從模型選擇到超參調(diào)整,六步教你如何為機器學習項目選擇算法
隨著機器學習的進一步火熱�,越來越多的算法已經(jīng)可以用在許多任務的執(zhí)行上����,并且表現(xiàn)出色�����。
但是動手之前到底哪個算法可以解決我們特定的實際問題并且運行效果良好����,這個答案很多新手是不知道的��。如果你處理問題時間可以很長�����,你可以逐個調(diào)研并且嘗試它們�����,反之則要在最短的時間內(nèi)解決技術(shù)調(diào)研任務�����。
Michael Beyeler的一篇文章告訴我們整個技術(shù)選型過程���,一步接著一步��,依靠已知的技術(shù)�����,從模型選擇到超參數(shù)調(diào)整�����。
在Michael的文章里��,他將技術(shù)選型分為6步����,從第0步到第5步�����,事實上只有5步��,第0步屬于技術(shù)選型預積累步驟�����。
第0步:了解基本知識
在我們深入之前,我們要明確我們了解了基礎(chǔ)知識����。具體來說,我們應該知道有三個主要的機器學習分類:監(jiān)督學習(supervised learning)��、無監(jiān)督學習(unsupervised learning)���,以及強化學習(reinforcement learning)���。
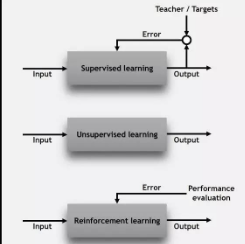
監(jiān)督學習:每個數(shù)據(jù)點被標記或者與一個類別或者感興趣值相關(guān)聯(lián)。分類標簽的一個例子是將圖像指定為“貓”或者“狗”���。價值標簽的一個例子是銷售價格與二手車相關(guān)聯(lián)�。監(jiān)督學習的目標是研究許多這樣的標記示例�,進而能夠堆未來的數(shù)據(jù)點進行預測,例如����,確定新的照片與正確的動物(分類(classification))或者指定其他二手車的準確銷售價格(回歸(regression))。
無監(jiān)督學習:數(shù)據(jù)點沒有標簽對應����。相反�����,一個無監(jiān)督學習算法的目標是以一些方式組織數(shù)據(jù)或者表述它的結(jié)構(gòu)���。這意味著將其分組到集群內(nèi)部�,或者尋找不同的方式查看復雜數(shù)據(jù),使其看起來更簡單��。
強化學習:對應于每一個數(shù)據(jù)點�����,算法需要去選擇一個動作���。這是一種常見的機器人方法���,在一個時間點的傳感器讀數(shù)集合是一個數(shù)據(jù)點,算法必須選擇機器人的下一個動作����。這也是很普通的物聯(lián)網(wǎng)應用模式,學習算法接收一個回報信號后不久�����,反饋這個決定到底好不好?����;诖?���,算法修改其策略為了達到更高的回報。
第1步:對問題進行分類
下一步����,我們要對手頭上的問題進行分類。這是一個兩步步驟:
通過輸入分類:如果我們有標簽數(shù)據(jù)�,這是一個監(jiān)督學習問題。如果我們有無標簽數(shù)據(jù)并且想要去發(fā)現(xiàn)結(jié)構(gòu)�����,這是一個無監(jiān)督學習問題�。如果我們想要通過與環(huán)境交互優(yōu)化目標函數(shù),這是一個強化學習問題����。
通過輸出分類:如果一個模型的輸出是一個數(shù)字��,這是一個回歸問題�。如果模型的輸出是一個類(或者分類)���,這是一個分類問題��。如果模型的輸出是輸入組的集合����,這是一個分類問題��。
就是那么簡單����??偠灾覀兛梢酝ㄟ^問自己算法需要解決什么問題�����,進而發(fā)現(xiàn)算法的正確分類���。
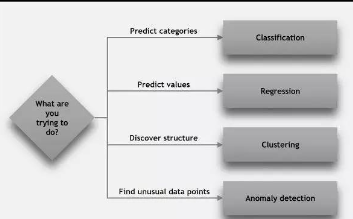
上面這張圖包含了一些我們還沒有討論的技術(shù)術(shù)語:
分類(Classification):當數(shù)據(jù)被用來預測一個分類�,監(jiān)督學習也被稱為分類。這是一個例子當指定一張相作為“貓”或“狗”的圖片���。當只有兩種選擇時��,稱為二類(two-class)或二項式分類(binomialclassification)����。當有更多類別的時候�����,當我們預測下一個諾貝爾物理學獎得住����,這個問題被稱為多項式分類(multi-classclassification)。
回歸(Regression):當一個值被預測時�,與股票價格一樣,監(jiān)督學習也被稱為回歸����。
聚類(Clustering):非監(jiān)督學習最常用的方法是聚類分析或者聚類。聚類是一組對象組的任務���,在這樣的一種方式下�����,在同一組中的對象(稱為集群)是更加相似的(在某一種意義上)��,相比其他組(集群)里的對象��。
異常檢測(Anomalydetection):需要在目標里找到不尋常的數(shù)據(jù)點���。在欺詐檢測里�,例如��,任何非常不尋常的信用卡消費模式都是可以的�����?���?赡艿淖兓芏?,而訓練示例很少,這看起來不是一種可行方式了解欺詐活動��。異常檢測需要的方法是簡單地了解什么是正常的活動(使用非欺詐交易歷史記錄),并且確定明顯不同的內(nèi)容�。
第2步:找到可用的算法
現(xiàn)在我們有分類問題,我們可以使用工具去調(diào)研和驗證算法是可行的和可實踐的���。
Microsoft Azure已經(jīng)創(chuàng)建了一個方便的算法表格����,這個表格顯示算法可以被用于哪些問題分類����。雖然這個表格是針對Azure軟件,它一般適用于:

一些值得關(guān)注的算法是:
分類(Classification):
支持向量機(SVM):通過盡可能寬的邊緣方式發(fā)現(xiàn)分離類的邊界����。當二分式不能清晰的切分時,算法找到最好的邊界�����。這個算法真正的亮點是強烈的數(shù)據(jù)特征�����,好像文本或者染色體組(>100特性)��。在這些情況下,SVMs比其許多其他算法更快遞切分二項����,也更少地過度擬合,除了需要少量的內(nèi)存�。
人工神經(jīng)網(wǎng)絡(luò)(Artificial neural networks):是大腦啟發(fā)學習算法,覆蓋多項式分類�、二項式分類,以及回歸問題�����。它們帶來了無限的多樣性�����,包括感知和深度學習�。它們花費很長時間進行訓練,但是帶來各種應用領(lǐng)域的先進性能���。
邏輯回歸(Logistic regression):雖然包含‘回歸’這個詞看上去有點令人費解,邏輯回歸事實上是一個對于二項式和多項式分類來說強大的功能�。它很快和簡單。事實是它使用了‘S’形曲線代替直線讓它對于切分數(shù)據(jù)進入組變得很自然���。邏輯回歸給出線性分類邊界(linear class boundaries)����,所以當你使用它來確保一個線性近似的時候,類似于你生活中可以使用的一些東西�。
決策樹和隨機樹(Decision trees、random forests):決策森林(回歸����、二項式,以及多項式)��,決策叢林(二項式��、多項式)�����,以及提高決策樹(回歸和二項式)所有被稱為決策樹�����,一種機器學習的基本概念���。決策樹的變種有很多��,但是它們都做了相同的事情��,使用相同的標簽細分特征空間到各個區(qū)域���。這些可以是一致類別或者恒定值的區(qū)域�,依賴于是否你正在做分類或者回歸���。
回歸(Regression):
線性回歸(Linearregression):線性回歸擬合直接(或者平臺��,或者超平面)數(shù)據(jù)集��。這是一個工具�,簡單而快速��,但是對于一些問題可能過于簡單�����。
貝葉斯線性回歸(Bayesian linearregression):它有非?�?扇〉钠焚|(zhì)�����,避免了過度擬合��。貝葉斯方式實現(xiàn)它通過對可能分布的答案作出一些假設(shè)��。這種方式的其他副產(chǎn)品是它們有很少的參數(shù)��。
提高決策樹回歸:如上所述��,提高決策樹(回歸或二項式)是基于決策樹的�,并通過細分大多數(shù)相同標簽的特征空間到區(qū)域完成。提高決策樹通過限制它們可以細分的次數(shù)和每一個區(qū)域的最小數(shù)據(jù)點數(shù)量避免過度擬合���。算法構(gòu)造一顆序列樹�,每一顆樹學習補償樹前留下的錯誤�。結(jié)果是非常準確的學習者,該算法傾向于使用大量內(nèi)存����。
聚合(Clustering):
層次聚類(Hierarchicalclustering):層次聚類的試圖簡歷一個層次結(jié)構(gòu)的聚類,它有兩種格式�。聚集聚類(Agglomerativeclustering)是一個“自下而上”的過程,其中每個觀察從自己的聚類開始���,隨著其在層次中向上移動�����,成對的聚類會進行融合����。分裂聚類(Divisiveclustering)則是一種“自頂向下”的方式,所有的觀察開始于一個聚類����,并且會隨著向下的層次移動而遞歸式地分裂。整體而言��,這里進行的融合和分裂是以一種激進的方式確定�����。層次聚類的結(jié)果通常表示成樹狀圖(dendrogram)形式�。
k-均值聚類(k-meansclustering)的目標是將n組觀測值分為k個聚類,其中每個觀測值都屬于其接近的那個均值的聚類��,這些均值被用作這些聚類的原型��。這會將數(shù)據(jù)空間分割成Voronoidan單元�����。
異常檢測(Anomaly detection):
K最近鄰(k-nearestneighbors/k-NN)是用于分類和回歸的非參數(shù)方法。在這兩種情況下�����,輸入都是由特征空間中與k最接近的訓練樣本組成的���。在k-NN分類中,輸出是一個類成員��。對象通過其k最近鄰的多數(shù)投票來分類��,其中對象被分配給k最近鄰并且最常見的類(k是一個正整數(shù)�����,通常較?。T趉-NN回歸中����,輸出為對象的屬性值。該值為其k最近鄰值的平均值�����。
單類支持向量機(One-classSVM):使用了非線性支持向量機的一個巧妙的擴展,單類支持向量機可以描繪一個嚴格概述整個數(shù)據(jù)集的邊界�����。遠在邊界之外的任何新數(shù)據(jù)點都是足夠非正常的�,也是值得特別關(guān)注的。
第3步:實現(xiàn)所有適用的算法
對于給定的問題����,通常會有一些候選算法可以適用。所以我們?nèi)绾沃滥囊粋€可以挑選���?通常���,這個問題的答案不是那么直截了當?shù)模晕覀儽仨毞磸驮囼灐?
原型開發(fā)最好分兩步完成�����。第一步�,我們希望通過最小化特征工程快速而簡單地完成幾種算法的實現(xiàn)。在這個階段�,我們主要興趣在粗略來看那個算法表現(xiàn)更好�。這個步驟有點類似招聘:我們會盡可能地尋找可以縮短我們候選算法列表的理由�。
一旦我們將列表縮減為幾個候選算法,真正的原型開發(fā)開始了�。理想地,我們想建立一個機器學習流程��,使用一組經(jīng)過精心挑選的評估標準比較每個算法在數(shù)據(jù)集上的表現(xiàn)��。在這個階段�,我們只處理一小部分的算法����,所以我們可以把注意力轉(zhuǎn)到真正神奇的地方:特征工程。
第4步:特征工程
或許比選擇算法更重要的是正確選擇表示數(shù)據(jù)的特征�。從上面的列表中選擇合適的算法是相對簡單直接的,然而特征工程卻更像是一門藝術(shù)�。
主要問題在于我們試圖分類的數(shù)據(jù)在特征空間的描述極少。利如�,用像素的灰度值來預測圖片通常是不佳的選擇;相反�,我們需要找到能提高信噪比的數(shù)據(jù)變換。如果沒有這些數(shù)據(jù)轉(zhuǎn)換����,我們的任務可能無法解決���。利如,在方向梯度直方圖(HOG)出現(xiàn)之前�����,復雜的視覺任務(像行人檢測或面部檢測)都是很難做到的�。
雖然大多數(shù)特征的有效性需要靠實驗來評估,但是了解常見的選取數(shù)據(jù)特征的方法是很有幫助的���。這里有幾個較好的方法:
主成分分析(Principal componentanalysis����,PCA):一種線性降維方法��,可以找出包含信息量較高的特征主成分�����,可以解釋數(shù)據(jù)中的大多數(shù)方差�。
尺度不變特征變換(Scale-invariant featuretransform,SIFT):計算機視覺領(lǐng)域中的算法�,用以檢測和描述圖片的局部特征。它有一個開源的替代方法ORB(Oriented FAST and rotated BRIEF)�����。
加速穩(wěn)健特征(Speeded up robust features,SURF):SIFT 的更穩(wěn)健版本�����。
方向梯度直方圖(Histogram of orientedgradients�����,HOG):一種特征描述方法��,在計算機視覺中用于計數(shù)一張圖像中局部部分的梯度方向的發(fā)生�����。
當然����,你也可以想出你自己的特征描述方法���。如果你有幾個候選方法�����,你可以使用封裝好的方法進行智能的特征選擇���。
前向搜索:
最開始不選取任何特征�。
然后選擇最相關(guān)的特征����,將這個特征加入到已有特征;計算模型的交叉驗證誤差����,重復選取其它所有候選特征;最后����,選取能使你交叉驗證誤差最小特征,并放入已選擇的特征之中�����。
重復����,直到達到期望數(shù)量的特征為止!
反向搜索:
從所有特征開始�。
先移除最不相關(guān)的特征���,然后計算模型的交叉驗證誤差;對其它所有候選特征����,重復這一過程;最后��,移除使交叉驗證誤差最大的候選特征�����。
重復�����,直到達到期望數(shù)量的特征為止����!
使用交叉驗證的準則來移除和增加特征�!
第5步:超參數(shù)優(yōu)化(可選)
最后,你可能想優(yōu)化算法的超參數(shù)���。例如���,主成分分析中的主成分個數(shù)����,k 近鄰算法的參數(shù) k��,或者是神經(jīng)網(wǎng)絡(luò)中的層數(shù)和學習速率���。最好的方法是使用交叉驗證來選擇�����。
一旦你運用了上述所有方法�,你將有很好的機會創(chuàng)造出強大的機器學習系統(tǒng)��。但是�����,你可能也猜到了�,成敗在于細節(jié),你可能不得不反復實驗��,最后才能走向成功。
相關(guān)知識
二項式分類(binomial classification):
適用環(huán)境:
各觀察單位只能具有相互對立的一種結(jié)果�����,如陽性或陰性�,生存或死亡等,屬于兩分類資料����。
已知發(fā)生某一結(jié)果(陽性)的概率為p,其對立結(jié)果的概率為1?p���,實際工作中要求p是從大量觀察中獲得比較穩(wěn)定的數(shù)值����。
n次試驗在相同條件下進行����,且各個觀察單位的觀察結(jié)果相互獨立,即每個觀察單位的觀察結(jié)果不會影響到其他觀察單位的結(jié)果�。如要求疾病無傳染性、無家族性等�。
符號:b(x,n,p)概率函數(shù)*:Cxnpxqn?x�,其中x=0,1,?,n為正整數(shù)即發(fā)生的次數(shù),Cxn=n!x!(n?x)!
例題:擲硬幣試驗。有10個硬幣擲一次���,或1個硬幣擲十次�。問五次正面向上的概率是多少?
解:根據(jù)題意n=10�����,p=q=12�,x=5 b(5,l0,12)=C510p5q10=10!(5!(10?5)!)×(12)5×(12)5=252×(132)×(132)=0.2469所以五次正面向上的概率為0.24609
Support vector machines
是一種監(jiān)督式學習的方法,可廣泛地應用于統(tǒng)計分類以及回歸分析�����。支持向量機屬于一般化線性分類器��,也可以被認為是提克洛夫規(guī)范化(Tikhonov Regularization)方法的一個特例�。這族分類器的特點是他們能夠同時最小化經(jīng)驗誤差與最大化幾何邊緣區(qū),因此支持向量機也被稱為最大邊緣區(qū)分類器����。
總結(jié)
所有的技術(shù)選型原理都是類似的,首先需要你的自身知識積累����,然后是明確需要解決的問題�����,即明確需求����。接下來確定一個較大的調(diào)研范圍����,進而進一步調(diào)研后縮小范圍,最后通過實際應用場景的測試挑選出合適的技術(shù)方案或者方法��。機器學習算法選擇��,也不例外���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材���,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330