假設(shè)檢驗:正態(tài)性檢驗,單樣本t檢驗,配對t檢驗
最開始的是正態(tài)性檢驗,但很多情況下大家都不做�,這其實不是很嚴(yán)謹(jǐn)。正態(tài)性檢驗指的是檢驗樣本是否來自正態(tài)分布的總體����。對于醫(yī)學(xué)很多實驗結(jié)果,我們想要應(yīng)用一些檢驗方法來做出一些研究�,很多情況下都要求這些數(shù)據(jù)來自一個正態(tài)分布總體。舉個例子����,我探究小狗狗血壓是多少�����,想提出一個檢驗問題“H0:小狗狗的血壓平均值是100mmHg���,H1:這組小狗血壓平均值不是100mmHg”。我們已經(jīng)開始假設(shè)檢驗了�。然而我們需要用到假設(shè)檢驗的方法有個小小的前提條件,要求小狗狗群體的血壓數(shù)值是滿足正態(tài)分布的���。但是�,我只知道這組樣本數(shù)據(jù)�����,并不知道來自的總體是不是滿足正態(tài)分布���。所以這個問題之前有一個現(xiàn)需要解決的假設(shè)檢驗問題“H0:小狗狗群體的血壓是滿足正態(tài)分布的,H1:小狗狗群體血壓不滿足正態(tài)分布”�����。
檢驗的原理比較難不需要掌握,很遺憾在Excel中沒有實現(xiàn)的方式����。一般采用Jarque-Bera方法,算出數(shù)據(jù)的峰度和偏度�,然后根據(jù)統(tǒng)計量繼續(xù)查表之類的,沒有操作性�。
在SPSS中就非常方便,SPSS中比較常用簡單點擊就能進(jìn)行的正態(tài)性檢驗是利用柯爾莫哥洛夫檢驗法�。實際操作是這樣的:
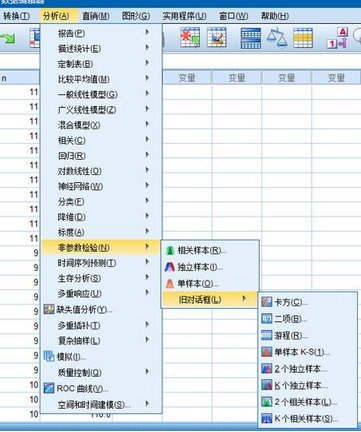
選擇分析(Analysis)非參數(shù)檢驗(Nonparametric Test)單樣本K-S檢驗(1 Sample K-S)然后就會出現(xiàn)
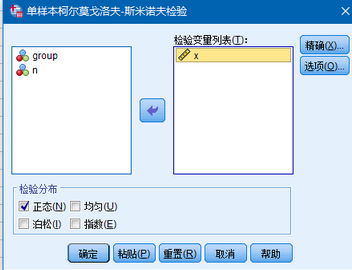
這幾個選項,我們把x(血壓值)放入要檢驗的變量列表里����,我們勾上要檢驗的“正態(tài)分布”(這里其實也可以檢驗它的分布是否滿足均勻,泊松��,指數(shù)分布)�,點擊確認(rèn)就可以。結(jié)果解讀
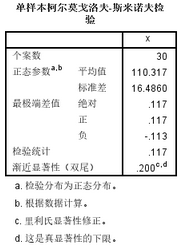
關(guān)注這個數(shù)據(jù)是否為正態(tài)分布只需要看最后一項���,發(fā)現(xiàn)p值=0.2��,大于0.05�,那么我們需要接受我們的H0假設(shè)�,這個數(shù)據(jù)是滿足正態(tài)分布的�����。其他數(shù)據(jù)分別說的是樣本數(shù)量��,根據(jù)樣本數(shù)量得出的總體滿足正態(tài)分布的標(biāo)準(zhǔn)差跟平均值�����。
這里一定要弄清楚p值的概念����,一般情況我們都是計算希望得到p小于0.05��,從而拒絕H0的假設(shè)�,并且我們犯一類錯誤(H0是正確的情況下我們拒絕它)很小,小于0.05�����。而這里因為我們提出的問題H0就是數(shù)據(jù)是符合正態(tài)分布的��,那么我們?nèi)绻玫降膒小于0.05���,說明我們要不接受它�,認(rèn)為數(shù)據(jù)來自的總體不是正態(tài)分布����。而p大于0.05,要接受我們提出的假設(shè)����,認(rèn)為數(shù)據(jù)來自的總體是符合正態(tài)分布的。
當(dāng)這組數(shù)據(jù)通過正態(tài)性檢驗���,那么我們就可以進(jìn)行接下來的一系列操作了�����。(接下來的操作我們都假設(shè)數(shù)據(jù)是滿足正態(tài)性分布的���,不滿足的情況會再說)。
這個總體均值是這么大嗎��?
這種情況下書中寫成單樣本t檢驗�。它適用于我們不知道總體均值跟方差的情況下,利用我們實驗獲得的樣本數(shù)據(jù)��,來檢驗總體的平均值是多少�����。用我們小狗狗的例子,假設(shè)檢驗問法是:

在SPSS中操作是
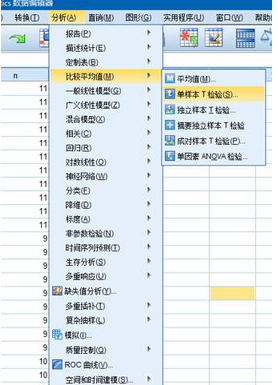
選擇分析(Analyze)�,比較平均值(Compare means),單樣本t檢驗(One sample)會彈出
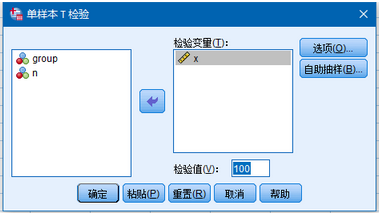
我們把要檢驗的x放入����,我們要檢驗總體均值是不是100,把檢驗值部分填寫成我們需要的�����。
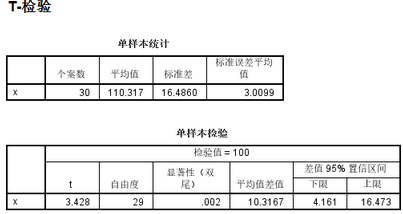
然后就出來結(jié)果了���,我們可以看到樣本的平均值為110.317�����,顯著性p=0.002<0.05��,拒絕原假設(shè)��,那么總體的平均值應(yīng)該是高于100的�����。這就完成了一個檢驗�����。值得提出的是差值95%置信區(qū)間的上下限���,這里指的是總體與100的差值的95%置信區(qū)間,一般要是一正一負(fù)�����,說明總體與100的差可能為0����,可能相等,這種時候不能拒絕0假設(shè)�����,這種時候顯著性p肯定也是大于0.05的���。至于t值與自由度��,這些內(nèi)容比較理論����,之后需要的時候再說。
很遺憾�����,這種情況Excel也沒有直接進(jìn)行單樣本t檢驗的操作方法�����,可能是這種檢驗比較簡單�,Excel都是兩個起,這個就是我們接下來說的��。
實驗前后總體的平均值有差別嗎��?
這個在我們科研中是比較多用到的���,教材上常寫作配對t檢驗����。實際上是這里我們研究實際涉及到兩個總體���,但這個很有特殊性����。樣本的選擇是自身,前后進(jìn)行對照�����,那么我們就會采用這種方法��,醫(yī)學(xué)中���,用藥前后,隨訪等等這種縱向的研究都可以用這種方法���。這里有一個小小的假設(shè)���,我們認(rèn)為前后實驗的方差是相等的(不要求掌握)。舉個例子吧����。我們想要研究長期使用避孕藥除了會讓女孩子皮膚更滑之外會不會有其他的什么不好的影響比如血壓變化等等。我們收集了一些數(shù)據(jù)�,同一批女孩子,服用避孕藥后,血壓前后是:

做一個簡單的描述性統(tǒng)計可以看到
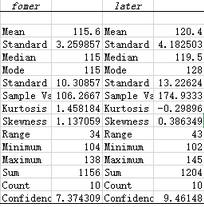
這兩組樣本之間平均值確實有差別(分別是115.6與120.4)�,但是我們不能通過描述性統(tǒng)計來說明這兩個總體的平均值有差別。這時我們就會用到配對t檢驗�。這個假設(shè)是:

我們在SPSS上
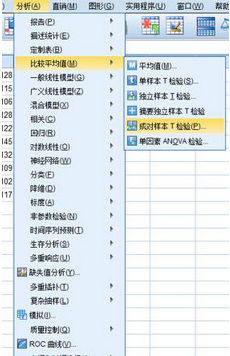
選擇分析(Analyze),比較平均值(Compare Mean)���,成對樣本t檢驗(Pair Sample)���。
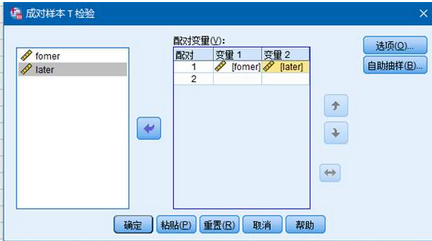
把我們要配對的分別放到變量一變量二上。確定�����。
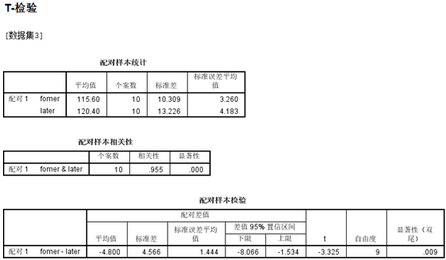
結(jié)果上�,第一張表是一些描述統(tǒng)計量,第二張表說明這兩個數(shù)據(jù)之間是不是有相關(guān)性����,一般來說,這種配對的檢驗�,相關(guān)性都會很高(它也是一個假設(shè)檢驗,相關(guān)性0.9���,顯著性p幾乎是0說明非常相關(guān)�����,如果相關(guān)性不是很高�,我們可以采用另外的檢驗方法比如獨立樣本t檢驗,之后會說到)����。第三張表就是這個假設(shè)檢驗最重要的部分,我們看顯著性p=0.009<0.05�����,拒絕原假設(shè)���,說明這兩組來自總體均值之間有很顯著的差異。我們可以看到�����,這個操作的原理實際上是用former-later做差���,得到一組新的數(shù)據(jù)�,直接檢驗這組新數(shù)據(jù)總體均值是不是等于0�,這個也不要掌握不過���。最重要就看顯著性就好了,小于0.05�����,這兩個總體均值就有明顯差異了���。
Excel上做這個也非常簡單���。我們同樣選擇data選項下,data analysis選項���,選擇配對兩樣本t檢驗����。
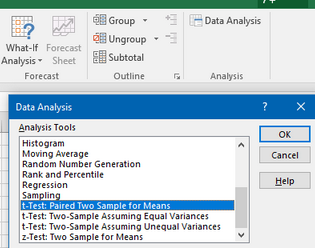
選擇輸入數(shù)據(jù)���,缺省假設(shè)這兩組之間的差是0(根據(jù)我們之前提到的原理����,其實是檢驗差值是不是等于0�����,那其實Excel可以更方便的檢驗差值是為哪一個具體的值而不單單是配對t檢驗所要求的0),
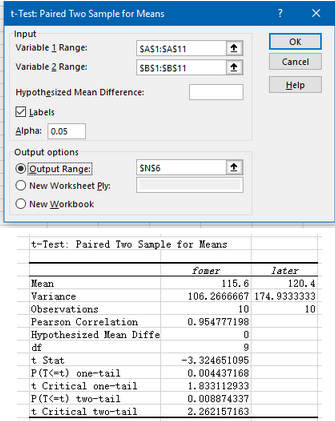
最后結(jié)果與SPSS差不多����,主要看p都小于0.05,拒絕原假設(shè)�。至于one-tail,two-tail���,一般來說���,當(dāng)我們假設(shè)檢驗的問題是這兩個總體均值相不相等的時候,我們看雙尾的結(jié)果���,要是檢驗問題是這兩個總體均值是不是A大于B啊,我們看單尾��。
結(jié)語
這次跟大家說了那么多�����,其實用起來都是非常簡單的��,單單看結(jié)果不想挖掘什么其實就只用注意p與0.05(一般情況,也有設(shè)定為0.1的)的關(guān)系�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330