機(jī)器學(xué)習(xí)算法與Python實踐之(四)支持向量機(jī)(SVM)實現(xiàn)
八����、SVM的實現(xiàn)之SMO算法
終于到SVM的實現(xiàn)部分了。那么神奇和有效的東西還得回歸到實現(xiàn)才可以展示其強(qiáng)大的功力��。SVM有效而且存在很高效的訓(xùn)練算法���,這也是工業(yè)界非常青睞SVM的原因��。
前面講到�,SVM的學(xué)習(xí)問題可以轉(zhuǎn)化為下面的對偶問題:
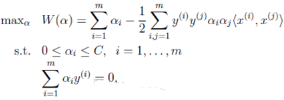
需要滿足的KKT條件:
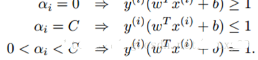
也就是說找到一組αi可以滿足上面的這些條件的就是該目標(biāo)的一個最優(yōu)解���。所以我們的優(yōu)化目標(biāo)是找到一組最優(yōu)的αi*�。一旦求出這些αi*����,就很容易計算出權(quán)重向量w*和b,并得到分隔超平面了�。
這是個凸二次規(guī)劃問題,它具有全局最優(yōu)解���,一般可以通過現(xiàn)有的工具來優(yōu)化��。但當(dāng)訓(xùn)練樣本非常多的時候��,這些優(yōu)化算法往往非常耗時低效��,以致無法使用����。從SVM提出到現(xiàn)在,也出現(xiàn)了很多優(yōu)化訓(xùn)練的方法�。其中,非常出名的一個是1982年由Microsoft Research的John C. Platt在論文《Sequential Minimal Optimization: A Fast Algorithm for TrainingSupport Vector Machines》中提出的Sequential Minimal Optimization序列最小化優(yōu)化算法����,簡稱SMO算法。SMO算法的思想很簡單���,它將大優(yōu)化的問題分解成多個小優(yōu)化的問題����。這些小問題往往比較容易求解���,并且對他們進(jìn)行順序求解的結(jié)果與將他們作為整體來求解的結(jié)果完全一致。在結(jié)果完全一致的同時���,SMO的求解時間短很多����。在深入SMO算法之前,我們先來了解下坐標(biāo)下降這個算法��,SMO其實基于這種簡單的思想的�����。
8.1�����、坐標(biāo)下降(上升)法
假設(shè)要求解下面的優(yōu)化問題:
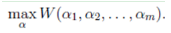
在這里�����,我們需要求解m個變量αi����,一般來說是通過梯度下降(這里是求最大值,所以應(yīng)該叫上升)等算法每一次迭代對所有m個變量αi也就是α向量進(jìn)行一次性優(yōu)化�。通過誤差每次迭代調(diào)整α向量中每個元素的值。而坐標(biāo)上升法(坐標(biāo)上升與坐標(biāo)下降可以看做是一對����,坐標(biāo)上升是用來求解max最優(yōu)化問題���,坐標(biāo)下降用于求min最優(yōu)化問題)的思想是每次迭代只調(diào)整一個變量αi的值,其他變量的值在這次迭代中固定不變�����。
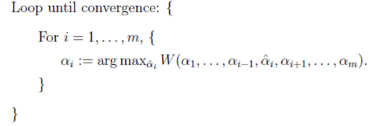
最里面語句的意思是固定除αi之外的所有αj(i不等于j)�,這時W可看作只是關(guān)于αi的函數(shù),那么直接對αi求導(dǎo)優(yōu)化即可�����。這里我們進(jìn)行最大化求導(dǎo)的順序i是從1到m�,可以通過更改優(yōu)化順序來使W能夠更快地增加并收斂。如果W在內(nèi)循環(huán)中能夠很快地達(dá)到最優(yōu)�����,那么坐標(biāo)上升法會是一個很高效的求極值方法����。
用個二維的例子來說明下坐標(biāo)下降法:我們需要尋找f(x,y)=x2+xy+y2的最小值處的(x*, y*),也就是下圖的F*點的地方���。
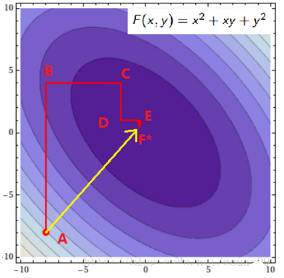
假設(shè)我們初始的點是A(圖是函數(shù)投影到xoy平面的等高線圖��,顏色越深值越?��。覀冃枰_(dá)到F*的地方����。那最快的方法就是圖中黃色線的路徑,一次性就到達(dá)了�����,其實這個是牛頓優(yōu)化法����,但如果是高維的話,這個方法就不太高效了(因為需要求解矩陣的逆���,這個不在這里討論)��。我們也可以按照紅色所指示的路徑來走����。從A開始,先固定x�����,沿著y軸往讓f(x, y)值減小的方向走到B點��,然后固定y�����,沿著x軸往讓f(x, y)值減小的方向走到C點���,不斷循環(huán)���,直到到達(dá)F*。反正每次只要我們都往讓f(x, y)值小的地方走就行了�����,這樣腳踏實地�,一步步走,每一步都使f(x, y)慢慢變小��,總有一天��,皇天不負(fù)有心人的。到達(dá)F*也是時間問題�。到這里你可能會說,這紅色線比黃色線貧富差距也太嚴(yán)重了吧���。因為這里是二維的簡單的情況嘛。如果是高維的情況����,而且目標(biāo)函數(shù)很復(fù)雜的話,再加上樣本集很多����,那么在梯度下降中,目標(biāo)函數(shù)對所有αi求梯度或者在牛頓法中對矩陣求逆���,都是很耗時的�����。這時候����,如果W只對單個αi優(yōu)化很快的時候�����,坐標(biāo)下降法可能會更加高效。
8.2�、SMO算法
SMO算法的思想和坐標(biāo)下降法的思想差不多。唯一不同的是���,SMO是一次迭代優(yōu)化兩個α而不是一個�����。為什么要優(yōu)化兩個呢����?
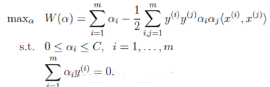
我們回到這個優(yōu)化問題��。我們可以看到這個優(yōu)化問題存在著一個約束���,也就是
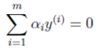
假設(shè)我們首先固定除α1以外的所有參數(shù)�����,然后在α1上求極值�。但需要注意的是,因為如果固定α1以外的所有參數(shù)�����,由上面這個約束條件可以知道����,α1將不再是變量(可以由其他值推出),因為問題中規(guī)定了:
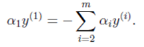
因此��,我們需要一次選取兩個參數(shù)做優(yōu)化��,比如αi和αj����,此時αi可以由αj和其他參數(shù)表示出來����。這樣回代入W中,W就只是關(guān)于αj的函數(shù)了��,這時候就可以只對αj進(jìn)行優(yōu)化了��。在這里就是對αj進(jìn)行求導(dǎo)�,令導(dǎo)數(shù)為0就可以解出這個時候最優(yōu)的αj了。然后也可以得到αi。這就是一次的迭代過程�����,一次迭代只調(diào)整兩個拉格朗日乘子αi和αj�。SMO之所以高效就是因為在固定其他參數(shù)后,對一個參數(shù)優(yōu)化過程很高效(對一個參數(shù)的優(yōu)化可以通過解析求解�,而不是迭代。雖然對一個參數(shù)的一次最小優(yōu)化不可能保證其結(jié)果就是所優(yōu)化的拉格朗日乘子的最終結(jié)果��,但會使目標(biāo)函數(shù)向極小值邁進(jìn)一步�����,這樣對所有的乘子做最小優(yōu)化�,直到所有滿足KKT條件時,目標(biāo)函數(shù)達(dá)到最?����。?���。
總結(jié)下來是:
重復(fù)下面過程直到收斂{
(1)選擇兩個拉格朗日乘子αi和αj;
(2)固定其他拉格朗日乘子αk(k不等于i和j)��,只對αi和αj優(yōu)化w(α);
(3)根據(jù)優(yōu)化后的αi和αj,更新截距b的值�;
}
那訓(xùn)練里面這兩三步驟到底是怎么實現(xiàn)的,需要考慮什么呢��?下面我們來具體分析下:
(1)選擇αi和αj:
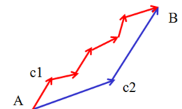
我們現(xiàn)在是每次迭代都優(yōu)化目標(biāo)函數(shù)的兩個拉格朗日乘子αi和αj����,然后其他的拉格朗日乘子保持固定。如果有N個訓(xùn)練樣本����,我們就有N個拉格朗日乘子需要優(yōu)化,但每次我們只挑兩個進(jìn)行優(yōu)化�,我們就有N(N-1)種選擇。那到底我們要選擇哪對αi和αj呢���?選擇哪對才好呢?想想我們的目標(biāo)是什么��?我們希望把所有違法KKT條件的樣本都糾正回來����,因為如果所有樣本都滿足KKT條件的話,我們的優(yōu)化就完成了�。那就很直觀了,哪個害群之馬最嚴(yán)重,我們得先對他進(jìn)行思想教育�����,讓他盡早回歸正途�����。OK�,那我們選擇的第一個變量αi就選違法KKT條件最嚴(yán)重的那一個。那第二個變量αj怎么選呢����?
我們是希望快點找到最優(yōu)的N個拉格朗日乘子,使得代價函數(shù)最大�����,換句話說��,要最快的找到代價函數(shù)最大值的地方對應(yīng)的N個拉格朗日乘子����。這樣我們的訓(xùn)練時間才會短。就像你從廣州去北京���,有飛機(jī)和綠皮車給你選�,你選啥?(就算你不考慮速度�,也得考慮下空姐的感受嘛,別辜負(fù)了她們渴望看到你的期盼�,哈哈)。有點離題了��,anyway���,每次迭代中��,哪對αi和αj可以讓我更快的達(dá)到代價函數(shù)值最大的地方����,我們就選他們����?;蛘哒f,走完這一步���,選這對αi和αj代價函數(shù)值增加的值最多�,比選擇其他所有αi和αj的結(jié)合中都多。這樣我們才可以更快的接近代價函數(shù)的最大值�,也就是達(dá)到優(yōu)化的目標(biāo)了。再例如���,下圖���,我們要從A點走到B點,按藍(lán)色的路線走c2方向的時候�,一跨一大步,按紅色的路線走c1方向的時候����,只能是人類的一小步。所以�����,藍(lán)色路線走兩步就邁進(jìn)了成功之門����,而紅色的路線,人生曲折���,好像成功遙遙無期一樣�,故曰,選擇比努力更重要����!
真啰嗦!說了半天����,其實就一句話:為什么每次迭代都要選擇最好的αi和αj,就是為了更快的收斂���!那實踐中每次迭代到底要怎樣選αi和αj呢�?這有個很好聽的名字叫啟發(fā)式選擇�����,主要思想是先選擇最有可能需要優(yōu)化(也就是違反KKT條件最嚴(yán)重)的αi�,再針對這樣的αi選擇最有可能取得較大修正步長的αj。具體是以下兩個過程:
1)第一個變量αi的選擇:
SMO稱選擇第一個變量的過程為外層循環(huán)�。外層訓(xùn)練在訓(xùn)練樣本中選取違法KKT條件最嚴(yán)重的樣本點。并將其對應(yīng)的變量作為第一個變量���。具體的,檢驗訓(xùn)練樣本(xi, yi)是否滿足KKT條件���,也就是:
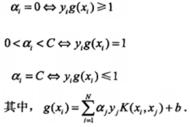
該檢驗是在ε范圍內(nèi)進(jìn)行的����。在檢驗過程中,外層循環(huán)首先遍歷所有滿足條件0<αj<C的樣本點����,即在間隔邊界上的支持向量點,檢驗他們是否滿足KKT條件���,然后選擇違反KKT條件最嚴(yán)重的αi����。如果這些樣本點都滿足KKT條件��,那么遍歷整個訓(xùn)練集�,檢驗他們是否滿足KKT條件,然后選擇違反KKT條件最嚴(yán)重的αi��。
優(yōu)先選擇遍歷非邊界數(shù)據(jù)樣本���,因為非邊界數(shù)據(jù)樣本更有可能需要調(diào)整�,邊界數(shù)據(jù)樣本常常不能得到進(jìn)一步調(diào)整而留在邊界上�。由于大部分?jǐn)?shù)據(jù)樣本都很明顯不可能是支持向量�����,因此對應(yīng)的α乘子一旦取得零值就無需再調(diào)整���。遍歷非邊界數(shù)據(jù)樣本并選出他們當(dāng)中違反KKT 條件為止。當(dāng)某一次遍歷發(fā)現(xiàn)沒有非邊界數(shù)據(jù)樣本得到調(diào)整時���,遍歷所有數(shù)據(jù)樣本���,以檢驗是否整個集合都滿足KKT條件。如果整個集合的檢驗中又有數(shù)據(jù)樣本被進(jìn)一步進(jìn)化����,則有必要再遍歷非邊界數(shù)據(jù)樣本。這樣��,不停地在遍歷所有數(shù)據(jù)樣本和遍歷非邊界數(shù)據(jù)樣本之間切換�,直到整個樣本集合都滿足KKT條件為止。以上用KKT條件對數(shù)據(jù)樣本所做的檢驗都以達(dá)到一定精度ε就可以停止為條件����。如果要求十分精確的輸出算法,則往往不能很快收斂。
對整個數(shù)據(jù)集的遍歷掃描相當(dāng)容易�����,而實現(xiàn)對非邊界αi的掃描時����,首先需要將所有非邊界樣本的αi值(也就是滿足0<αi<C)保存到新的一個列表中�����,然后再對其進(jìn)行遍歷�。同時,該步驟跳過那些已知的不會改變的αi值��。
2)第二個變量αj的選擇:
在選擇第一個αi后�,算法會通過一個內(nèi)循環(huán)來選擇第二個αj值。因為第二個乘子的迭代步長大致正比于|Ei-Ej|�,所以我們需要選擇能夠最大化|Ei-Ej|的第二個乘子(選擇最大化迭代步長的第二個乘子)。在這里����,為了節(jié)省計算時間,我們建立一個全局的緩存用于保存所有樣本的誤差值����,而不用每次選擇的時候就重新計算���。我們從中選擇使得步長最大或者|Ei-Ej|最大的αj。
(2)優(yōu)化αi和αj:
選擇這兩個拉格朗日乘子后����,我們需要先計算這些參數(shù)的約束值。然后再求解這個約束最大化問題�����。
首先����,我們需要給αj找到邊界L<=αj<=H,以保證αj滿足0<=αj<=C的約束����。這意味著αj必須落入這個盒子中。由于只有兩個變量(αi, αj)�,約束可以用二維空間中的圖形來表示,如下圖:
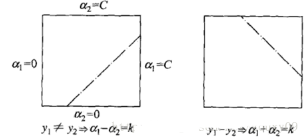
不等式約束使得(αi,αj)在盒子[0, C]x[0, C]內(nèi)�,等式約束使得(αi, αj)在平行于盒子[0, C]x[0, C]的對角線的直線上。因此要求的是目標(biāo)函數(shù)在一條平行于對角線的線段上的最優(yōu)值��。這使得兩個變量的最優(yōu)化問題成為實質(zhì)的單變量的最優(yōu)化問題。由圖可以得到�����,αj的上下界可以通過下面的方法得到:
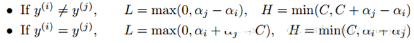
我們優(yōu)化的時候�,αj必須要滿足上面這個約束。也就是說上面是αj的可行域�����。然后我們開始尋找αj����,使得目標(biāo)函數(shù)最大化����。通過推導(dǎo)得到αj的更新公式如下:
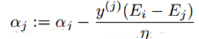
這里Ek可以看做對第k個樣本,SVM的輸出與期待輸出����,也就是樣本標(biāo)簽的誤差。
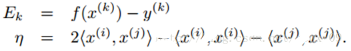
而η實際上是度量兩個樣本i和j的相似性的�。在計算η的時候,我們需要使用核函數(shù)����,那么就可以用核函數(shù)來取代上面的內(nèi)積���。
得到新的αj后,我們需要保證它處于邊界內(nèi)����。換句話說,如果這個優(yōu)化后的值跑出了邊界L和H���,我們就需要簡單的裁剪�����,將αj收回這個范圍:
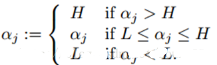
最后���,得到優(yōu)化的αj后,我們需要用它來計算αi:
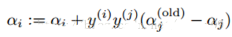
到這里�����,αi和αj的優(yōu)化就完成了����。
(3)計算閾值b:
優(yōu)化αi和αj后���,我們就可以更新閾值b,使得對兩個樣本i和j都滿足KKT條件�����。如果優(yōu)化后αi不在邊界上(也就是滿足0<αi<C���,這時候根據(jù)KKT條件����,可以得到y(tǒng)igi(xi)=1��,這樣我們才可以計算b)�����,那下面的閾值b1是有效的��,因為當(dāng)輸入xi時它迫使SVM輸出yi��。
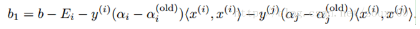
同樣�,如果0<αj<C���,那么下面的b2也是有效的:
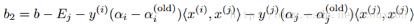
如果0<αi<C和0<αj<C都滿足����,那么b1和b2都有效,而且他們是相等的���。如果他們兩個都處于邊界上(也就是αi=0或者αi=C����,同時αj=0或者αj=C)��,那么在b1和b2之間的閾值都滿足KKT條件�����,一般我們?nèi)∷麄兊钠骄礲=(b1+b2)/2����。所以,總的來說對b的更新如下:
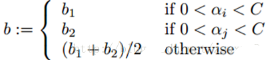
每做完一次最小優(yōu)化����,必須更新每個數(shù)據(jù)樣本的誤差,以便用修正過的分類面對其他數(shù)據(jù)樣本再做檢驗���,在選擇第二個配對優(yōu)化數(shù)據(jù)樣本時用來估計步長�。
(4)凸優(yōu)化問題終止條件:
SMO算法的基本思路是:如果說有變量的解都滿足此最優(yōu)化問題的KKT條件,那么這個最優(yōu)化問題的解就得到了�。因為KKT條件是該最優(yōu)化問題的充分必要條件(證明請參考文獻(xiàn))。所以我們可以監(jiān)視原問題的KKT條件�,所以所有的樣本都滿足KKT條件,那么就表示迭代結(jié)束了�。但是由于KKT條件本身是比較苛刻的,所以也需要設(shè)定一個容忍值��,即所有樣本在容忍值范圍內(nèi)滿足KKT條件則認(rèn)為訓(xùn)練可以結(jié)束���;當(dāng)然了��,對于對偶問題的凸優(yōu)化還有其他終止條件,可以參考文獻(xiàn)����。
8.3、SMO算法的Python實現(xiàn)
8.3.1���、Python的準(zhǔn)備工作
我使用的Python是2.7.5版本的���。附加的庫有Numpy和Matplotlib�。而Matplotlib又依賴dateutil和pyparsing兩個庫����,所以我們需要安裝以上三個庫。前面兩個庫還好安裝���,直接在官網(wǎng)下對應(yīng)版本就行���。但我找后兩個庫的時候,就沒那么容易了��。后來發(fā)現(xiàn)�,其實對Python的庫的下載和安裝可以借助pip工具的。這個是安裝和管理Python包的工具��。
8.3.2����、SMO算法的Python實現(xiàn)
在代碼中已經(jīng)有了比較詳細(xì)的注釋了。不知道有沒有錯誤的地方���,如果有�,還望大家指正(每次的運(yùn)行結(jié)果都有可能不同����,另外�,感覺有些結(jié)果似乎不太正確���,但我還沒發(fā)現(xiàn)哪里出錯了��,如果大家找到有錯誤的地方����,還望大家指點下�����,衷心感謝)�����。里面我寫了個可視化結(jié)果的函數(shù)���,但只能在二維的數(shù)據(jù)上面使用。直接貼代碼:
SVM.py
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#################################################
# SVM: support vector machine
# Author : zouxy
# Date : 2013-12-12
# HomePage : http://blog.csdn.net/zouxy09
# Email : zouxy09@qq.com
#################################################
from numpy import *
import time
import matplotlib.pyplot as plt
# calulate kernel value
def calcKernelValue(matrix_x, sample_x, kernelOption):
kernelType = kernelOption[0]
numSamples = matrix_x.shape[0]
kernelValue = mat(zeros((numSamples, 1)))
if kernelType == 'linear':
kernelValue = matrix_x * sample_x.T
elif kernelType == 'rbf':
sigma = kernelOption[1]
if sigma == 0:
sigma = 1.0
for i in xrange(numSamples):
diff = matrix_x[i, :] - sample_x
kernelValue[i] = exp(diff * diff.T / (-2.0 * sigma**2))
else:
raise NameError('Not support kernel type! You can use linear or rbf!')
return kernelValue
# calculate kernel matrix given train set and kernel type
def calcKernelMatrix(train_x, kernelOption):
numSamples = train_x.shape[0]
kernelMatrix = mat(zeros((numSamples, numSamples)))
for i in xrange(numSamples):
kernelMatrix[:, i] = calcKernelValue(train_x, train_x[i, :], kernelOption)
return kernelMatrix
# define a struct just for storing variables and data
class SVMStruct:
def __init__(self, dataSet, labels, C, toler, kernelOption):
self.train_x = dataSet # each row stands for a sample
self.train_y = labels # corresponding label
self.C = C # slack variable
self.toler = toler # termination condition for iteration
self.numSamples = dataSet.shape[0] # number of samples
self.alphas = mat(zeros((self.numSamples, 1))) # Lagrange factors for all samples
self.b = 0
self.errorCache = mat(zeros((self.numSamples, 2)))
self.kernelOpt = kernelOption
self.kernelMat = calcKernelMatrix(self.train_x, self.kernelOpt)
# calculate the error for alpha k
def calcError(svm, alpha_k):
output_k = float(multiply(svm.alphas, svm.train_y).T * svm.kernelMat[:, alpha_k] + svm.b)
error_k = output_k - float(svm.train_y[alpha_k])
return error_k
# update the error cache for alpha k after optimize alpha k
def updateError(svm, alpha_k):
error = calcError(svm, alpha_k)
svm.errorCache[alpha_k] = [1, error]
# select alpha j which has the biggest step
def selectAlpha_j(svm, alpha_i, error_i):
svm.errorCache[alpha_i] = [1, error_i] # mark as valid(has been optimized)
candidateAlphaList = nonzero(svm.errorCache[:, 0].A)[0] # mat.A return array
maxStep = 0; alpha_j = 0; error_j = 0
# find the alpha with max iterative step
if len(candidateAlphaList) > 1:
for alpha_k in candidateAlphaList:
if alpha_k == alpha_i:
continue
error_k = calcError(svm, alpha_k)
if abs(error_k - error_i) > maxStep:
maxStep = abs(error_k - error_i)
alpha_j = alpha_k
error_j = error_k
# if came in this loop first time, we select alpha j randomly
else:
alpha_j = alpha_i
while alpha_j == alpha_i:
alpha_j = int(random.uniform(0, svm.numSamples))
error_j = calcError(svm, alpha_j)
return alpha_j, error_j
# the inner loop for optimizing alpha i and alpha j
def innerLoop(svm, alpha_i):
error_i = calcError(svm, alpha_i)
### check and pick up the alpha who violates the KKT condition
## satisfy KKT condition
# 1) yi*f(i) >= 1 and alpha == 0 (outside the boundary)
# 2) yi*f(i) == 1 and 0<alpha< C (on the boundary)
# 3) yi*f(i) <= 1 and alpha == C (between the boundary)
## violate KKT condition
# because y[i]*E_i = y[i]*f(i) - y[i]^2 = y[i]*f(i) - 1, so
# 1) if y[i]*E_i < 0, so yi*f(i) < 1, if alpha < C, violate!(alpha = C will be correct)
# 2) if y[i]*E_i > 0, so yi*f(i) > 1, if alpha > 0, violate!(alpha = 0 will be correct)
# 3) if y[i]*E_i = 0, so yi*f(i) = 1, it is on the boundary, needless optimized
if (svm.train_y[alpha_i] * error_i < -svm.toler) and (svm.alphas[alpha_i] < svm.C) or\
(svm.train_y[alpha_i] * error_i > svm.toler) and (svm.alphas[alpha_i] > 0):
# step 1: select alpha j
alpha_j, error_j = selectAlpha_j(svm, alpha_i, error_i)
alpha_i_old = svm.alphas[alpha_i].copy()
alpha_j_old = svm.alphas[alpha_j].copy()
# step 2: calculate the boundary L and H for alpha j
if svm.train_y[alpha_i] != svm.train_y[alpha_j]:
L = max(0, svm.alphas[alpha_j] - svm.alphas[alpha_i])
H = min(svm.C, svm.C + svm.alphas[alpha_j] - svm.alphas[alpha_i])
else:
L = max(0, svm.alphas[alpha_j] + svm.alphas[alpha_i] - svm.C)
H = min(svm.C, svm.alphas[alpha_j] + svm.alphas[alpha_i])
if L == H:
return 0
# step 3: calculate eta (the similarity of sample i and j)
eta = 2.0 * svm.kernelMat[alpha_i, alpha_j] - svm.kernelMat[alpha_i, alpha_i] \
- svm.kernelMat[alpha_j, alpha_j]
if eta >= 0:
return 0
# step 4: update alpha j
svm.alphas[alpha_j] -= svm.train_y[alpha_j] * (error_i - error_j) / eta
# step 5: clip alpha j
if svm.alphas[alpha_j] > H:
svm.alphas[alpha_j] = H
if svm.alphas[alpha_j] < L:
svm.alphas[alpha_j] = L
# step 6: if alpha j not moving enough, just return
if abs(alpha_j_old - svm.alphas[alpha_j]) < 0.00001:
updateError(svm, alpha_j)
return 0
# step 7: update alpha i after optimizing aipha j
svm.alphas[alpha_i] += svm.train_y[alpha_i] * svm.train_y[alpha_j] \
* (alpha_j_old - svm.alphas[alpha_j])
# step 8: update threshold b
b1 = svm.b - error_i - svm.train_y[alpha_i] * (svm.alphas[alpha_i] - alpha_i_old) \
* svm.kernelMat[alpha_i, alpha_i] \
- svm.train_y[alpha_j] * (svm.alphas[alpha_j] - alpha_j_old) \
* svm.kernelMat[alpha_i, alpha_j]
b2 = svm.b - error_j - svm.train_y[alpha_i] * (svm.alphas[alpha_i] - alpha_i_old) \
* svm.kernelMat[alpha_i, alpha_j] \
- svm.train_y[alpha_j] * (svm.alphas[alpha_j] - alpha_j_old) \
* svm.kernelMat[alpha_j, alpha_j]
if (0 < svm.alphas[alpha_i]) and (svm.alphas[alpha_i] < svm.C):
svm.b = b1
elif (0 < svm.alphas[alpha_j]) and (svm.alphas[alpha_j] < svm.C):
svm.b = b2
else:
svm.b = (b1 + b2) / 2.0
# step 9: update error cache for alpha i, j after optimize alpha i, j and b
updateError(svm, alpha_j)
updateError(svm, alpha_i)
return 1
else:
return 0
# the main training procedure
def trainSVM(train_x, train_y, C, toler, maxIter, kernelOption = ('rbf', 1.0)):
# calculate training time
startTime = time.time()
# init data struct for svm
svm = SVMStruct(mat(train_x), mat(train_y), C, toler, kernelOption)
# start training
entireSet = True
alphaPairsChanged = 0
iterCount = 0
# Iteration termination condition:
# Condition 1: reach max iteration
# Condition 2: no alpha changed after going through all samples,
# in other words, all alpha (samples) fit KKT condition
while (iterCount < maxIter) and ((alphaPairsChanged > 0) or entireSet):
alphaPairsChanged = 0
# update alphas over all training examples
if entireSet:
for i in xrange(svm.numSamples):
alphaPairsChanged += innerLoop(svm, i)
print '---iter:%d entire set, alpha pairs changed:%d' % (iterCount, alphaPairsChanged)
iterCount += 1
# update alphas over examples where alpha is not 0 & not C (not on boundary)
else:
nonBoundAlphasList = nonzero((svm.alphas.A > 0) * (svm.alphas.A < svm.C))[0]
for i in nonBoundAlphasList:
alphaPairsChanged += innerLoop(svm, i)
print '---iter:%d non boundary, alpha pairs changed:%d' % (iterCount, alphaPairsChanged)
iterCount += 1
# alternate loop over all examples and non-boundary examples
if entireSet:
entireSet = False
elif alphaPairsChanged == 0:
entireSet = True
print 'Congratulations, training complete! Took %fs!' % (time.time() - startTime)
return svm
# testing your trained svm model given test set
def testSVM(svm, test_x, test_y):
test_x = mat(test_x)
test_y = mat(test_y)
numTestSamples = test_x.shape[0]
supportVectorsIndex = nonzero(svm.alphas.A > 0)[0]
supportVectors = svm.train_x[supportVectorsIndex]
supportVectorLabels = svm.train_y[supportVectorsIndex]
supportVectorAlphas = svm.alphas[supportVectorsIndex]
matchCount = 0
for i in xrange(numTestSamples):
kernelValue = calcKernelValue(supportVectors, test_x[i, :], svm.kernelOpt)
predict = kernelValue.T * multiply(supportVectorLabels, supportVectorAlphas) + svm.b
if sign(predict) == sign(test_y[i]):
matchCount += 1
accuracy = float(matchCount) / numTestSamples
return accuracy
# show your trained svm model only available with 2-D data
def showSVM(svm):
if svm.train_x.shape[1] != 2:
print "Sorry! I can not draw because the dimension of your data is not 2!"
return 1
# draw all samples
for i in xrange(svm.numSamples):
if svm.train_y[i] == -1:
plt.plot(svm.train_x[i, 0], svm.train_x[i, 1], 'or')
elif svm.train_y[i] == 1:
plt.plot(svm.train_x[i, 0], svm.train_x[i, 1], 'ob')
# mark support vectors
supportVectorsIndex = nonzero(svm.alphas.A > 0)[0]
for i in supportVectorsIndex:
plt.plot(svm.train_x[i, 0], svm.train_x[i, 1], 'oy')
# draw the classify line
w = zeros((2, 1))
for i in supportVectorsIndex:
w += multiply(svm.alphas[i] * svm.train_y[i], svm.train_x[i, :].T)
min_x = min(svm.train_x[:, 0])[0, 0]
max_x = max(svm.train_x[:, 0])[0, 0]
y_min_x = float(-svm.b - w[0] * min_x) / w[1]
y_max_x = float(-svm.b - w[0] * max_x) / w[1]
plt.plot([min_x, max_x], [y_min_x, y_max_x], '-g')
plt.show()
測試的數(shù)據(jù)來自這里����。有100個樣本��,每個樣本兩維���,最后是對應(yīng)的標(biāo)簽,例如:
3.542485 1.977398 -1
3.018896 2.556416 -1
7.551510 -1.580030 1
2.114999 -0.004466 -1
……
測試代碼中首先加載這個數(shù)據(jù)庫�����,然后用前面80個樣本來訓(xùn)練���,再用剩下的20個樣本的測試�,并顯示訓(xùn)練后的模型和分類結(jié)果�。測試代碼如下:
test_SVM.py
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
#################################################
# SVM: support vector machine
# Author : zouxy
# Date : 2013-12-12
# HomePage : http://blog.csdn.net/zouxy09
# Email : zouxy09@qq.com
#################################################
from numpy import *
import SVM
################## test svm #####################
## step 1: load data
print "step 1: load data..."
dataSet = []
labels = []
fileIn = open('E:/Python/Machine Learning in Action/testSet.txt')
for line in fileIn.readlines():
lineArr = line.strip().split('\t')
dataSet.append([float(lineArr[0]), float(lineArr[1])])
labels.append(float(lineArr[2]))
dataSet = mat(dataSet)
labels = mat(labels).T
train_x = dataSet[0:81, :]
train_y = labels[0:81, :]
test_x = dataSet[80:101, :]
test_y = labels[80:101, :]
## step 2: training...
print "step 2: training..."
C = 0.6
toler = 0.001
maxIter = 50
svmClassifier = SVM.trainSVM(train_x, train_y, C, toler, maxIter, kernelOption = ('linear', 0))
## step 3: testing
print "step 3: testing..."
accuracy = SVM.testSVM(svmClassifier, test_x, test_y)
## step 4: show the result
print "step 4: show the result..."
print 'The classify accuracy is: %.3f%%' % (accuracy * 100)
SVM.showSVM(svmClassifier)
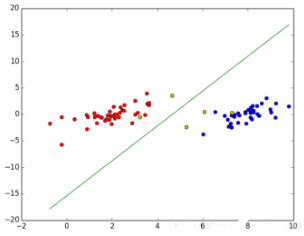
運(yùn)行結(jié)果如下:
[python] view plain copy 在CODE上查看代碼片派生到我的代碼片
step 1: load data... 數(shù)據(jù)分析師培訓(xùn)
step 2: training...
---iter:0 entire set, alpha pairs changed:8
---iter:1 non boundary, alpha pairs changed:7
---iter:2 non boundary, alpha pairs changed:1
---iter:3 non boundary, alpha pairs changed:0
---iter:4 entire set, alpha pairs changed:0
Congratulations, training complete! Took 0.058000s!
step 3: testing...
step 4: show the result...
The classify accuracy is: 100.000%
訓(xùn)練好的模型圖:
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330