R語言:數(shù)據(jù)庫SQL-R連接與SQL語句執(zhí)行(RODBC����、sqldf包)
數(shù)據(jù)庫是極其重要的R語言數(shù)據(jù)導(dǎo)入源數(shù)據(jù)之地,讀入包有sqldf�����、RODBC等���。跟SQL server相連有RODBC,跟MySQL鏈接的有RMySQL���。但是在R里面�����,回傳文本會(huì)出現(xiàn)截?cái)嗟那闆r���,這一情況可把我弄得有點(diǎn)手足無措����。
一���、數(shù)據(jù)庫讀入——RODBC包
CRAN 里面的包 RODBC 提供了 ODBC的訪問接口:
odbcConnect 或 odbcDriverConnect (在Windows圖形化界面下���,可以通過對(duì)話框選擇數(shù)據(jù)庫) 可以打開一個(gè)連接�,返回一個(gè)用于隨后數(shù)據(jù)庫訪問的控制(handle)。 打印一個(gè)連接會(huì)給出ODBC連接的一些細(xì)節(jié)�����,而調(diào)用 odbcGetInfo 會(huì)給出客戶端和服務(wù)器的一些細(xì)節(jié)信息�����。
在一個(gè)連接中的表的細(xì)節(jié)信息可以通過函數(shù) sqlTables 獲得。
函數(shù) sqlSave 會(huì)把 R 數(shù)據(jù)框復(fù)制到一個(gè)數(shù)據(jù)庫的表中���, 而函數(shù) sqlFetch 會(huì)把一個(gè)數(shù)據(jù)庫中的表拷貝到 一個(gè) R 的數(shù)據(jù)框中�。
通過sqlQuery進(jìn)行查詢��,返回的結(jié)果是 R 的數(shù)據(jù)框���。(sqlCopy把一個(gè) 查詢傳給數(shù)據(jù)庫��,返回結(jié)果在數(shù)據(jù)庫中以表的方式保存�����。) 一種比較好的控制方式是首先調(diào)用 odbcQuery�����, 然后 用 sqlGetResults 取得結(jié)果���。后者可用于一個(gè)循環(huán)中 每次獲得有限行,就如函數(shù) sqlFetchMore 的功能��。
連接可以通過調(diào)用函數(shù) close 或 odbcClose 來關(guān)閉����。 沒有 R 對(duì)象對(duì)應(yīng)或不在 R 會(huì)話后面的連接也可以調(diào)用這兩個(gè)函數(shù)來關(guān)閉���, 但會(huì)有警告信息。
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#安裝RODBC包
install.packages("RODBC")
library(RODBC)
mycon<-odbcConnect("mydsn",uid="user",pwd="rply")
#通過一個(gè)數(shù)據(jù)源名稱(mydsn)和用戶名(user)以及密碼(rply���,如果沒有設(shè)置�,可以直接忽略)打開了一個(gè)ODBC數(shù)據(jù)庫連接
data(USArrests)
#將R自帶的“USArrests”表寫進(jìn)數(shù)據(jù)庫里
sqlSave(mycon,USArrests,rownames="state",addPK=TRUE)
#將數(shù)據(jù)流保存���,這時(shí)打開SQL Server就可以看到新建的USArrests表了
rm(USArrests)
#清除USArrests變量
sqlFetch(mycon, "USArrests" ,rownames="state")
#輸出USArrests表中的內(nèi)容
sqlQuery(mycon,"select * from USArrests")
#對(duì)USArrests表執(zhí)行了SQL語句select�,并將結(jié)果輸出
sqlDrop(channel,"USArrests")
#刪除USArrests表
close(mycon)
#關(guān)閉連接
本段來自R語言︱文件讀入�����、讀出一些方法羅列(批量xlsx文件��、數(shù)據(jù)庫����、文本txt�����、文件夾)
1、sqlSave函數(shù)
[plain] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
sqlSave(channel, dat, tablename = NULL, append = FALSE,
rownames = TRUE, colnames = FALSE, verbose = FALSE,
safer = TRUE, addPK = FALSE, typeInfo, varTypes,
fast = TRUE, test = FALSE, nastring = NULL)
其中這個(gè)函數(shù)的使用還是很講究的�,參數(shù)的認(rèn)識(shí)很重要。
append代表是否追加����,默認(rèn)不追加,如果一張已經(jīng)有數(shù)據(jù)的表����,就可以用append追加新的數(shù)據(jù),需要同樣的column���,一般開個(gè)這個(gè)就行��。
rownames���,可以是邏輯值,也可以是字符型���。
colnames�����,列名�;
verbose,默認(rèn)為FALSE��,是否發(fā)送語句到R界面�,如果TRUE,那么每條上傳數(shù)據(jù)就會(huì)出現(xiàn)在命令欄目致之中�����。
addPK,是否將rownames指定為主鍵�。
2、sqlUpdate函數(shù)
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
sqlUpdate(channel, dat, tablename = NULL, index = NULL,
verbose = FALSE, test = FALSE, nastring = NULL,
fast = TRUE)
更新已經(jīng)存在的表格���,需要包括已經(jīng)存在的列�����。
——————————————————————————————————————————————
二���、sqldf包
本包的學(xué)習(xí)來自CDA DSC課程,L2-R語言第四講內(nèi)容�,由常老師主講。與RODBC的區(qū)別在于�����,前面是直接調(diào)用數(shù)據(jù)庫SQL中的數(shù)據(jù)���;而該包是在R語言環(huán)境中�,執(zhí)行SQL搜索語言�。
組合使用:RODBC從數(shù)據(jù)庫讀入環(huán)境,sqldf進(jìn)行搜索(適合SQL大神)���。
其他函數(shù)的類似功能可以看:R語言數(shù)據(jù)集合并�、數(shù)據(jù)增減
1�、SQL基本特點(diǎn)
SQL語句語句特點(diǎn):先全局選擇,再局部選擇
Select * from sale where year=2010 and ...
where后面可以接很多����,有比較運(yùn)算符,算數(shù)運(yùn)算符�����,邏輯運(yùn)算符�����。
比較運(yùn)算符號(hào):=(等于����,不是雙引號(hào));!=(不等于)��;>�,<,>=��,<=
算數(shù)運(yùn)算符:*���,/��,+����,-
邏輯運(yùn)算符:&&(and,與)��, ||(or��,或) ���,!(,not非)
2、數(shù)據(jù)篩選與排序
數(shù)據(jù)篩選可以有subset函數(shù),排序有order/sort函數(shù)
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#選擇表中指定列*/
sqldf("select year,market,sale,profit from sale")
#選擇滿足條件的行*/
sqldf("select * from sale where year=2012 and market='東'")
#語句特點(diǎn)���,先抽取全局?jǐn)?shù)據(jù)�����,然后再執(zhí)行局部選擇
#字符單引號(hào),切記
#對(duì)行進(jìn)行排序*/
sqldf("select year,market,sale,profit
from sale
order by year")
數(shù)據(jù)篩選:sqldf可以執(zhí)行選擇表中指定指標(biāo)���、滿足條件的行(注意:抽取滿足條件的行的字符時(shí),字符型需要用單引號(hào))����,語法結(jié)構(gòu)是:
select 指標(biāo)名稱 from 數(shù)據(jù)集 where 某指標(biāo)=條件
排序order:按照某變量排序�,語法結(jié)構(gòu):
select 指標(biāo)名稱(或全部)from 數(shù)據(jù)集 order by 指標(biāo)名稱
3、數(shù)據(jù)合并——縱向連接
數(shù)據(jù)合并的方法很多����,基本函數(shù)包中有merge、cbind/rbind�����,以及一些專業(yè)的包plyr、dplyr����、data.table等
rbind/cbind對(duì)數(shù)據(jù)合并的要求比較嚴(yán)格:合并的變量名必須一致;數(shù)據(jù)等長(zhǎng)�;指標(biāo)順序必須一致。
sqldf就不會(huì)這么苛刻�,并參照了一些集合查詢的方法(關(guān)于基礎(chǔ)包的集合查詢可參考:R語言︱集合運(yùn)算)。
(1)并——union
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
UNION3<-sqldf("select * from one union select * from two")
#合并后去重,rbind是合并后不去重
UNION_all<-sqldf("select * from one union all select * from two")
#all可以支持�����,合并后不去重
rbind/cbind是將數(shù)據(jù)一股腦子全部帖在一起����,只合并不去重�;sqldf則可以自行選擇,語法結(jié)構(gòu):
select * from 數(shù)據(jù)集1 union (all) select * from 數(shù)據(jù)集2
其中的all代表不去重���,一起加進(jìn)來��。
(2)差(except)��、交(Intersect)
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#EXCEPT_差集
#不存在all
EXCEPT<-sqldf("select * from one EXCEPT select * from two")
#INTERSECT——交集
INTERSECT<-sqldf("select * from one INTERSECT select * from two")
差集就是找兩個(gè)數(shù)據(jù)集的不同的數(shù)據(jù)����,而且是數(shù)據(jù)集1中,去掉重復(fù)的數(shù)值����;并集則是兩個(gè)數(shù)據(jù)集的重合(去重可以用)之處�����。
4���、數(shù)據(jù)合并——橫向連接
橫向連接有三種類型:交叉連接(笛卡爾乘積�����,大亂燉所有數(shù)據(jù)重新排列組合合并起來���,一般在實(shí)驗(yàn)設(shè)計(jì)涉及全排列的時(shí)候可以很好地使用)、內(nèi)連接(篩選匹配到的數(shù)據(jù))����、外連接。
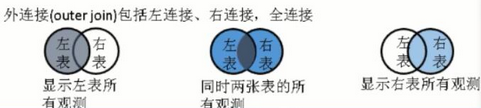
其中,sqldf 中的右連接����、全連接已經(jīng)失效,一般情況下會(huì)大多選擇左聯(lián)結(jié)�����。
(1)內(nèi)連接——匹配到完全一致的
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> inner1<- merge(table1, table2, by = "id", all = F);inner1 #篩選相同id�����,F(xiàn)為只連接匹配到的��,T為沒有匹配到的賦值NA
id a b
1 3 c e
> inner2<-inner_join(table1, table2, by = "id");inner2 #與merge完全一致
id a b
1 3 c e
> inner3<-sqldf("select * from table1 as a inner join table2 as b on a.id=b.id");inner3 #內(nèi)連接
id a id b
1 3 c 3 e
> inner4<-sqldf("select * from table1 as a,table2 as b where a.id=b.id");inner4 #笛卡爾積
id a id b
1 3 c 3 e
匹配到完全一致�����、相同的���,基礎(chǔ)包merge=dplyr的inner_join=sqldf包中的inner join����。當(dāng)然輸出結(jié)果中�����,sqldf中會(huì)蹦出來兩個(gè)id,可以進(jìn)行刪除���。
其中sql包中的Inner join語法結(jié)構(gòu)為:
select * from 數(shù)據(jù)集1 as a inner join 數(shù)據(jù)集2 as b on a.指標(biāo)名稱=b.指標(biāo)名稱
(2)左連接——最有效�,以數(shù)據(jù)集1為準(zhǔn)����,匹配到的+為匹配到的
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
> left1<- merge(table1, table2, by = "id", all.x = TRUE);left1 #按照id連接所有信息包括進(jìn)去
id a b
1 1 a <NA>
2 2 b <NA>
3 3 c e
> left2<-left_join(table1, table2, by = "id");left2
id a b
1 1 a <NA>
2 2 b <NA>
3 3 c e
> left3<-sqldf("select * from table1 as a left join table2 as b on a.id=b.id");left3
id a id b
1 1 a NA <NA>
2 2 b NA <NA>
3 3 c 3 e
基礎(chǔ)包中的merge,當(dāng)all=F就是內(nèi)連接���,all=T就是全連接,all.x=T就是左聯(lián)結(jié)��,all.y=T就是右連接(merge函數(shù)首選all=T,全連接)���;dplyr中的left_join也可以實(shí)現(xiàn)merge,all=T效果
sqldf中的語法結(jié)構(gòu):
select * from 數(shù)據(jù)集1 as a left join 數(shù)據(jù)集2as b on a.指標(biāo)名稱=b.指標(biāo)名稱
4�����、數(shù)據(jù)去重
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
#刪除重復(fù)的行*/
sqldf("select DISTINCT year from sale")
解讀:distinct跟unique去重功能差不多�,語法特點(diǎn):
select DISTINCT 指標(biāo)名稱 from 數(shù)據(jù)集
——————————————————————————————————————————————————————
應(yīng)用一:R語言中文本回傳SQL出現(xiàn)截?cái)?truncated )現(xiàn)象�����,怎么辦?
R語言中用sqlSave函數(shù)����,把文本回傳的時(shí)候回出現(xiàn)這樣的問題,文本超過255個(gè)字符的會(huì)出現(xiàn)截?cái)鄑runcated現(xiàn)象����,因?yàn)榛貍鞯?a href='/map/sql/' style='color:#000;font-size:inherit;'>SQL之后,規(guī)定的字符數(shù)即為varchar(255)���,所以會(huì)出現(xiàn)截?cái)喱F(xiàn)象���。
如果出現(xiàn)這樣的截?cái)喱F(xiàn)象該如何解決呢?
解決辦法一:修改SQL Server的字符
先創(chuàng)建一個(gè)表�,然后把那個(gè)字符型格式修改為varchar(4000),或者其他格式�����,不能修改成max�����,會(huì)報(bào)錯(cuò),造成Rstudio崩潰�����。當(dāng)然�����,也可以先sqlSave一個(gè)版本過去(就幾條內(nèi)容)�,然后修改一下格式之后,繼續(xù)append追加內(nèi)容進(jìn)行�����。
SQL Server 2008中在修改數(shù)據(jù)類型的時(shí)候���,會(huì)報(bào)錯(cuò),一直保存不了�,需要按照以下的內(nèi)容設(shè)置一下:
[html] view plain copy
print?在CODE上查看代碼片派生到我的代碼片
選擇菜單 工具-〉選項(xiàng)-〉表設(shè)計(jì)器(Designers)-〉表設(shè)計(jì)器和數(shù)據(jù)庫設(shè)計(jì)器table and database designers。然后去掉“ 阻止保存要求重新創(chuàng)建表的更改”(prevent saving changes that require table re-creation)前面的勾�����。重新啟動(dòng)MSSQL SERVER 2008可以解決該問題�。
但是筆者在嘗試該辦法的時(shí)候�,總是修改之后就卡死�����,所以無奈選擇第二條路�。
解決辦法二:從R中導(dǎo)出然后導(dǎo)入SQL Server
筆者嘗試過,導(dǎo)出csv/txt但是直接用SQL Server內(nèi)嵌工具�����,“SQL Server Import and export Wizard”對(duì)于csv/txt導(dǎo)入都十分麻煩�����,導(dǎo)入出現(xiàn)很多問題���。
所以最后是用csv-轉(zhuǎn)excel-用上述工具導(dǎo)入�。
問題一:R語言中����,用write.csv時(shí)候,用office打開�����,多出了很多行?
如果文本字符長(zhǎng)度很大��,那么就會(huì)出現(xiàn)內(nèi)容串到下面一行的情況���,譬如10行的內(nèi)容����,可能變成了15行����。好像office默認(rèn)單個(gè)單元格的字符一般不超過2500字符,超過就會(huì)給到下一行���。
所以筆者在導(dǎo)入5W條數(shù)據(jù)時(shí)候�,多出了很多行�,于是只能手動(dòng)刪除。
如果用txt格式導(dǎo)出�����,用Notepad++打開是好的��,但是用excel打開又多出來不少行�,所以用excel打開是用代價(jià)的。
但是由于excel是最好的導(dǎo)入SQL的格式����,于是不得不手工刪除,同時(shí)犧牲一部分的內(nèi)容����。
問題二:如何使用SQL Server Import and export Wizard?
1�、choose a Data Source界面(注意勾選,在第一個(gè)數(shù)據(jù)行中顯示列名稱)
2��、Data Source中���,有Flat File Source 欄目����,就是用來做csv����、txt格式的;還有一個(gè)excel選項(xiàng)是專門針對(duì)excel
3����、導(dǎo)入數(shù)據(jù)界面����,你需要輸入服務(wù)器名稱��,已經(jīng)相應(yīng)的數(shù)據(jù)庫名稱����;
4、選擇源表和源視圖�,你可以通過”目標(biāo)“欄目新建,也可以導(dǎo)入已經(jīng)有的表格��,當(dāng)然第一次導(dǎo)入�����,筆者推薦直接導(dǎo)入新表���,注意看檢查一下下面的一個(gè)欄目”編輯映射“
5�����、運(yùn)行語句��。
其中����,如果你是第二次導(dǎo)入已經(jīng)有的表����,那么在第四步,”編輯映射“時(shí)�����,就需要看清楚是否與已有的數(shù)據(jù)列表一一對(duì)應(yīng)��。
同時(shí)���,如果第二次導(dǎo)入的表有表頭名稱���,只要第一步勾選列名稱,也是沒有關(guān)系的����,導(dǎo)入后不算入數(shù)據(jù)之中。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330