早期信息���,新近的長短期記憶(LSTM)與門控循環(huán)單元(GRU)神經(jīng)網(wǎng)絡都有長期與短期的記憶�����。換句話說�,這些新近的
RNN 擁有更好的控制記憶的能力�����,允許保留早先的值或是當有必要處理很多系列步驟時重置這些值,這避免了「梯度衰減」或逐層傳遞的值的最終
degradation����。LSTM 與 GRU
網(wǎng)絡使得我們可以使用被稱為「門(gate)」的記憶模塊或結構來控制記憶,這種門可以在合適的時候傳遞或重置值��。
優(yōu)點:長短期記憶和門控循環(huán)單元神經(jīng)網(wǎng)絡具備與其它循環(huán)神經(jīng)網(wǎng)絡一樣的優(yōu)點�����,但因為它們有更好的記憶能力�,所以更常被使用
場景舉例:自然語言處理、翻譯
9. 卷積神經(jīng)網(wǎng)絡(convolutional neural network):卷積是指來自后續(xù)層的權重的融合��,可用于標記輸出層��。
優(yōu)點:當存在非常大型的數(shù)據(jù)集�����、大量特征和復雜的分類任務時���,卷積神經(jīng)網(wǎng)絡是非常有用的
場景舉例:圖像識別���、文本轉語音����、藥物發(fā)現(xiàn)
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330