機器學習算法與Python實踐之(三)支持向量機(SVM)進階
五����、核函數
如果我們的正常的樣本分布如下圖左邊所示����,之所以說是正常的指的是,不是上面說的那樣由于某些頑固的離群點導致的線性不可分�����。它是真的線性不可分���。樣本本身的分布就是這樣的�,如果也像樣本那樣��,通過松弛變量硬拉一條線性分類邊界出來����,很明顯這條分類面會非常糟糕��。那怎么辦呢�����?SVM對線性可分數據有效���,對不可分的有何應對良策呢?是核方法(kernel trick)大展身手的時候了����。
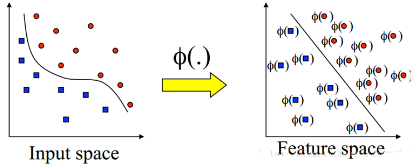
如上圖右,如果我們可以把我們的原始樣本點通過一個變換�����,變換到另一個特征空間��,在這個特征空間上是線性可分的��,那么上面的SVM就可以輕易工作了�����。也就是說���,對于不可分的數據�,現在我們要做兩個工作:
1)首先使用一個非線性映射Φ(x)將全部原始數據x變換到另一個特征空間,在這個空間中����,樣本變得線性可分了;
2)然后在特征空間中使用SVM進行學習分類��。
好了�����,第二個工作沒什么好說的����,和前面的一樣���。那第一個粗重活由誰來做呢����?我們怎么知道哪個變換才可以將我們的數據映射為線性可分呢�����?數據維度那么大,我們又看不到��。另外���,這個變換會不會使第二步的優(yōu)化變得復雜�����,計算量更大呢�?對于第一個問題�,有個著名的cover定理:將復雜的模式分類問題非線性地投射到高維空間將比投射到低維空間更可能是線性可分的。OK���,那容易了���,我們就要找到一個所有樣本映射到更高維的空間的映射。對不起����,其實要找到這個映射函數很難。但是�����,支持向量機并沒有直接尋找和計算這種復雜的非線性變換,而是很智慧的通過了一種巧妙的迂回方法來間接實現這種變換���。它就是核函數����,不僅具備這種超能力�,同時又不會增加太多計算量的兩全其美的方法。我們可以回頭看看上面SVM的優(yōu)化問題:
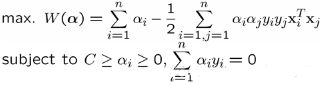
可以看到����,對樣本x的利用,只是計算第i和第j兩個樣本的內積就可以了����。
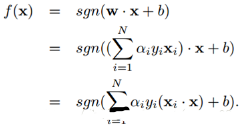
對于分類決策函數����,也是計算兩個樣本的內積。也就是說�����,訓練SVM和使用SVM都用到了樣本間的內積,而且只用到內積���。那如果我們可以找到一種方法來計算兩個樣本映射到高維空間后的內積的值就可以了��。核函數就是完成這偉大的使命的:
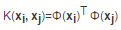
也就是兩個樣本xi和xj對應的高維空間的內積Φ(xi)T Φ(xj)通過一個核函數K(xi, xj)計算得到�。而不用知道這個變換Φ(x)是何許人也���。而且這個核函數計算很簡單�,常用的一般是徑向基RBF函數:
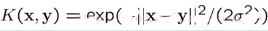
這時候���,我們的優(yōu)化的對偶問題就變成了:
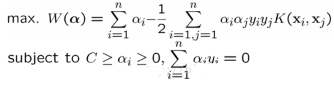
和之前的優(yōu)化問題唯一的不同只是樣本的內積需要用核函數替代而已�。優(yōu)化過程沒有任何差別�。而決策函數變成了:
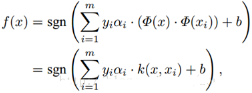
也就是新來的樣本x和我們的所有訓練樣本計算核函數即可。需要注意的是����,因為大部分樣本的拉格朗日因子αi都是0,所以其實我們只需要計算少量的訓練樣本和新來的樣本的核函數�����,然后求和取符號即可完成對新來樣本x的分類了�。支持向量機的決策過程也可以看做一種相似性比較的過程。首先,輸入樣本與一系列模板樣本進行相似性比較��,模板樣本就是訓練過程決定的支持向量�����,而采用的相似性度量就是核函數����。樣本與各支持向量比較后的得分進行加權后求和,權值就是訓練時得到的各支持向量的系數αi和類別標號的成績��。最后根據加權求和值大小來進行決策�����。而采用不同的核函數����,就相當于采用不同的相似度的衡量方法。
從計算的角度�����,不管Φ(x)變換的空間維度有多高��,甚至是無限維(函數就是無限維的)���,這個空間的線性支持向量機的求解都可以在原空間通過核函數進行�����,這樣就可以避免了高維空間里的計算�����,而計算核函數的復雜度和計算原始樣本內積的復雜度沒有實質性的增加�。
到這里����,忍不住要感嘆幾聲。為什么“碰巧”SVM里需要計算的地方數據向量總是以內積的形式出現���?為什么“碰巧”存在能簡化映射空間中的內積運算的核函數���?為什么“碰巧”大部分的樣本對決策邊界的貢獻為0?…該感謝上帝�����,還是感謝廣大和偉大的科研工作者啊����!讓我等凡夫俗子可以瞥見如此精妙和無與倫比的數學之美!
到這里���,和支持向量機相關的東西就介紹完了���。總結一下:支持向量機的基本思想可以概括為�����,首先通過非線性變換將輸入空間變換到一個高維的空間����,然后在這個新的空間求最優(yōu)分類面即最大間隔分類面,而這種非線性變換是通過定義適當的內積核函數來實現的����。SVM實際上是根據統(tǒng)計學習理論依照結構風險最小化的原則提出的,要求實現兩個目的:1)兩類問題能夠分開(經驗風險最?���。?)margin最大化(風險上界最小)既是在保證風險最小的子集中選擇經驗風險最小的函數�。
六、多類分類之SVM
SVM是一種典型的兩類分類器����,即它只回答屬于正類還是負類的問題。而現實中要解決的問題���,往往是多類的問題��。那如何由兩類分類器得到多類分類器呢�����?
6.1�、“一對多”的方法
One-Against-All這個方法還是比較容易想到的�。就是每次仍然解一個兩類分類的問題。比如我們5個類別���,第一次就把類別1的樣本定為正樣本�����,其余2���,3��,4�����,5的樣本合起來定為負樣本��,這樣得到一個兩類分類器���,它能夠指出一個樣本是還是不是第1類的;第二次我們把類別2 的樣本定為正樣本��,把1����,3,4����,5的樣本合起來定為負樣本,得到一個分類器�,如此下去,我們可以得到5個這樣的兩類分類器(總是和類別的數目一致)�。到了有樣本需要分類的時候���,我們就拿著這個樣本挨個分類器的問:是屬于你的么?是屬于你的么�����?哪個分類器點頭說是了�����,文章的類別就確定了�����。這種方法的好處是每個優(yōu)化問題的規(guī)模比較小���,而且分類的時候速度很快(只需要調用5個分類器就知道了結果)。但有時也會出現兩種很尷尬的情況�����,例如拿這個樣本問了一圈���,每一個分類器都說它是屬于它那一類的�����,或者每一個分類器都說它不是它那一類的�����,前者叫分類重疊現象�,后者叫不可分類現象。分類重疊倒還好辦����,隨便選一個結果都不至于太離譜,或者看看這篇文章到各個超平面的距離��,哪個遠就判給哪個�。不可分類現象就著實難辦了,只能把它分給第6個類別了……更要命的是���,本來各個類別的樣本數目是差不多的��,但“其余”的那一類樣本數總是要數倍于正類(因為它是除正類以外其他類別的樣本之和嘛)�,這就人為的造成了上一節(jié)所說的“數據集偏斜”問題����。
如下圖左����。紅色分類面將紅色與其他兩種顏色分開�,綠色分類面將綠色與其他兩種顏色分開,藍色分類面將藍色與其他兩種顏色分開���。
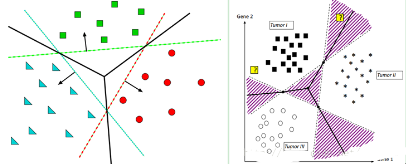
在這里的對某個點的分類實際上是通過衡量這個點到三個決策邊界的距離,因為到分類面的距離越大��,分類越可信嘛����。當然了,這個距離是有符號的�����,如下所示:
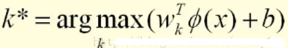
例如下圖左���,將星星這個點劃分給綠色這一類����。右圖將星星這個點劃分給褐色這一類。
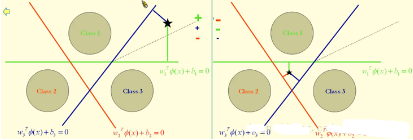
6.2�����、“一對一”的方法
One-Against-One方法是每次選一個類的樣本作正類樣本��,而負類樣本則變成只選一個類(稱為“一對一單挑”的方法��,哦���,不對���,沒有單挑,就是“一對一”的方法����,呵呵),這就避免了偏斜���。因此過程就是算出這樣一些分類器�����,第一個只回答“是第1類還是第2類”����,第二個只回答“是第1類還是第3類”,第三個只回答“是第1類還是第4類”�����,如此下去��,你也可以馬上得出����,這樣的分類器應該有5 X 4/2=10個(通式是,如果有k個類別�����,則總的兩類分類器數目為k(k-1)/2)�����。雖然分類器的數目多了���,但是在訓練階段(也就是算出這些分類器的分類平面時)所用的總時間卻比“一類對其余”方法少很多,在真正用來分類的時候��,把一個樣本扔給所有分類器,第一個分類器會投票說它是“1”或者“2”��,第二個會說它是“1”或者“3”��,讓每一個都投上自己的一票��,最后統(tǒng)計票數�����,如果類別“1”得票最多�����,就判這篇文章屬于第1類���。這種方法顯然也會有分類重疊的現象�����,但不會有不可分類現象���,因為總不可能所有類別的票數都是0。如下圖右��,中間紫色的塊,每類的得票數都是1�,那就不知道歸類給那個類好了,只能隨便扔給某個類了(或者衡量這個點到三個決策邊界的距離�����,因為到分類面的距離越大����,分類越可信嘛),扔掉了就是你命好����,扔錯了就不lucky了。
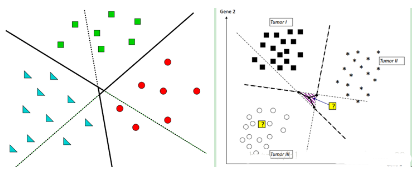
七���、KKT條件分析
對KKT條件,請大家參考文獻[13][14]����。假設我們優(yōu)化得到的最優(yōu)解是:αi*,βi*, ξi*, w*和b*。我們的最優(yōu)解需要滿足KKT條件:
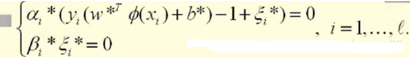
同時βi*和ξi*都需要大于等于0��,而αi*需要在0和C之間����。那可以分三種情況討論:
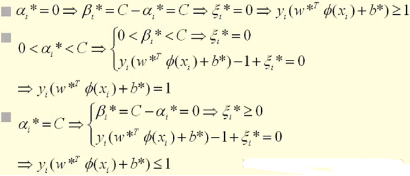
總的來說就是�����, KKT條件就變成了:
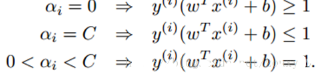
第一個式子表明如果αi=0�,那么該樣本落在兩條間隔線外�����。第二個式子表明如果αi=C����,那么該樣本有可能落在兩條間隔線內部,也有可能落在兩條間隔線上面�,主要看對應的松弛變量的取值是等于0還是大于0,第三個式子表明如果0<αi<C�����,那么該樣本一定落在分隔線上(這點很重要����,b就是拿這些落在分隔線上的點來求的,因為在分割線上wTx+b=1或者-1嘛���,才是等式�,在其他地方,都是不等式�����,求解不了b)��。具體形象化的表示如下:
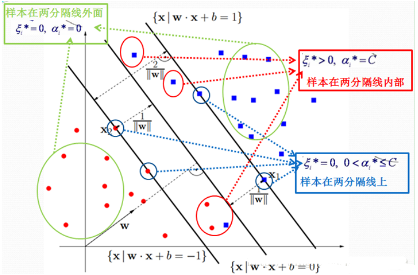
通過KKT條件可知�,αi不等于0的都是支持向量,它有可能落在分隔線上��,也有可能落在兩條分隔線內部�。KKT條件是非常重要的,在SMO也就是SVM的其中一個實現算法中����,我們可以看到它的重要應用。數據分析師培訓
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330