如何通過(guò)數(shù)據(jù)挖掘手段分析網(wǎng)民的評(píng)價(jià)內(nèi)容
近年來(lái)微博等用戶(hù)自媒體的爆炸式增長(zhǎng)��,使得利用計(jì)算機(jī)挖掘網(wǎng)民意見(jiàn)不但變得可行����,而且變得必須�����。這其中很重要的一項(xiàng)任務(wù)就是挖掘網(wǎng)民意見(jiàn)所討論的對(duì)象���,即評(píng)價(jià)對(duì)象。本文概覽了目前主流的提取技術(shù)�����,包括名詞短語(yǔ)的頻繁項(xiàng)挖掘�����、評(píng)價(jià)詞的映射�、監(jiān)督學(xué)習(xí)方法以及主題模型方法。目前抽取的問(wèn)題在于中文本身的特性����、大數(shù)據(jù)等����。
引言
隨著互聯(lián)網(wǎng)信息的不斷增長(zhǎng)���,以往的信息缺乏消失了��。但海量的數(shù)據(jù)造成的后果是����,人們?cè)絹?lái)越渴望能在快速地在數(shù)據(jù)汪洋中尋找屬于自己的一滴水���,新的信息缺乏誕生����。對(duì)于電子商務(wù)來(lái)說(shuō)�,消費(fèi)者希望能從眾多的商品評(píng)論獲得對(duì)商品的認(rèn)識(shí),進(jìn)而決定是否購(gòu)買(mǎi)���,商家則希望從評(píng)論中獲得市場(chǎng)對(duì)商品的看法���,從而更好地適應(yīng)用戶(hù)的需求。類(lèi)似的情況相繼出現(xiàn)在博客����、微博����、論壇等網(wǎng)絡(luò)信息聚合地�����。為了解決信息過(guò)載與缺乏的矛盾�,人們初期手動(dòng)地對(duì)網(wǎng)上海量而豐富的資源進(jìn)行收集和處理�,但瞬息萬(wàn)變的網(wǎng)民意見(jiàn),突發(fā)的話(huà)題爆發(fā)很快讓人手捉襟見(jiàn)肘����。工程師們慢慢將開(kāi)始利用計(jì)算機(jī)自動(dòng)地對(duì)網(wǎng)絡(luò)信息進(jìn)行處理,意見(jiàn)挖掘由此應(yīng)運(yùn)而生����。目前意見(jiàn)挖掘主要的研究對(duì)象是互聯(lián)網(wǎng)上的海量文本信息,主要的任務(wù)包括網(wǎng)絡(luò)文本的情感極性判別�、評(píng)價(jià)對(duì)象抽取、意見(jiàn)摘要等�。近年來(lái),機(jī)器學(xué)習(xí)的發(fā)展讓人們看到了意見(jiàn)挖掘的新希望�����。意見(jiàn)挖掘的智能化程度正在逐步提高。
評(píng)價(jià)對(duì)象(Opinion
Targets)是指某段評(píng)論中所討論的主題��,具體表現(xiàn)為評(píng)論文本中評(píng)價(jià)詞語(yǔ)所修飾的對(duì)象��。如新聞評(píng)論中的某個(gè)人物�����、事件�����、話(huà)題�,產(chǎn)品評(píng)論中某種產(chǎn)品的組件、功能����、服務(wù),電影評(píng)論中的劇本����、特技、演員等��。由于蘊(yùn)含著極大的商業(yè)價(jià)值,所以現(xiàn)有的研究大部分集中于產(chǎn)品領(lǐng)域的評(píng)價(jià)對(duì)象的抽取���,他們大多將評(píng)價(jià)對(duì)象限定在名詞或名詞短語(yǔ)的范疇內(nèi)���,進(jìn)而對(duì)它們作進(jìn)一步的識(shí)別��。評(píng)價(jià)對(duì)象抽取是細(xì)粒度的情感分析任務(wù)���,評(píng)價(jià)對(duì)象是情感分析中情感信息的一個(gè)重要組成部分。而且��,這項(xiàng)研究的開(kāi)展有助于為上層情感分析任務(wù)提供服務(wù)����。因而評(píng)價(jià)對(duì)象抽取也就成為某些應(yīng)用系統(tǒng)的必備組件��,例如:
觀點(diǎn)問(wèn)答系統(tǒng)����,例如就某個(gè)實(shí)體X,需要回答諸如“人們喜不喜歡X的哪些方面��?”這樣的問(wèn)題��。
推薦系統(tǒng)����,例如系統(tǒng)需要推薦那些在某個(gè)屬性上獲得較好評(píng)價(jià)的產(chǎn)品
觀點(diǎn)總結(jié)系統(tǒng)��,例如用戶(hù)需要分別查看對(duì)某個(gè)實(shí)體X就某個(gè)方面Y的正面和負(fù)面評(píng)價(jià)����。如圖1所示為淘寶上某秋季女裝的評(píng)價(jià)頁(yè)面的標(biāo)簽。
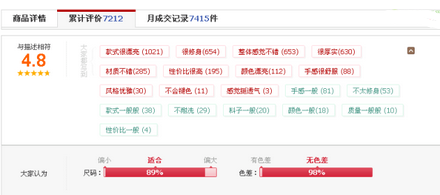
圖1:淘寶新款秋季女裝的評(píng)價(jià)簡(jiǎn)述��。其中“款式”��、“材質(zhì)”和“顏色”就是評(píng)價(jià)對(duì)象����,紅色表示對(duì)女裝的正面評(píng)價(jià),靛色表示負(fù)面評(píng)價(jià)�。
這些任務(wù)的一個(gè)公共之處是,系統(tǒng)必須能夠識(shí)別評(píng)論文本討論的主題,即評(píng)價(jià)對(duì)象�����。評(píng)價(jià)對(duì)象作為意見(jiàn)挖掘的一個(gè)基本單元���,一直是自然語(yǔ)言處理的熱點(diǎn)�。文章接下來(lái)將討論評(píng)價(jià)對(duì)象抽取的研究現(xiàn)狀��。首先從名詞的頻率統(tǒng)計(jì)出發(fā)���,闡述抽取評(píng)價(jià)對(duì)象的早期方法�����,然后在考慮評(píng)價(jià)對(duì)象與評(píng)價(jià)詞的關(guān)系的基礎(chǔ)上,討論如何利用評(píng)價(jià)詞發(fā)現(xiàn)已經(jīng)出現(xiàn)和隱藏的評(píng)價(jià)對(duì)象����、接著敘述經(jīng)典的監(jiān)督學(xué)習(xí)方法(隱馬爾可夫方法和條件隨機(jī)場(chǎng))的優(yōu)劣,最后詳述了主題模型在評(píng)價(jià)對(duì)象抽取上的應(yīng)用和展現(xiàn)���。
研究現(xiàn)狀
評(píng)價(jià)對(duì)象抽取屬于信息抽取的范疇��,是將非結(jié)構(gòu)文本轉(zhuǎn)換為結(jié)構(gòu)化數(shù)據(jù)的一種技術(shù)���。目前評(píng)價(jià)對(duì)象的抽取主要用于網(wǎng)絡(luò)文本的意見(jiàn)挖掘���。長(zhǎng)如博客,短如微博都可以作為評(píng)價(jià)對(duì)象的抽取對(duì)象�。在特定的情感分析環(huán)境下,所抽取的文本所處的領(lǐng)域往往能簡(jiǎn)化抽取的難度�����。一個(gè)最重要的特征就是文本中的名詞��。提取文本所描述的評(píng)價(jià)對(duì)象����,并進(jìn)一步地提取與評(píng)價(jià)對(duì)象相關(guān)的評(píng)價(jià)詞,對(duì)于文本的自動(dòng)摘要���、歸納和呈現(xiàn)都有非常重要的意義�。但需要注意的是評(píng)價(jià)詞與評(píng)價(jià)對(duì)象的提取并沒(méi)有什么先后關(guān)系�����,由于評(píng)價(jià)詞與評(píng)價(jià)對(duì)象的種種聯(lián)系。實(shí)踐中往往會(huì)利用評(píng)價(jià)對(duì)象與評(píng)價(jià)詞之間的特定映射來(lái)抽取信息���。例如“這輛車(chē)很貴”中的“貴”是一個(gè)評(píng)價(jià)詞(情感詞)���,其評(píng)價(jià)的對(duì)象是車(chē)的價(jià)格?!百F”和“便宜”往往是用來(lái)描述商品的價(jià)格的。即使文本中沒(méi)有出現(xiàn)“價(jià)格”�,但依然可以判斷其修飾的評(píng)價(jià)對(duì)象。第2小節(jié)將著重討論這類(lèi)隱式評(píng)價(jià)對(duì)象��。前四節(jié)則探討如何挖掘在文本中已經(jīng)出現(xiàn)的評(píng)價(jià)對(duì)象�����。主流的方法有四種�,分別是名詞挖掘、評(píng)價(jià)詞與對(duì)象的關(guān)聯(lián)���、監(jiān)督學(xué)習(xí)方法和主題模型。
從頻繁的名詞開(kāi)始
通過(guò)對(duì)大量商品評(píng)論的觀察�����,可以粗略地發(fā)現(xiàn)評(píng)價(jià)對(duì)象大都是名詞或者名詞短語(yǔ)。Hu和Liu(2004)從某一領(lǐng)域的大量語(yǔ)料出發(fā)����,先進(jìn)行詞性標(biāo)記得到語(yǔ)料中的名詞,再使用Apriori算法來(lái)發(fā)現(xiàn)評(píng)價(jià)對(duì)象����。其具體步驟如下:
1、對(duì)句子進(jìn)行詞性標(biāo)注�,保留名詞,去掉其它詞性的詞語(yǔ)���。每個(gè)句子組成一個(gè)事務(wù)����,用于第二步進(jìn)行關(guān)聯(lián)發(fā)現(xiàn)���;
2���、使用Apriori算法找出長(zhǎng)度不超過(guò)3的頻繁詞集;
3��、進(jìn)行詞集剪枝�,去除稀疏和冗余的詞集:
稀疏剪枝:在某一包含頻繁詞集f的句子s中���,設(shè)順序出現(xiàn)的詞分別為,若任意兩個(gè)相鄰的詞的距離不超過(guò)3�����,那么就稱(chēng)f在這一句子s中是緊湊的�。若f至少在兩條句子中是緊湊的,那么f就是緊湊的頻繁詞集�。稀疏剪枝即是去除所有非緊湊的頻繁詞集;
冗余剪枝:設(shè)只包含頻繁詞集f�,不包含f的超集的句子數(shù)目是頻繁詞集的p支持度。冗余剪枝會(huì)將p支持度小于最小p支持度的頻繁詞集去除��。
這一方法盡管簡(jiǎn)單�,但卻非常有效。其原因在于人們對(duì)某一實(shí)體進(jìn)行評(píng)價(jià)時(shí)�����,其所用詞匯是有限的����,或者收斂的,那么那些經(jīng)常被談?wù)摰拿~通常就是較好的評(píng)價(jià)對(duì)象�。Popescu和Etzioni(2005)通過(guò)進(jìn)一步過(guò)濾名詞短語(yǔ)使算法的準(zhǔn)確率得到了提高。他們是通過(guò)計(jì)算名詞短語(yǔ)與所要抽取評(píng)價(jià)對(duì)象的分類(lèi)的點(diǎn)間互信息(Point
Mutual
Information�,PMI)來(lái)評(píng)價(jià)名詞短語(yǔ)。例如要在手機(jī)評(píng)價(jià)中抽取對(duì)象��,找到了“屏幕”短語(yǔ)��。屏幕是手機(jī)的一部分�,屬于手機(jī)分類(lèi),與手機(jī)的關(guān)系是部分與整體的關(guān)系��。網(wǎng)絡(luò)評(píng)論中常常會(huì)出現(xiàn)諸如“手機(jī)的屏幕…”��、“手機(jī)有一個(gè)5寸的屏幕”等文本結(jié)構(gòu)�����。Popescu和Etzioni通過(guò)在網(wǎng)絡(luò)中搜索這類(lèi)結(jié)構(gòu)來(lái)確定名詞短語(yǔ)與某一分類(lèi)的PMI����,繼而過(guò)濾PMI較低的名詞短語(yǔ)。
其中a是通過(guò)Apriori算法發(fā)現(xiàn)的頻繁名詞短語(yǔ)���,而d是a所在的分類(lèi)��。這樣如果頻繁名詞短語(yǔ)的PMI值過(guò)小�,那么就可能不是這一領(lǐng)域的評(píng)價(jià)對(duì)象。例如“線頭”和“手機(jī)”就可能不頻繁同時(shí)出現(xiàn)��。Popescu和Etzioni還使用WordNet中的is-a層次結(jié)構(gòu)和名詞后綴(例如iness��、ity)來(lái)分辨名詞短語(yǔ)與分類(lèi)的關(guān)系�。
Blair-Goldensohn等人(2008)著重考慮了那些頻繁出現(xiàn)在主觀句的名詞短語(yǔ)(包括名詞)。例如��,在還原詞根的基礎(chǔ)上����,統(tǒng)計(jì)所有已發(fā)現(xiàn)的名詞短語(yǔ)出現(xiàn)在主觀句頻率,并對(duì)不同的主觀句標(biāo)以不同的權(quán)重��,主觀性越強(qiáng)����,權(quán)重越大,再使用自定義的公式對(duì)名詞短語(yǔ)進(jìn)行權(quán)重排序����,僅抽取權(quán)重較高的名詞短語(yǔ)。
可以發(fā)現(xiàn)眾多策略的本質(zhì)在于統(tǒng)計(jì)頻率�����。Ku等人(2006)在段落和文檔層面上分別計(jì)算詞匯的TF-IDF,進(jìn)而提取評(píng)價(jià)對(duì)象�����。Scaffidi等人(2007)通過(guò)比較名詞短語(yǔ)在某一評(píng)論語(yǔ)料中出現(xiàn)的頻率與在普通英文語(yǔ)料中的不同辨別真正有價(jià)值的評(píng)價(jià)對(duì)象��。Zhu等人(2009)先通過(guò)Cvalue度量找出由多個(gè)詞組成的評(píng)價(jià)對(duì)象����,建立候選評(píng)價(jià)對(duì)象集�����,再?gòu)脑u(píng)價(jià)對(duì)象種子集出發(fā)���,計(jì)算每個(gè)候選評(píng)價(jià)對(duì)象中的詞的共現(xiàn)頻率�����,接著不斷應(yīng)用Bootstrapping方法挑選候選評(píng)價(jià)對(duì)象��。Cvalue度量考慮了多詞短語(yǔ)t的頻率f(t)��、長(zhǎng)度|t|以及包含t的其它短語(yǔ)集合��。
評(píng)價(jià)詞與對(duì)象的關(guān)系
評(píng)價(jià)對(duì)象與評(píng)價(jià)意見(jiàn)往往是相互聯(lián)系的�����。它們之間的聯(lián)系可以被用于抽取評(píng)價(jià)對(duì)象���。例如情感詞可以被用于描述或修飾不同的評(píng)價(jià)對(duì)象����。如果一條句子沒(méi)有頻繁出現(xiàn)的評(píng)價(jià)對(duì)象���,但卻有一些情感詞���,那么與情感詞相近的名詞或名詞短語(yǔ)就有可能是評(píng)價(jià)對(duì)象。Hu和Liu(2004)就使用這一方法來(lái)提取非頻繁的評(píng)價(jià)對(duì)象�,Blair-Goldenshohn等人(2008)基于情感模式也使用相似的方法。
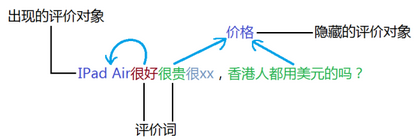
圖2:利用評(píng)價(jià)詞發(fā)現(xiàn)評(píng)價(jià)對(duì)象����,甚至是隱藏的評(píng)價(jià)對(duì)象
舉例來(lái)說(shuō),“這個(gè)軟件真有趣���!”由于“有趣”是一個(gè)情感詞����,所以“軟件”即被抽取作為評(píng)價(jià)對(duì)象。這一方法常常被用于發(fā)現(xiàn)評(píng)論中重要或關(guān)鍵的評(píng)價(jià)對(duì)象�,因?yàn)槿绻粋€(gè)評(píng)價(jià)對(duì)象不被人評(píng)價(jià)或者闡述觀點(diǎn),那么它也就不大可能是重要的評(píng)價(jià)對(duì)象了����。在Hu和Liu(2004)中定義了兩種評(píng)價(jià)對(duì)象:顯式評(píng)價(jià)對(duì)象和隱式評(píng)價(jià)對(duì)象�。Hu和Liu將名詞和名詞短語(yǔ)作為顯式評(píng)價(jià)對(duì)象,例如“這臺(tái)相機(jī)的圖像質(zhì)量非常不錯(cuò)����!”中的“圖像質(zhì)量”,而將所有其它的表明評(píng)價(jià)對(duì)象的短語(yǔ)稱(chēng)為隱式評(píng)價(jià)對(duì)象��,這類(lèi)對(duì)象需要借由評(píng)價(jià)詞進(jìn)行反向推導(dǎo)���。形容詞和動(dòng)詞就是最常見(jiàn)的兩種推導(dǎo)對(duì)象�。大多數(shù)形容詞和動(dòng)詞都在描述實(shí)體屬性的某一方面�,例如“這臺(tái)相機(jī)是有點(diǎn)貴,但拍得很清晰�����。”“貴”描述的是“價(jià)格”��,“拍”和“清晰”描述的是“圖像質(zhì)量”�。但這類(lèi)評(píng)價(jià)對(duì)象在評(píng)論中并沒(méi)有出現(xiàn),它隱含在上下文中���。
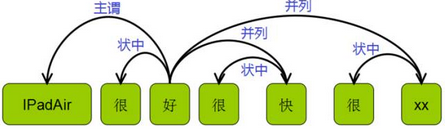
圖3:依存句法示例
如果評(píng)價(jià)詞所對(duì)應(yīng)的評(píng)價(jià)對(duì)象出現(xiàn)在評(píng)論中�����,評(píng)價(jià)詞與評(píng)價(jià)對(duì)象之間往往存在著依存關(guān)系���。Zhuang等人(2006)、Koaryashi等人(2006)�����、Somasundaran和Wiebe(2009)���、Kessler和Nicolov(2009)通過(guò)解析句子的依存關(guān)系以確定評(píng)價(jià)詞修飾的對(duì)象�����。Qiu等人(2011)進(jìn)一步將這種方法泛化雙傳播方法(double-propagation)�����,同時(shí)提取評(píng)價(jià)對(duì)象和評(píng)價(jià)詞�����。注意到評(píng)價(jià)對(duì)象可能是名詞或動(dòng)詞短語(yǔ)����,而不只是單個(gè)詞,Wu等人(2009)通過(guò)句子中短語(yǔ)的依存關(guān)系來(lái)尋找候選評(píng)價(jià)對(duì)象���,再然后通過(guò)語(yǔ)言模型過(guò)濾評(píng)價(jià)對(duì)象。
盡管顯式評(píng)價(jià)對(duì)象已經(jīng)被廣泛地研究了���,但如何將隱式評(píng)價(jià)對(duì)象映射到顯式評(píng)價(jià)對(duì)象仍缺乏探討��。Su等人(2008)提出一種聚類(lèi)方法來(lái)映射由情感詞或其短語(yǔ)表達(dá)的隱式評(píng)價(jià)對(duì)象�。
這一方法是通過(guò)顯式評(píng)價(jià)對(duì)象與情感詞在某一句子中的共現(xiàn)關(guān)系來(lái)發(fā)現(xiàn)兩者的映射���。Hai等人(2011)分兩步對(duì)共同出現(xiàn)的情感詞和顯式評(píng)價(jià)對(duì)象的關(guān)聯(lián)規(guī)則進(jìn)行挖掘�。第一步以情感詞和顯式評(píng)價(jià)對(duì)象的共現(xiàn)頻率為基礎(chǔ),生成以情感詞為條件�,以顯式評(píng)價(jià)對(duì)象為結(jié)果的關(guān)聯(lián)規(guī)則。第二步對(duì)關(guān)聯(lián)規(guī)則進(jìn)行聚類(lèi)產(chǎn)生更加魯棒的關(guān)聯(lián)規(guī)則��。
監(jiān)督學(xué)習(xí)方法
評(píng)價(jià)對(duì)象的抽取可以看作是信息抽取問(wèn)題中的一個(gè)特例���。信息抽取的研究提出了很多監(jiān)督學(xué)習(xí)算法��。其中主流的方法根植于序列學(xué)習(xí)(Sequential
Learning�,或者Sequential
Labeling)���。由于這些方法是監(jiān)督學(xué)習(xí)技術(shù)��,所以事先需要有標(biāo)記數(shù)據(jù)進(jìn)行訓(xùn)練�����。目前最好的序列學(xué)習(xí)算法是隱馬爾可夫模型(Hidden
Markov Model���,HMM)和條件隨機(jī)場(chǎng)(Conditional Random
Field,CRF)�。Jin和Ho等人使用詞匯化的HMM模型來(lái)學(xué)習(xí)抽取評(píng)價(jià)對(duì)象和評(píng)價(jià)詞的模式。Jakob和Gurevych則在不同領(lǐng)域上進(jìn)行CRF訓(xùn)練��,以獲得更加領(lǐng)域獨(dú)立的模式,其使用的特征有詞性�����、依存句法�、句距和意見(jiàn)句。Li等人(2010)整合了Skip-CRF和Tree-CRF來(lái)提取評(píng)價(jià)對(duì)象�����,這兩種CRF的特點(diǎn)在于其既能學(xué)習(xí)詞序列���,也能發(fā)現(xiàn)結(jié)構(gòu)特征��。除了這兩種主流的序列標(biāo)注技術(shù)外����。Kobayashi等人(2007)先使用依賴(lài)樹(shù)發(fā)現(xiàn)候選評(píng)價(jià)對(duì)象和評(píng)價(jià)詞對(duì)�����,接著使用樹(shù)狀分類(lèi)方法去學(xué)習(xí)這些候選對(duì)�����,并對(duì)其分類(lèi)���。分類(lèi)的結(jié)果就在于判斷候選對(duì)中的評(píng)價(jià)對(duì)象與評(píng)價(jià)詞是否存在評(píng)價(jià)關(guān)系��。分類(lèi)所依據(jù)的特征包括上下文線索�����、共現(xiàn)頻率等�����。Yu等人(2011)使用單類(lèi)SVM(one-class
SVM���,Manevitz和Yousef,2002)這一部分監(jiān)督學(xué)習(xí)方法來(lái)提取評(píng)價(jià)對(duì)象���。單類(lèi)SVM的特點(diǎn)在于其訓(xùn)練所需的樣本只用標(biāo)注某一類(lèi)即可�。他們還對(duì)相似的評(píng)價(jià)對(duì)象進(jìn)行了聚類(lèi)��,并根據(jù)出現(xiàn)的頻率和對(duì)評(píng)論評(píng)分的貢獻(xiàn)進(jìn)行排序���,取得較優(yōu)質(zhì)的評(píng)價(jià)對(duì)象�����。Kovelamudi等人(2011)在監(jiān)督學(xué)習(xí)的過(guò)程中加入了維基百科的信息����。
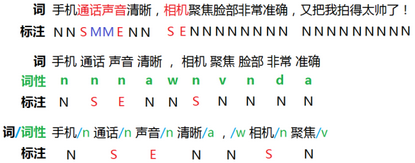
圖4:評(píng)價(jià)對(duì)象標(biāo)注示例,進(jìn)而可用于序列學(xué)習(xí)
雖然監(jiān)督學(xué)習(xí)在訓(xùn)練數(shù)據(jù)充足的情況下可以取得較好的結(jié)果,但其未得到廣泛應(yīng)用的原因也在于此�。在當(dāng)前互聯(lián)網(wǎng)信息與日俱增的情況下,新出現(xiàn)的信息可能還未來(lái)得及進(jìn)行人工標(biāo)記成為訓(xùn)練語(yǔ)料��,就已經(jīng)過(guò)時(shí)了���。而之前標(biāo)記過(guò)的語(yǔ)料又將以越來(lái)越快的速度被淘汰���。盡管不斷涌現(xiàn)出各種半監(jiān)督學(xué)習(xí)方法試圖彌補(bǔ)這一缺憾,但從種子集開(kāi)始的遞增迭代學(xué)習(xí)會(huì)在大量訓(xùn)練后出現(xiàn)偏差����,而后期的人工糾偏和調(diào)整又是需要大量的工作,且維護(hù)不易��。有鑒于此�����,雖然學(xué)術(shù)界對(duì)在評(píng)價(jià)對(duì)象抽取任務(wù)上使用監(jiān)督學(xué)習(xí)方法褒貶不一��,但在工業(yè)界的實(shí)現(xiàn)成果卻不大���。
主題模型(Topic Model)
近年來(lái)�����,統(tǒng)計(jì)主題模型逐漸成為海量文檔主題發(fā)現(xiàn)的主流方法���。主題建模是一種非監(jiān)督學(xué)習(xí)方法,它假設(shè)每個(gè)文檔都由若干個(gè)主題構(gòu)成�����,每個(gè)主題都是在詞上的概率分布�����,最后輸出詞簇的集合�,每個(gè)詞簇代表一個(gè)主題���,是文檔集合中詞的概率分布�。一個(gè)主題模型通常是一個(gè)文檔生成概率模型。目前主流的主題模型有兩種:概率潛在語(yǔ)義模型(Probabilistic
Latent Semantic Analysis�,PLSA)和潛在狄利克雷分配(Latent Dirichlet
Allocation,LDA)����。Mei等人(2007)提出了一種基于pLSA的聯(lián)合模型以進(jìn)行情感分析,這一模型的特點(diǎn)在于是眾多模型的混合�����,包括主題模型�����,正面情感模型和負(fù)面情感模型���。如此多的模型自然是需要較多數(shù)據(jù)進(jìn)行學(xué)習(xí)��。這之后的其它模型大多是利用LDA挖掘評(píng)價(jià)對(duì)象���。

圖5:LDA示例
從技術(shù)上講��,主題模型是基于貝葉斯網(wǎng)絡(luò)的圖模型��。但卻可以被擴(kuò)展用于建模多種信息��。在情感分析中�,由于每種意見(jiàn)都包含一個(gè)評(píng)價(jià)對(duì)象���,那么就可以使用主題模型進(jìn)行建模�����。但主題與評(píng)價(jià)對(duì)象還是有些不同的����,主題同時(shí)包含了評(píng)價(jià)對(duì)象和情感詞����。就情感分析來(lái)說(shuō)需要被分割這兩者。這可以通過(guò)同時(shí)對(duì)評(píng)價(jià)對(duì)象和情感詞建模來(lái)完成����。還需注意的是主題模型不僅能發(fā)現(xiàn)評(píng)價(jià)對(duì)象���,還能對(duì)評(píng)價(jià)對(duì)象進(jìn)行聚類(lèi)����。
Titov和McDonald(2008)開(kāi)始發(fā)現(xiàn)將LDA直接應(yīng)用全局?jǐn)?shù)據(jù)可能并不適用于識(shí)別評(píng)價(jià)對(duì)象��。其原因在于LDA依靠文檔中詞共現(xiàn)程度和主題分布的不同來(lái)發(fā)現(xiàn)主題及其詞概率分布�����。然而��,某一商品下的評(píng)論往往都是同質(zhì)的�,也就是都是在討論同一個(gè)商品,這使得主題模型在挖掘評(píng)價(jià)對(duì)象上表現(xiàn)不好�����,僅能在發(fā)現(xiàn)實(shí)體上發(fā)揮些余熱(不同品牌和產(chǎn)品名稱(chēng))��。Titov和McDonald因此提出了多粒度主題模型����。在全局?jǐn)?shù)據(jù)上利用主題模型發(fā)現(xiàn)討論實(shí)體����,與此同時(shí)也將主題模型應(yīng)于文檔中的連續(xù)的數(shù)條句子��。發(fā)現(xiàn)得到的某一類(lèi)評(píng)價(jià)對(duì)象實(shí)際上是一個(gè)一元語(yǔ)言模型�,即詞的多項(xiàng)分布����。描述相同評(píng)價(jià)對(duì)象的不同詞被自動(dòng)聚類(lèi)。然而這一方法并沒(méi)有將其中的評(píng)價(jià)詞(情感詞)加以分離���。
通過(guò)擴(kuò)展LDA����,Lin和He(2009)提出了一個(gè)主題和情感詞的聯(lián)合模型�����,但仍未顯式地分開(kāi)評(píng)價(jià)對(duì)象和評(píng)價(jià)詞�����。Brody和Elhadad(2010)認(rèn)為可以先使用主題模型識(shí)別出評(píng)價(jià)對(duì)象�,再考慮與評(píng)價(jià)對(duì)象相關(guān)的形容詞作為評(píng)價(jià)詞���。Li等人(2010)為了發(fā)現(xiàn)評(píng)價(jià)對(duì)象及其褒貶評(píng)價(jià)詞,提出了Sentiment-LDA和Dpeendency-sentiment-LDA兩種聯(lián)合模型���,但既沒(méi)有獨(dú)立發(fā)現(xiàn)評(píng)價(jià)對(duì)象�,也沒(méi)有將評(píng)價(jià)對(duì)象與評(píng)價(jià)詞分開(kāi)�。Zhao等人(2010)提出MaxEnt-LDA(Maximum
Entrpy
LDA)來(lái)為評(píng)價(jià)對(duì)象和評(píng)價(jià)詞聯(lián)合建模,并使用句法特征輔助分離兩者�。他們使用多項(xiàng)分布的指示變量來(lái)分辨評(píng)價(jià)對(duì)象、評(píng)價(jià)詞和背景詞(即評(píng)價(jià)對(duì)象和評(píng)價(jià)詞以外的詞)��,指示變量使用最大熵模型來(lái)訓(xùn)練其參數(shù)����。Sauper等人(2011)則試圖通過(guò)加入HMM模型達(dá)到區(qū)分評(píng)價(jià)對(duì)象、評(píng)價(jià)詞和背景詞的目的���。但他們只應(yīng)用在文本的短片段里��。這些短片段是從評(píng)價(jià)論中抽取出的����,例如“這電池正是我想要的”�。這與Griffiths等(2005)于2005年提出的HMM-LDA頗有異曲同工之妙����。Mukherjee和Liu(2012)從用戶(hù)提供的評(píng)價(jià)對(duì)象種子集開(kāi)始�,應(yīng)用半監(jiān)督聯(lián)合模型不斷迭代,產(chǎn)生貼近用戶(hù)需要的評(píng)價(jià)對(duì)象�。聯(lián)合模型的其它改進(jìn)見(jiàn)于Liu等人(2007),Lu和Zhai(2008)和Jo和Oh(2011)�。
在數(shù)據(jù)量巨大的情況下,抽取得到的評(píng)價(jià)對(duì)象往往也比較多���。為了發(fā)現(xiàn)較為重要的評(píng)價(jià)對(duì)象,Titov和McDonald(2008)在從評(píng)論中找出評(píng)價(jià)對(duì)象的同時(shí)���,還預(yù)測(cè)用戶(hù)對(duì)評(píng)價(jià)對(duì)象的評(píng)價(jià)等級(jí)����,并且抽取部分片段作為等級(jí)參考�����。Lu等人(2009)利用結(jié)構(gòu)pLSA對(duì)短文本中各短語(yǔ)的依賴(lài)結(jié)構(gòu)進(jìn)行建模��,并結(jié)合短評(píng)論的評(píng)價(jià)等級(jí)預(yù)測(cè)評(píng)論對(duì)象的評(píng)價(jià)等級(jí)���。Lakkaraju等人在HMM-LDA(Griffiths等人���,2005)的基礎(chǔ)上提出了一系列同時(shí)兼顧在詞序列和詞袋的聯(lián)合模型���,其特點(diǎn)在于能發(fā)現(xiàn)潛在的評(píng)價(jià)對(duì)象。他們與Sauper等人(2011)一樣都考慮了句法結(jié)構(gòu)和語(yǔ)義依賴(lài)����。同樣利用聯(lián)合模型發(fā)現(xiàn)和整理評(píng)價(jià)對(duì)象,并預(yù)測(cè)評(píng)價(jià)等級(jí)的還有Moghaddam和Ester(2011)����。
在實(shí)際應(yīng)用中,主題模型的某些缺點(diǎn)限制了它在實(shí)際情感分析中的應(yīng)用�����。其中最主要的原因在于它需要海量的數(shù)據(jù)和多次的參數(shù)微調(diào)����,才能得到合理的結(jié)果。另外�����,大多數(shù)主題模型使用Gibbs采樣方法,由于使用了馬爾可夫鏈蒙特卡羅方法��,其每次運(yùn)行結(jié)果都是不一樣的���。主題模型能輕易地找到在海量文檔下頻繁出現(xiàn)的主題或評(píng)價(jià)對(duì)象�,但卻很難發(fā)現(xiàn)那些在局部文檔中頻繁出現(xiàn)的評(píng)價(jià)對(duì)象�����。而這些局部頻繁的評(píng)價(jià)對(duì)象卻往往可能與某一實(shí)體相關(guān)���。對(duì)于普通的全局頻繁的評(píng)價(jià)對(duì)象,使用統(tǒng)計(jì)頻率的方法更容易獲得�����,而且還可以在不需要海量數(shù)據(jù)的情況下發(fā)現(xiàn)不頻繁的評(píng)價(jià)對(duì)象���。也就是說(shuō)�,當(dāng)前的主題建模技術(shù)對(duì)于實(shí)際的情感分析應(yīng)用還不夠成熟���。主題模型更適用于獲取文檔集合中更高層次的信息�����。盡管如此�����,研究者們對(duì)主題建模這一強(qiáng)大且擴(kuò)展性強(qiáng)的建模工具仍抱有很大期望�,不斷探索著。其中一個(gè)努力的方向是將自然語(yǔ)言知識(shí)和領(lǐng)域知識(shí)整合進(jìn)主題模型(Andrzejewski和Zhu��,2009��;Andrejewski等人���,2009����;Mukherjee和Liu��,2012�����;Zhai等人,2011)���。這一方向的研究目前還過(guò)于依賴(lài)于統(tǒng)計(jì)并且有各自的局限性�。未來(lái)還需要在各類(lèi)各領(lǐng)域知識(shí)間做出權(quán)衡���。
其他方法
除了以上所談的主流方法外�,某些研究人員還在其它方法做了嘗試����。Yi等人(2003)使用混合語(yǔ)言模型和概率比率來(lái)抽取產(chǎn)品的評(píng)價(jià)對(duì)象。Ma和Wan(2010)使用中心化理論和非監(jiān)督學(xué)習(xí)��。Meng和Wang(2009)從結(jié)構(gòu)化的產(chǎn)品說(shuō)明中提取評(píng)價(jià)對(duì)象��。Kim和Hovy(2006)使用語(yǔ)義角色標(biāo)注�。Stoyanov和Cardie(2008)利用了指代消解。
總結(jié)
大數(shù)據(jù)時(shí)代的到來(lái)不僅給機(jī)器學(xué)習(xí)帶來(lái)了前所未有的機(jī)遇�,也帶來(lái)了實(shí)現(xiàn)和評(píng)估上的各種挑戰(zhàn)����。評(píng)價(jià)對(duì)象抽取的任務(wù)在研究初期通過(guò)名詞的頻率統(tǒng)計(jì)就能大致得到不錯(cuò)的效果,即使是隱含的對(duì)象也能通過(guò)評(píng)價(jià)詞的映射大致摸索出來(lái)����,但隨著比重越來(lái)越大的用戶(hù)產(chǎn)生的文本越來(lái)越口語(yǔ)化��,傳統(tǒng)的中文分詞與句法分析等技術(shù)所起到的作用將逐漸變小�,時(shí)代呼喚著更深層次的語(yǔ)義理解����。諸如隱馬爾可夫和條件隨機(jī)場(chǎng)這樣監(jiān)督學(xué)習(xí)方法開(kāi)始被研究者們應(yīng)用到評(píng)價(jià)對(duì)象的抽取上,在訓(xùn)練數(shù)據(jù)集充足的情況下���,也的確取得了較好的效果��。然而僅靠人工標(biāo)注數(shù)據(jù)是無(wú)法跟上當(dāng)前互聯(lián)網(wǎng)上海量的文本數(shù)據(jù)�����,像LDA這樣擴(kuò)展性好的無(wú)監(jiān)督方法越來(lái)越受到人們的關(guān)注��。但LDA目前還存在著參數(shù)多�,結(jié)果不穩(wěn)定等短板�,而且完全的無(wú)監(jiān)督方法也無(wú)法適應(yīng)各種千差萬(wàn)別的應(yīng)用背景下。展望未來(lái)���,人們希望能誕生對(duì)文本——這一人造抽象數(shù)據(jù)——深度理解的基礎(chǔ)技術(shù)��,或許時(shí)下火熱的深度學(xué)習(xí)(Deep
Learning)就是其中一個(gè)突破點(diǎn)��。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330