異常檢測的數(shù)據(jù)挖掘方法
我們正淹沒在從世界范圍內(nèi)收集的海量的數(shù)據(jù)里,同時(shí)我們也渴求知識(shí)
異常事件發(fā)生相對(duì)較少
然而,一旦發(fā)生��,它們的影響將會(huì)很戲劇性,并且通常具有負(fù)面影響

"在草堆中找針�����,草是如些多�����,時(shí)間如此少"
什么是異常��?
異常是數(shù)據(jù)中不滿足期望行為的模式
也指離群點(diǎn),異常值��,特異性��,驚奇性等
異常與現(xiàn)實(shí)生活中的實(shí)體對(duì)應(yīng)
--網(wǎng)絡(luò)入侵
--信用卡欺詐
--機(jī)械系統(tǒng)中的缺陷
真實(shí)世界中的異常
信用卡欺詐
-信用卡上的費(fèi)用異常高的定單
網(wǎng)絡(luò)入侵
-與FTP流量相關(guān)的WEB服務(wù)器
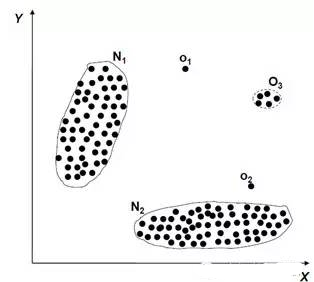
簡單例子
N1和N2是正常行為范
點(diǎn)o1和o2是異常點(diǎn)
在區(qū)域O3中的點(diǎn)也是異常點(diǎn)
相關(guān)的問題
稀有類挖掘
發(fā)現(xiàn)機(jī)會(huì)
新奇事物檢測
異常挖掘
消除噪聲
黑天鵝
關(guān)鍵的挑戰(zhàn)
定義一個(gè)具有代表性的正常區(qū)域很有挑戰(zhàn)性
正常行為與邊遠(yuǎn)行為的界限通常是不精確的
標(biāo)記數(shù)據(jù)對(duì)于訓(xùn)練驗(yàn)證的有效性
異常的精確定義在不同的應(yīng)用領(lǐng)域是不一樣的
惡意的敵人
數(shù)據(jù)可能包含噪聲
正常行為不斷在演變
相關(guān)特征的適當(dāng)選擇
Aspects of Anomaly Detection Problem(異常檢測問題的方面)
輸入數(shù)據(jù)的性質(zhì)
略���。
指導(dǎo)的有效性
略����。
異常類型
點(diǎn)異常
單獨(dú)的數(shù)據(jù)實(shí)例是異常的
上下文異常
在一個(gè)上下文中單獨(dú)的數(shù)據(jù)實(shí)例是異常的
需要一個(gè)上下文的概念
也被稱為條件異常

集體異常
相關(guān)數(shù)據(jù)實(shí)例的集體是異常的
在數(shù)據(jù)實(shí)例間需要一個(gè)關(guān)系
-有序數(shù)據(jù)
-空間數(shù)據(jù)
-圖數(shù)據(jù)
在一個(gè)集體異常中單獨(dú)的實(shí)例�,從它們自己看來并不是異常的
異常檢測的輸出
標(biāo)記
-每一個(gè)測試實(shí)例給一個(gè)正常或異常的標(biāo)記
-對(duì)基于分類的方法特別適用
得分
-每一個(gè)測試實(shí)例分配一個(gè)異常得分
允許排序輸出
需要一個(gè)附加的閥值參數(shù)
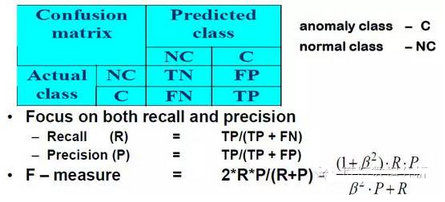
異常檢測技術(shù)的評(píng)估-F值
準(zhǔn)確率對(duì)于評(píng)估來講并不是充分的度量
-舉例:網(wǎng)絡(luò)流量數(shù)據(jù)集��,具有99.9%的正常數(shù)據(jù)和0.1%的入侵?jǐn)?shù)據(jù)
-簡單的分類器(使用正常類型標(biāo)記)可以達(dá)到99.9%的準(zhǔn)確率
Applications(應(yīng)用)
網(wǎng)絡(luò)入侵檢測
保險(xiǎn)/信用卡欺詐檢測
醫(yī)療信息/醫(yī)學(xué)診斷
工業(yè)損傷檢測
圖像處理/視頻監(jiān)控
文本挖掘中的小說主題檢測
Different Types of Anomaly Detection Techniques(異常檢測技術(shù)的不同類型)
基于分類的技術(shù)
有指導(dǎo)的分類技術(shù)
半指導(dǎo)的分類技術(shù)
優(yōu)勢:
(1)有指導(dǎo)分類技術(shù)
模型好理解
在檢測已經(jīng)多類型的異常時(shí)�,具有較高的精度
(2)半指導(dǎo)分類技術(shù)
模型好理解
正常行為能夠精確地學(xué)習(xí)
劣勢:
(1)有指導(dǎo)分類技術(shù)
需要正常與異常類型的兩種標(biāo)簽數(shù)據(jù)
不能檢測未知新出現(xiàn)的異常
(2)半指導(dǎo)分類技術(shù)
需要正常類型的標(biāo)簽數(shù)據(jù)
對(duì)未使用的正常數(shù)據(jù)���,也可能以高的概率識(shí)別為異常
有指導(dǎo)的分類技術(shù)
操作數(shù)據(jù)記錄(過抽樣/欠抽樣/人工產(chǎn)生異?��!維MOTE】)
基于規(guī)則的技術(shù)【PN-rule, CREDOS】
基于模型的技術(shù)
基于神經(jīng)網(wǎng)絡(luò)的方法
基于支持向量機(jī)的方法
基于貝葉斯網(wǎng)絡(luò)的方法
代價(jià)敏感的分類技術(shù)
基于總體的算法(SMOTEBoost,RareBoost����,MetaCost)
半指導(dǎo)的分類技術(shù)
基于神經(jīng)網(wǎng)絡(luò)的方法
基于支持向量機(jī)的方法
基于馬爾可夫模型的方法
基于規(guī)則的方法
基于最近鄰技術(shù)
重要假設(shè):正常點(diǎn)有近鄰,而異常點(diǎn)離其它點(diǎn)很遠(yuǎn)
通常兩步方法
1、計(jì)算每個(gè)數(shù)據(jù)記錄的鄰居
2�����、分析鄰居決定數(shù)據(jù)記錄是否異常
分類:
基于距離的方法:異常點(diǎn)是那些離其它點(diǎn)最遠(yuǎn)的點(diǎn)
基于密度的方法:異常點(diǎn)是處于低密度區(qū)域的點(diǎn)
優(yōu)勢:
可用于無指導(dǎo)或半指導(dǎo)的情形中(對(duì)數(shù)據(jù)的分布無任何假設(shè))
劣勢:
如果正常點(diǎn)沒有充足的鄰居數(shù)量��,該技術(shù)可能會(huì)失敗
運(yùn)算量
在高維空間中�,數(shù)據(jù)是稀疏的,相似性的概念也許不再有意義了�。由于稀疏性,兩個(gè)數(shù)據(jù)記錄之間的距離也許變得很相似����,這樣每個(gè)數(shù)據(jù)記錄也許會(huì)作為潛在的異常點(diǎn)被考慮
基于密度的方法
局部異常因子(LOF,Local Outlier Factor)
連接異常因子(COF,Connectivity Outlier Factor)
多粒度偏差因子(MDEF,Multi-Granularity Deviation Factor)LOCI
基于聚類的技術(shù)
主要假設(shè):
正常數(shù)據(jù)屬于大的稠密的聚類,而異常數(shù)據(jù)不屬性于任何有效的聚類
常用方法:
將數(shù)據(jù)聚成有限數(shù)量的聚類
至于它的最近的聚類���,分析每一個(gè)數(shù)據(jù)實(shí)例
異常實(shí)例:
不符合任何聚類的數(shù)據(jù)實(shí)例
小聚類數(shù)據(jù)實(shí)例
低密度數(shù)據(jù)實(shí)例
在同一個(gè)聚類中�,離其它點(diǎn)很遠(yuǎn)的數(shù)據(jù)實(shí)例
優(yōu)勢:
無指導(dǎo)算法
存在的聚類算法可以被接入
劣勢:
如果數(shù)據(jù)沒有自然的聚類或聚類算法不能檢測自然的聚類���,該技術(shù)將失效
運(yùn)算量大:使用索引結(jié)構(gòu)也許會(huì)減輕該問題
在高維空間中����,數(shù)據(jù)是稀疏的�����,兩個(gè)數(shù)據(jù)記錄間的距離也許會(huì)變得也很似
FindOut算法作為小波聚類(WaveCluster)的副產(chǎn)品
使用小波變換將數(shù)據(jù)轉(zhuǎn)換成多維信號(hào)
高頻信息符合聚類的分布邊界快速改變的區(qū)域
低頻部分符合數(shù)據(jù)集中的區(qū)域
移除這些高頻和低頻部分,所有剩下的點(diǎn)就是異常點(diǎn)
使用聚類進(jìn)行異常檢測
固定寬度的聚類首先被應(yīng)用
第一個(gè)點(diǎn)是第一個(gè)聚類的中心
如果d(x1,x2)<=w����,那么x1和x2是靠近的,其中w是用戶定義的參數(shù)
如果每個(gè)隨后的點(diǎn)是靠近的�����,增加到一個(gè)類�,否則創(chuàng)建一個(gè)新的類
那些在小聚類中的點(diǎn)就是異常點(diǎn)
基于聚類的局部異常因子CBLOF
使用擠壓聚類算法執(zhí)行聚類
為每一個(gè)數(shù)據(jù)實(shí)例確定CBLOF
如果數(shù)據(jù)記錄位于小聚類中,CBLOF=聚類的大小*該數(shù)據(jù)實(shí)例與最近的更大一點(diǎn)聚類的距離
如果數(shù)據(jù)記錄位于大數(shù)據(jù)中��,CBLOF=聚類的大小*該數(shù)據(jù)實(shí)例與該數(shù)據(jù)實(shí)例所屬聚類的距離
基于統(tǒng)計(jì)的技術(shù)
主要假設(shè):正常數(shù)據(jù)實(shí)例發(fā)生在統(tǒng)計(jì)分布的高概率區(qū)域�����,然而異常發(fā)生在統(tǒng)計(jì)分布的低密度區(qū)別
常用方法:使用給定的數(shù)據(jù)估計(jì)一個(gè)統(tǒng)計(jì)分布���,然后應(yīng)用一個(gè)統(tǒng)計(jì)推斷檢測來確定該檢驗(yàn)的實(shí)例是否屬性該分布
如果一個(gè)觀測離樣本的平均值超過3倍標(biāo)準(zhǔn)差,那么它就是異常的
優(yōu)勢:
利用現(xiàn)有統(tǒng)計(jì)建模技術(shù)對(duì)不同的分布類型建模
提供一種統(tǒng)計(jì)上合理的解決方案來檢測異常值
劣勢:
由于具有高維度�����,進(jìn)行參數(shù)估計(jì)同時(shí)構(gòu)建假設(shè)檢驗(yàn)是很難的
假設(shè)的參數(shù)對(duì)真實(shí)數(shù)據(jù)未必有效
統(tǒng)計(jì)技術(shù)的類型
參數(shù)技術(shù)
假設(shè)正常數(shù)據(jù)(也有可能異常)產(chǎn)生自一個(gè)潛在的參數(shù)分布
從訓(xùn)練樣本中學(xué)習(xí)參數(shù)
非參數(shù)技術(shù)
不會(huì)假設(shè)參數(shù)的任何知識(shí)
使用非參技術(shù)估計(jì)分布的密度
SmartSifter(SS)
具有連續(xù)與分類屬性數(shù)據(jù)的統(tǒng)計(jì)建模
直方圖密度用于表示分類屬性的概率密度
有限混合模型用于表示連續(xù)屬性的概率密度
對(duì)于一個(gè)測試實(shí)例,SS估計(jì)了由學(xué)習(xí)統(tǒng)計(jì)模型產(chǎn)生的測試實(shí)例的概率p(t-1)
接著����,測試實(shí)例被加入樣本,然后該模型將重新估計(jì)
由新模型產(chǎn)生的測試實(shí)例的概率為p(t)
對(duì)于測試實(shí)例的異常得分是|p(t)-p(t-1)|
對(duì)正常與異常數(shù)據(jù)建模
如下給出數(shù)據(jù)D的分布:
D=(1-x)*M+x*A
M代表主體分布�;A代表異常分布
M,A分別代表正常與異常元素的集合
第1步:將所有的實(shí)例賦值給M�����,A初始化為空
第2步:對(duì)每個(gè)M中的實(shí)例xi
(1)估計(jì)M和A的參數(shù)
(2)計(jì)算分布D的log似然函數(shù)L
(3)從M中移走x�,并且插入A
(4)重新估計(jì)M和A的參數(shù)
(5)計(jì)算分布D的log似然函數(shù)L'
(6)如果L'-L>a,那么x是異常值����,否則從M中移除x
第3步:回到第2步
基于信息理論的技術(shù)
重要假設(shè):異常值顯著地改變了數(shù)據(jù)集的信息內(nèi)容
常用方法:檢測能夠顯著改變信息內(nèi)容的數(shù)據(jù)實(shí)例
--需要一個(gè)信息理論度量
優(yōu)勢:
可以在一個(gè)無指導(dǎo)的模式下操作
劣勢:
需要一個(gè)足夠敏感的信息理論度量來檢測由少數(shù)異常引起的不規(guī)則性
使用熵
找一個(gè)k大小的數(shù)據(jù)子集,該子集的移出�,將導(dǎo)致整個(gè)數(shù)據(jù)集熵的最大減少
使用一個(gè)近似的線性查找算法以直線性的方式搜索k大小的子集
其它的信息理論度量已經(jīng)被研究了,比如條件熵���、相對(duì)條件熵�、信息增益��,等等
光譜技術(shù)
基于數(shù)據(jù)特征分解的分析
關(guān)鍵思想:
找到能夠捕捉大部分變化的屬性組合
屬性的縮減集能夠?qū)⒄5臄?shù)據(jù)解釋得很好�,對(duì)于異常數(shù)據(jù)卻不是必要的
優(yōu)勢:
在非指導(dǎo)模式下可以操作
劣勢:
它是基于這樣的假設(shè)�,即異常和正常的實(shí)例在縮減后的空間中是可區(qū)分的
使用穩(wěn)健的主成份分析
計(jì)算數(shù)據(jù)集的主成分
對(duì)每個(gè)測試的點(diǎn)�,計(jì)算它在這些主成份下的投影
如果yi表示第i個(gè)主成份,那么如下有一個(gè)卡方分布
sum(<i=1,q>,yi^2/ai)=y1^2/a1+y2^2/a2+y3^2/a3+...+yq^2/aq,q<=p
如果對(duì)于一個(gè)給定的顯著水平��,滿足如下條件�����,那么這個(gè)觀測是異常的:
sum(<i=1,q>,yi^2/ai)>kfq^2(b)
另外一個(gè)觀察最后幾個(gè)主成份的度量是
sum(<i=p-r+1,p>,yi^2/ai)
對(duì)于以上的度量�����,異常點(diǎn)具有較高的值
PCA用于異常檢測
一些主要的主成份����,捕獲了普通數(shù)據(jù)的可變性
最小的主成份對(duì)普通數(shù)據(jù)來說,應(yīng)該有的常量值
異常值在最小的主成份中有變異性
使用PCA進(jìn)行網(wǎng)絡(luò)入侵檢測
-對(duì)每個(gè)時(shí)間t,計(jì)算主成份
-隨時(shí)間����,堆積所有的主成份,形成一個(gè)矩陣
-矩陣的左奇異向量捕獲了正常行為
-對(duì)于任意的t,主成份與奇異向量間的角度給出了異常度
基于可視化的技術(shù)
使用可視化工具觀察數(shù)據(jù)
為人工檢查提供數(shù)據(jù)的替代視圖
更形象地發(fā)現(xiàn)異常點(diǎn)
優(yōu)勢
-圈定一個(gè)人
劣勢
-對(duì)低維數(shù)據(jù)表現(xiàn)較好
-對(duì)于高維數(shù)據(jù)�����,在聚合或部分視圖中����,異常值也許是不可區(qū)分的
-對(duì)于實(shí)時(shí)異常檢測不合適
可視化數(shù)據(jù)挖掘
檢測電信欺詐
用圖展現(xiàn)電話呼叫模式
用顏色標(biāo)記出欺騙性的電話呼叫(異常)
上下文異常檢測
檢測上下文異常
重要假設(shè):在一個(gè)上下文內(nèi)的所有正常實(shí)例是彼此相似的(在行為屬性方面),然而在同一個(gè)上下文中����,異常實(shí)例與其它實(shí)例不同
常用方法:
-圍繞一個(gè)數(shù)據(jù)實(shí)例,確定一個(gè)上下文(使用上下文屬性的集合)
-確定測試數(shù)據(jù)在上下文中是否是異常值(使用行為屬性集合)
優(yōu)勢:
-當(dāng)在全局視圖下分析時(shí)���,可以檢測那些很難發(fā)現(xiàn)的異常值
劣勢:
-確定一個(gè)好的上下文屬性的集合
-使用上下文屬性確定一個(gè)上下文
上下文屬性
上下文屬性為每個(gè)實(shí)例定義了一個(gè)鄰居(上下文)
舉例:
-空間上下文:經(jīng)度�、緯度
-圖上下文:邊���、權(quán)重
-有序上下文:位置�、時(shí)間
-輪廓上下文:用戶的人口統(tǒng)計(jì)資料
上下文異常檢測技術(shù)
減少異常點(diǎn)檢測
-使用上下文屬性的分段數(shù)據(jù)
-使用行為屬性在每一個(gè)上下文中應(yīng)用一個(gè)傳統(tǒng)的離群點(diǎn)異常
-通常�,上下文檢測 不能輕易地分段
利用結(jié)構(gòu)數(shù)據(jù)
-使用上下文屬性,從數(shù)據(jù)中建立模型
-關(guān)于它們的上下文�,模型自動(dòng)地分析數(shù)據(jù)實(shí)例
條件異常檢測
每個(gè)數(shù)據(jù)點(diǎn)表示為[x,y],這里的x表示上下文屬性����,y表示行為屬性
nU高斯模型的混合,U從上下文數(shù)據(jù)學(xué)習(xí)而來
nV高斯模型的混合����,V從行為數(shù)據(jù)學(xué)習(xí)而來
p(Vj|Ui)表示�,當(dāng)上下文部分由Ui產(chǎn)生時(shí)��,行為部分由Vj產(chǎn)生的概率
一個(gè)數(shù)據(jù)實(shí)例[x,y]的異常得分:
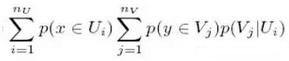
集體異常檢測
檢測集體的異常值
挖掘數(shù)據(jù)實(shí)例間的關(guān)系
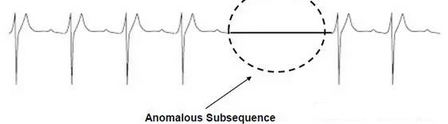
序列異常檢測
-檢測異常序列
空間異常檢測
-在一個(gè)空間數(shù)據(jù)集中檢測異常子區(qū)域
圖的異常檢測
-在圖數(shù)據(jù)中檢測異常子圖
序列異常檢測
多個(gè)子規(guī)則
-在序列數(shù)據(jù)庫中檢測異常序列
-在一個(gè)序列中�,檢測異常子序列
提綱
問題陳述
技術(shù)
-- 基于核函數(shù)的技術(shù)
-- 基于窗口的技術(shù)
-- 馬爾可夫鏈的技術(shù)
實(shí)驗(yàn)評(píng)價(jià)
-- 實(shí)驗(yàn)方法
-- 數(shù)據(jù)集
-- 人工數(shù)據(jù)生成器
-- 結(jié)果
結(jié)論
動(dòng)機(jī)和問題陳述
用于符號(hào)序列的幾個(gè)異常檢測技術(shù)已經(jīng)被提出來了
-每個(gè)被提出的技術(shù)用于一個(gè)單獨(dú)的應(yīng)用領(lǐng)域
-對(duì)于跨領(lǐng)域的技術(shù)沒有比較的評(píng)估
-這種評(píng)估對(duì)于區(qū)別技術(shù)的相對(duì)優(yōu)劣勢是必要的
問題陳述:給定一個(gè)具有n個(gè)序列的集合S,和一個(gè)查詢序列Sq���,為Sq找到一個(gè)關(guān)于S的異常得分
-在S中的序列假設(shè)是(或者大部分)正常的
該定義在如下的多領(lǐng)域是適用的
--飛行安全
--系統(tǒng)調(diào)用入侵檢測
--蛋白質(zhì)組����,蛋白質(zhì)組學(xué)
基于核函數(shù)的技術(shù)
定義序列間的一個(gè)相似核函數(shù)
--曼哈頓距離-對(duì)不同長度的序列不適用
--規(guī)范化最長共同序列
應(yīng)用任何基于傳統(tǒng)距離的異常檢測技術(shù)
-CLUSTER
將普通序列聚成一個(gè)固定個(gè)數(shù)的聚類
測試序列的異常得分是與離它最近聚類中心相似性的倒數(shù)
-KNN
測試序列的異常得分是在普通序列數(shù)據(jù)中離它第k個(gè)最近鄰居的相似性的倒數(shù)
基于窗口的技術(shù)(tSTIDE)
從測試序列中抽取有限長度的滑動(dòng)窗口
對(duì)每一個(gè)滑動(dòng)窗口�,找到它在訓(xùn)練數(shù)據(jù)集中的頻率
-對(duì)于滑動(dòng)窗口來說,頻率代表異常得分的倒數(shù)
組合每個(gè)窗口異常得分的異常得分�����,為測試序列得到全局的異常得分
馬爾可夫鏈的技術(shù)
基于之前觀察事件的條件��,估計(jì)測試序列的每個(gè)事件發(fā)概率
組合每個(gè)事件的概率獲得全局異常的得分
FSA
--事件概率是基于前L-1事件條件下的概率
--如果前L-1事件沒有訓(xùn)練數(shù)據(jù)集中發(fā)生���,該事件將被忽略
FSA-z
和FSA一樣��,只是當(dāng)前L-1事件未發(fā)生在訓(xùn)練數(shù)據(jù)中時(shí)���,該事件的概率為0
PST
-如果前L-1事件在訓(xùn)練集中未發(fā)生足夠的次數(shù),它們將會(huì)被最大的suffix替代��,這里的suffix發(fā)生的次數(shù)超過了需要的閥值
Ripper
如果前L-1事件在訓(xùn)練集中未發(fā)生足夠的次數(shù)��,它將會(huì)被最大的subset替代����,這里的subset發(fā)生的次數(shù)超過了需要的閥值
HMM
事件的概率,等于從訓(xùn)練集的學(xué)習(xí)生成的HMM中的相應(yīng)的轉(zhuǎn)移概率
在線異常檢測
通常數(shù)據(jù)以流式的方式傳達(dá)
應(yīng)用
--視頻分析
--網(wǎng)絡(luò)流量監(jiān)控
--飛行安全
--信用卡欺詐交易
挑戰(zhàn)
異常需實(shí)時(shí)檢測
什么時(shí)候拒絕�����?
什么時(shí)候更新�?
-周期性地更新-一段固定的時(shí)間周期之后,模型更新
-插入每條數(shù)據(jù)記錄�����,增量更新
需要增量建模更新技術(shù)重要訓(xùn)練模型�����,會(huì)很昂貴
-被動(dòng)更新-模型只有當(dāng)被需要的時(shí)候才會(huì)更新
模型更新的動(dòng)機(jī)
如果正在到達(dá)的數(shù)據(jù)點(diǎn)開始創(chuàng)建一個(gè)新的數(shù)據(jù)聚類��,該方法將不能檢測這些點(diǎn)為異常點(diǎn)
增量的LOF和COF
增量LOF算法
-增量的LOF算法為每條插入的數(shù)據(jù)記錄計(jì)算LOF值,并且立即決定是否該數(shù)據(jù)實(shí)例是一個(gè)異常點(diǎn)
-如果有必要的話�,根據(jù)已存在的數(shù)據(jù)記錄更新LOF值
增量COF算法
-為每個(gè)插入的數(shù)據(jù)記錄計(jì)算COF值
-需要的話,更新ac-dist
分布式異常檢測的必要性
在諸多異常檢測應(yīng)用中的數(shù)據(jù)來源不同
-網(wǎng)絡(luò)入侵檢測
-信用卡欺詐
-航空安全
同時(shí)發(fā)生在多位置失敗�,也許僅分析單獨(dú)一個(gè)位置的數(shù)據(jù)并不能檢測出來
-在如此復(fù)雜的系統(tǒng)中檢測異常也許需要來自于單個(gè)位置的檢測異常的信息集成,以在一個(gè)復(fù)雜系統(tǒng)全局水平上檢測異常
用于異常相關(guān)和集成的高性能和分布式算法是必要的
分布式異常檢測技術(shù)
簡單的數(shù)據(jù)交換方法
-將數(shù)據(jù)融合到一個(gè)位置
-在分布式的位置間交換數(shù)據(jù)
分布式的近鄰方法
-每一次距離計(jì)算交換一條數(shù)據(jù)記錄-計(jì)算效率低下
-基于跨站點(diǎn)距離計(jì)算的隱私保護(hù)異常檢測算法
基于模型交換的方法
-探索合適的統(tǒng)計(jì)或數(shù)據(jù)挖掘模型的交換�,以致能描述正常或異常的行為
---區(qū)別普通行為的模式
---使用統(tǒng)計(jì)或數(shù)據(jù)挖掘學(xué)習(xí)模型描述這些模式
---跨多位置交換模型����,在每一個(gè)的位置進(jìn)行組合,以檢測出全局的異常點(diǎn)
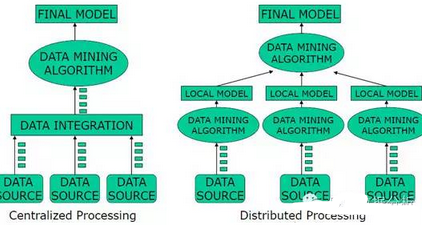
集中式和分布式體系架構(gòu)
分布式異常檢測算法
參數(shù)
-基于分布
-基于圖
-基于深度
非參
-基于密度
-基于聚類
半?yún)?
-基于模型(ANN,SVM)
Case Study(案例研究)
略�。
Discussion and Conclusions(討論和結(jié)論)
異常檢測能夠在數(shù)據(jù)中檢測出危急信息(臨界信息)
在多個(gè)應(yīng)用領(lǐng)域非常適用
異常檢測問題的本質(zhì)依賴于某個(gè)應(yīng)用領(lǐng)域
需要不同的方法來解決一個(gè)特定問題的制定
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330