R文本分類之RTextTools
古有曹植七步成詩,而RTextTools是一款讓你可以在十步之內(nèi)實現(xiàn)九種主流的機器學習分類器模型的文本分類開發(fā)包��。
它集成了(或者說支持)如下算法相關的包:
支持向量機(Support Vector Machine from e1071)
glmnet(一個非常流行的用于變量選擇的R包�����,俗稱kaggle競賽“三駕馬車”之一)
最大熵模型(maximum entropy from maxent)
大規(guī)模線性判別(scaled linear discriminant,slda)
裝袋算法(bagging from ipred)
提升算法(boosting from caTools)
隨機森林(random forest from randomForest)
神經(jīng)網(wǎng)絡(neural networks from nnet)
回歸樹(regression tree from tree)
RTextTools有著不可不學的三大理由:
首先,RTextTools的設計哲學在于易學與靈活。從而����,讓沒有任何R編程經(jīng)驗的社會科學研究者也能輕松實現(xiàn)高端的機器學習算法�;并且��,讓經(jīng)驗老道的R用戶充分發(fā)揮R的威力,與其他相關的包結(jié)合,如:文本預處理方面的tm包���,實現(xiàn)LDA主題模型的topicmodels包等�����,實現(xiàn)高難度的模型�����,并且充分提高模型的精度等。
其次����,RTextTools提供了從數(shù)據(jù)載入,數(shù)據(jù)清洗�����,到模型評價的所有功能,并且,實現(xiàn)的函數(shù)非常簡單易記。即所謂的『一條龍服務』。
最后,RTextTools還可以實現(xiàn)結(jié)構(gòu)化數(shù)據(jù)的分類問題�。也就是說,它可以像普通的機器學習包caret那樣使用。
下面�����,讓我們一起來見證一下RTextTools是如何在十步之內(nèi)演繹文本分類這一高端技術活的。
文本分類step-by-step
1.創(chuàng)建矩陣
首先,載入一個自帶的測試數(shù)據(jù)集:data(USCongress)。由于RTextTools集成了tm包的功能���,所以tm包在文本預處理方面的功能��,如去除空格、移除稀疏詞、移除停止詞����、詞干化等功能��,都可以輕松實現(xiàn)。
library(RTextTools)data(USCongress)# 看看數(shù)據(jù)長啥樣str(USCongress)
## 'data.frame': 4449 obs. of 6 variables:## $ ID : int 1 2 3 4 5 6 7 8 9 10 ...## $ cong : int 107 107 107 107 107 107 107 107 107 107 ...## $ billnum : int 4499 4500 4501 4502 4503 4504 4505 4506 4507 4508 ...## $ h_or_sen: Factor w/ 2 levels"HR","S": 1 1 1 1 1 1 1 1 1 1 ...## $ major : int 18 18 18 18 5 21 15 18 18 18 ...## $ text : Factor w/ 4295 levels"-- Private Bill; For the relief of Alfonso Quezada-Bonilla.",..: 4270 4269 4273 4158 3267 3521 4175 4284 4246 4285 ...
# 創(chuàng)建一個文檔-詞項矩陣doc_matrix<-create_matrix(USCongress$text,language="english",removeNumbers=TRUE,stemWords=TRUE,removeSparseTerms=.998)
2.創(chuàng)建容器(Container)
創(chuàng)建好文檔-詞項矩陣以后����,下一步要做的就是對矩陣進行訓練集/測試集的劃分了。RTextTools中的容器(Container)概念��,使得人們不必兩次讀入數(shù)據(jù)���,而將訓練集和測試集一并讀入,在容器內(nèi)做區(qū)分即可�����。
既然我們是有監(jiān)督的分類算法實現(xiàn)���,當然不能忘了指定因變量(即類別標簽)�����。在我們的測試數(shù)據(jù)集中,類別標簽為USCongress$major��。
注意:類別標簽一定要為數(shù)值型�����!
container<-create_container(doc_matrix,USCongress$major,trainSize=1:4000,testSize=4001:4449,virgin=FALSE)# 看看類別個數(shù)length(unique(USCongress$major))
## [1] 20
這里����,virgin =參數(shù)的設置影響到后續(xù)模型結(jié)果的分析解讀���。virgin = FALSE意味著告訴R,我們的測試集是有真實的類別標簽的�����。
3.訓練模型
數(shù)據(jù)已經(jīng)準備妥當��,下面就可以進行模型的訓練了�����。前面提到的九個機器學習算法的訓練�����,只需要寫成一個向量�,作為參數(shù)傳入train_model()函數(shù)即可同時輕松實現(xiàn)各種高大上的分類器模型訓練�。
我們來看一下train_model()函數(shù)的使用方法。
train_model(container,algorithm=c("
SVM","SLDA","BOOSTING","BAGGING","RF","GLMNET","TREE","NNET","MAXENT"),method="C-classification",cross=0,cost=100,kernel="radial",maxitboost=100,maxitglm=10^5,size=1,maxitnnet=1000,MaxNWts=10000,rang=0.1,decay=5e-04,trace=FALSE,ntree=200,l1_regularizer=0,l2_regularizer=0,use_sgd=FALSE,set_heldout=0,verbose=FALSE,...)
參數(shù)的設置也很簡單���。如果你實在懶得設置,不妨先使用默認的參數(shù)試一試。
SVM<-train_model(container,"SVM")GLMNET<-train_model(container,"GLMNET")MAXENT<-train_model(container,"MAXENT")SLDA<-train_model(container,"SLDA")BOOSTING<-train_model(container,"BOOSTING")BAGGING<-train_model(container,"BAGGING")RF<-train_model(container,"RF")#NNET <- train_model(container,"NNET")TREE<-train_model(container,"TREE")
4.使用訓練好的模型進行文本分類
train_model()函數(shù)會返回一個訓練好的模型對象,我們可以把該對象作為參數(shù)傳給classify_model()函數(shù),進行測試集的分類�。
SVM_CLASSIFY<-classify_model(container,SVM)GLMNET_CLASSIFY<-classify_model(container,GLMNET)MAXENT_CLASSIFY<-classify_model(container,MAXENT)SLDA_CLASSIFY<-classify_model(container,SLDA)BOOSTING_CLASSIFY<-classify_model(container,BOOSTING)BAGGING_CLASSIFY<-classify_model(container,BAGGING)RF_CLASSIFY<-classify_model(container,RF)#NNET_CLASSIFY <- classify_model(container, NNET)TREE_CLASSIFY<-classify_model(container,TREE)
5.結(jié)果分析
create_analytics()函數(shù)提供了對測試集的分類結(jié)果的四種解讀:從標簽出發(fā);從算法對比出發(fā)��;從角度文檔出發(fā)���;以及整體評價。
analytics<-create_analytics(container,cbind(SVM_CLASSIFY,SLDA_CLASSIFY,BOOSTING_CLASSIFY,BAGGING_CLASSIFY,RF_CLASSIFY,GLMNET_CLASSIFY,TREE_CLASSIFY,MAXENT_CLASSIFY))
6.測試分類器準確率(accuracy)
create_analytics()返回的對象適用于summary()和print()方法�����。
summary(analytics)
## ENSEMBLE SUMMARY#### n-ENSEMBLE COVERAGE n-ENSEMBLE RECALL## n >= 1 1.00 0.77## n >= 2 1.00 0.77## n >= 3 0.99 0.78## n >= 4 0.90 0.82## n >= 5 0.76 0.87## n >= 6 0.62 0.90## n >= 7 0.46 0.93## n >= 8 0.24 0.96###### ALGORITHM PERFORMANCE####
SVM_PRECISION
SVM_RECALL
SVM_FSCORE## 0.6830 0.6530 0.6540## SLDA_PRECISION SLDA_RECALL SLDA_FSCORE## 0.6530 0.6375 0.6295## LOGITBOOST_PRECISION LOGITBOOST_RECALL LOGITBOOST_FSCORE## 0.5955 0.6005 0.5775## BAGGING_PRECISION BAGGING_RECALL BAGGING_FSCORE## 0.5465 0.3905 0.4005## FORESTS_PRECISION FORESTS_RECALL FORESTS_FSCORE## 0.6850 0.6365 0.6415## GLMNET_PRECISION GLMNET_RECALL GLMNET_FSCORE## 0.6840 0.6440 0.6415## TREE_PRECISION TREE_RECALL TREE_FSCORE## 0.2035 0.2160 0.1795## MAXENTROPY_PRECISION MAXENTROPY_RECALL MAXENTROPY_FSCORE## 0.6145 0.6325 0.6190
# 為分析結(jié)果建立一個數(shù)據(jù)框topic_summary<-analytics@label_summaryalg_summary<-analytics@algorithm_summaryens_summary<-analytics@ensemble_summarydoc_summary<-analytics@document_summary
summary(analytics)返回了精度(precision)���,召回率(recall)和F-值(F-Score)等指標�����。這三個指標是文本分類中常用的評價指標����。
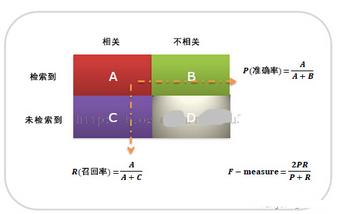
精度的定義為預測為真實正例的個數(shù)除以所有被預測為正例樣本的個數(shù)����。召回率則是預測為真實正例的個數(shù)除以所有真實正例樣本的個數(shù)�。F-值則同時考慮了精度和召回率�����,是兩個指標的折衷����。
7.整體效果評價(Ensemble agreement)
create_ensembleSummary()函數(shù)提供了整體評價功能。它反映了我們所應用的幾種分類算法的『同時命中率』��。
create_ensembleSummary(analytics@document_summary)
## n-ENSEMBLE COVERAGE n-ENSEMBLE RECALL## n >= 1 1.00 0.77## n >= 2 1.00 0.77## n >= 3 0.99 0.78## n >= 4 0.90 0.82## n >= 5 0.76 0.87## n >= 6 0.62 0.90## n >= 7 0.46 0.93## n >= 8 0.24 0.96
整體評價函數(shù)提供了兩個評價指標:Coverage和Recall����。
Coverage衡量了達到召回率閾值的文檔百分比。
Coverage的定義如下:
Coverage=kn
其中��,k表示滿足閾值的算法個數(shù)����,n代表總的算法個數(shù)。
8.交叉驗證
為了進一步對比與驗證各種算法的精確度���,我們可以使用cross_validate()函數(shù)進行k-折交叉驗證����。
SVM<-cross_validate(container,4,"SVM")GLMNET<-cross_validate(container,4,"GLMNET")MAXENT<-cross_validate(container,4,"MAXENT")SLDA<-cross_validate(container,4,"SLDA")BAGGING<-cross_validate(container,4,"BAGGING")BOOSTING<-cross_validate(container,4,"BOOSTING")RF<-cross_validate(container,4,"RF")NNET<-cross_validate(container,4,"NNET")TREE<-cross_validate(container,4,"TREE")
9.導出數(shù)據(jù)
最后,可以導出結(jié)果��,對未正確標簽的文檔做進一步研究處理�。比如,看看是哪種情形下��,分類算法準確率較低���,需要人工干預。
write.csv(analytics@document_summary,"DocumentSummary.csv")
結(jié)論
至此���,文本分類的『獨孤九劍』已然練成���!然而,長路漫漫�,我們要想提高模型的精度,還需要『勤修內(nèi)功』����,進一步學習模型的細節(jié),加深對模型的理解�����,從而學會調(diào)節(jié)各種參數(shù),進行噪音過濾�,模型調(diào)整等。否則��,只怕是『Garbage in, Garbage out』了��。數(shù)據(jù)分析師培訓
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330