如何在R語言中使用Logistic回歸模型
在實際應(yīng)用中����,Logistic模型主要有三大用途:
1)尋找危險因素,找到某些影響因變量的"壞因素"���,一般可以通過優(yōu)勢比發(fā)現(xiàn)危險因素�����;
2)用于預(yù)測���,可以預(yù)測某種情況發(fā)生的概率或可能性大?��。?
3)用于判別����,判斷某個新樣本所屬的類別。
Logistic模型實際上是一種回歸模型���,但這種模型又與普通的線性回歸模型又有一定的區(qū)別:
1)Logistic回歸模型的因變量為二分類變量��;
2)該模型的因變量和自變量之間不存在線性關(guān)系���;
3)一般線性回歸模型中需要假設(shè)獨立同分布、方差齊性等���,而Logistic回歸模型不需要��;
4)Logistic回歸沒有關(guān)于自變量分布的假設(shè)條件�,可以是連續(xù)變量、離散變量和虛擬變量��;
5)由于因變量和自變量之間不存在線性關(guān)系�,所以參數(shù)(偏回歸系數(shù))使用最大似然估計法計算。
下面簡單介紹該模型的理論知識��,主要參考《統(tǒng)計建模與R軟件》:

應(yīng)用:
接下來使用R語言實現(xiàn)Logistic模型的應(yīng)用����,仍然使用《Logistic回歸模型——方法與應(yīng)用》書中的案例數(shù)據(jù)。該數(shù)據(jù)的應(yīng)變量表示高中生是否進(jìn)入大學(xué)���,自變量包含性別(GENDER)�����、高中類型(KEYSCH,是否為重點中學(xué))和高中平均成績(MEANGR)�。
接下來列出文中所需R語言包:
foreign包用于導(dǎo)入SPSS數(shù)據(jù)集;
sjmisc包用于實現(xiàn)Logistic模型的擬合優(yōu)度檢驗
pROC包用于繪制模型的ROC曲線
#讀取數(shù)據(jù)
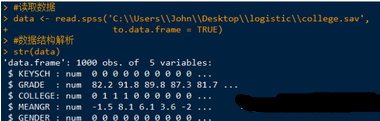
發(fā)現(xiàn)原本為離散的變量COLLEGE���、KEYSCH和GENDER成了數(shù)值變量�����,需要重新將這些變量設(shè)置為因子變量�。
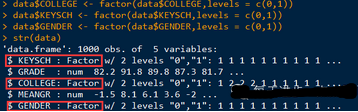
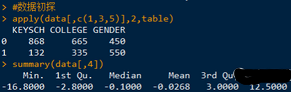
#數(shù)據(jù)初探:
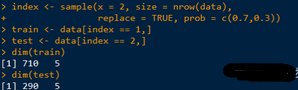
#將數(shù)據(jù)拆分為訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集
本文對Logistic模型的應(yīng)用使用stats包中自帶的glm()函數(shù),下面看看
glm()函數(shù)的使用方法:
glm(formula, family = gaussian, data, weights, subset,
na.action, start = NULL, etastart, mustart, offset,
control = list(...), model = TRUE, method = "glm.fit",
x = FALSE, y = TRUE, contrasts = NULL, ...)
formula指定模型的因變量和自變量����,類似于y~x1+x2+x3的形式;
family指定模型的連接函數(shù)和誤差函數(shù)���;
data指定要分析的數(shù)據(jù)框�����;
weights模型擬合中指定先驗權(quán)重����;
subset指定數(shù)據(jù)子集用于模型擬合���;
na.action指定缺失值的處理辦法�����,默認(rèn)跳過缺失值�����;
start用于指定參數(shù)估計的初始值��;
control為一個列表���,指定廣義線性模型的收斂度�,最大迭代次數(shù)等����;
#建模
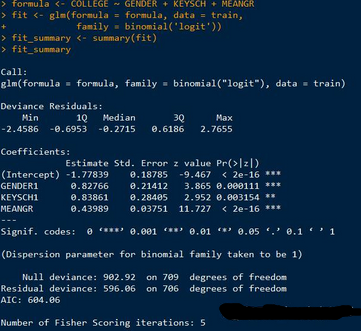
由參數(shù)估計的結(jié)果可知,截距項和三個自變量是非常顯著的���。
從而模型可以寫成如下形式:

由summary()結(jié)果的最下方Residual deviance實際上就是-2Log L(-2倍的似然對數(shù))對應(yīng)模型的顯著性檢驗����。也可以查看更詳細(xì)的Residual deviance過程:
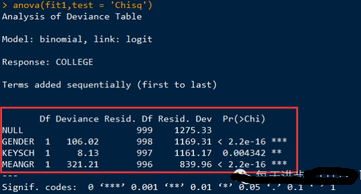
很明顯�����,模型卡方統(tǒng)計量通過顯著性檢驗(P值遠(yuǎn)遠(yuǎn)小于0.05)����。
模型的擬合優(yōu)度檢驗:
通過比較模型的預(yù)測值與實際值之間的差異情況來進(jìn)行檢驗�����,如果預(yù)測值域?qū)嶋H值越接近,則說明模型的擬合優(yōu)度越佳�����。
主要的擬合優(yōu)度評價指標(biāo)有偏差卡方檢驗�����、皮爾遜卡方檢驗和HL統(tǒng)計量檢驗����。其中前兩種檢驗適合模型中只有離散的自變量,而后一種適合模型中包含連續(xù)的自變量�。擬合優(yōu)度檢驗的原假設(shè)為“模型的預(yù)測值與實際值不存在差異”。
下面使用sjmisc包中的hoslem_gof函數(shù)實現(xiàn)以上模型的H-L統(tǒng)計量檢驗:
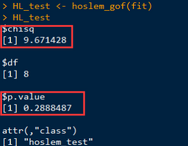
很明顯�����,p>0.05���,說明H-L檢驗不顯著���,接受擬合優(yōu)度的原假設(shè):模型的預(yù)測值與實際值不存在差異����。
在實際應(yīng)用中���,最理想的情況是希望模型卡方統(tǒng)計量顯著(Residual deviance顯著)�,而模型擬合優(yōu)度不顯著(HL統(tǒng)計量不顯著)��。如果Residual deviance不顯著(自變量對應(yīng)變量沒有很好的解釋)或HL統(tǒng)計量顯著(模型不能很好的擬合數(shù)據(jù))�,則說明模型可能存在某些問題,需要重新設(shè)定模型��。
從上面的HL檢驗和模型卡方統(tǒng)計量結(jié)果可知����,該模型是比較理想的。
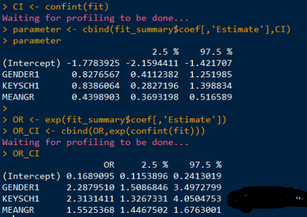
#我們一般不會直接對模型的偏回歸系數(shù)作解釋���,而是使用優(yōu)勢比解釋各個自變量����。下面看一下各回歸系數(shù)的置信區(qū)間和優(yōu)勢比的置信區(qū)間���。
#模型預(yù)測
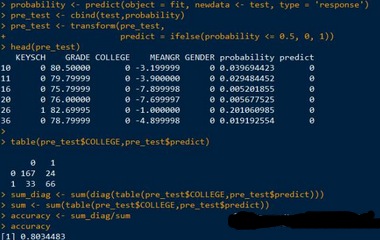
由于Logistic回歸模型無法直接預(yù)測新樣本屬于哪個類別��,這里使用主觀概念����,如果預(yù)測概率值小于等于0.5�����,則預(yù)判COLLEGE為0(未考取大學(xué))�。經(jīng)計算模型的預(yù)測準(zhǔn)確率為80%。
還有一種可視化的方法衡量模型的優(yōu)劣�����,即ROC曲線����,該曲線的橫坐標(biāo)和縱坐標(biāo)各表示1-反例的覆蓋率和正例的覆蓋率。
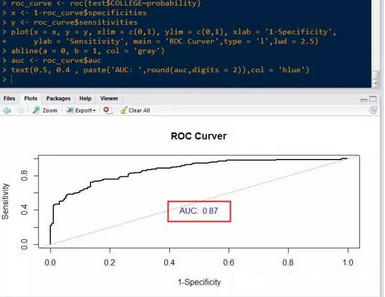
這里的AUC為ROC曲線下方的面積��。一般AUC大于0.75就能夠說明模型是比較合理的了��。
總結(jié):文中所用到的包和函數(shù)
foreign包
read.spss()
stats包
glm()
summary()
confint()
predict()
transform()
cbind()
table()
sjmisc包
hoslem()
pROC包
roc()
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫��,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330