數(shù)據(jù)挖掘十大算法之Apriori詳解
有時(shí)候����,人們會(huì)對(duì)機(jī)器學(xué)習(xí)與數(shù)據(jù)挖掘這兩個(gè)名詞感到困惑����。如果你翻開一本冠以機(jī)器學(xué)習(xí)之名的教科書���,再同時(shí)翻開一本名叫數(shù)據(jù)挖掘的教材����,你會(huì)發(fā)現(xiàn)二者之間有相當(dāng)多重合的內(nèi)容。比如機(jī)器學(xué)習(xí)中也會(huì)講到決策樹和支持向量機(jī)��,而數(shù)據(jù)挖掘的書里也必然要在決策樹和支持向量機(jī)上花費(fèi)相當(dāng)?shù)钠?�??梢姸叽_有相當(dāng)大的重合面,但如果細(xì)研究起來��,二者也的確是各自不同的領(lǐng)域�。
大體上看,數(shù)據(jù)挖掘可以視為數(shù)據(jù)庫��、機(jī)器學(xué)習(xí)和統(tǒng)計(jì)學(xué)三者的交叉�����。簡(jiǎn)單來說��,對(duì)數(shù)據(jù)挖掘而言�����,數(shù)據(jù)庫提供了數(shù)據(jù)管理技術(shù),而機(jī)器學(xué)習(xí)和統(tǒng)計(jì)學(xué)則提供了數(shù)據(jù)分析技術(shù)��。所以你可以認(rèn)為數(shù)據(jù)挖掘包含了機(jī)器學(xué)習(xí)��,或者說機(jī)器學(xué)習(xí)是數(shù)據(jù)挖掘的彈藥庫中一類相當(dāng)龐大的彈藥集����。既然是一類彈藥,其實(shí)也就是在說數(shù)據(jù)挖掘中肯定還有其他非機(jī)器學(xué)習(xí)范疇的技術(shù)存在���。Apriori算法就屬于一種非機(jī)器學(xué)習(xí)的數(shù)據(jù)挖掘技術(shù)�。
我們都知道數(shù)據(jù)挖掘是從大量的�����、不完全的���、有噪聲的���、模糊的、隨機(jī)的數(shù)據(jù)中����,提取隱含在其中的��、人們事先不知道的���、但又是潛在有用的信息和知識(shí)的過程����。 而機(jī)器學(xué)習(xí)是以數(shù)據(jù)為基礎(chǔ),設(shè)法構(gòu)建或訓(xùn)練出一個(gè)模型��,進(jìn)而利用這個(gè)模型來實(shí)現(xiàn)數(shù)據(jù)分析的一類技術(shù)�。這個(gè)被訓(xùn)練出來的機(jī)器學(xué)習(xí)模型當(dāng)然也可以認(rèn)為是我們從數(shù)據(jù)中挖掘出來的那些潛在的、有意義的信息和知識(shí)����。在非機(jī)器學(xué)習(xí)的數(shù)據(jù)挖掘技術(shù)中,我們并不會(huì)去建立這樣一個(gè)模型����,而是直接從原數(shù)據(jù)集入手,設(shè)法分析出隱匿在數(shù)據(jù)背后的某些信息或知識(shí)�。在后續(xù)介紹Apriori算法時(shí),你會(huì)相當(dāng)明顯地感受到這一特點(diǎn)�����。
基本概念
許多商業(yè)企業(yè)在日復(fù)一日的運(yùn)營(yíng)中積聚了大量的交易數(shù)據(jù)。例如�,超市的收銀臺(tái)每天都收集大量的顧客購物數(shù)據(jù)。例如��,下表給出了一個(gè)這種數(shù)據(jù)集的例子��,我們通常稱其為購物籃交易(market basket transaction)����。表中每一行對(duì)應(yīng)一個(gè)交易,包含一個(gè)唯一標(biāo)識(shí)TID和特定顧客購買的商品集合���。零售商對(duì)分析這些數(shù)據(jù)很感興趣�,以便了解其顧客的購買行為�����??梢允褂眠@種有價(jià)值的信息來支持各種商業(yè)中的實(shí)際應(yīng)用,如市場(chǎng)促銷����,庫存管理和顧客關(guān)系管理等等��。
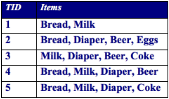
令I(lǐng)={i1,i2,?,id}是購物籃數(shù)據(jù)中所有項(xiàng)的集合����,而T={t1,t2,?,tN}是所有交易的集合�。包含0個(gè)或多個(gè)項(xiàng)的集合被稱為項(xiàng)集(itemset)。如果一個(gè)項(xiàng)集包含k個(gè)項(xiàng)�,則稱它為 k-項(xiàng)集��。顯然�����,每個(gè)交易ti包含的項(xiàng)集都是I的子集����。
關(guān)聯(lián)規(guī)則是形如 X→Y 的蘊(yùn)涵表達(dá)式,其中X和Y是不相交的項(xiàng)集����,即 X∩Y=?。關(guān)聯(lián)規(guī)則的強(qiáng)度可以用它的支持度(support)和置信度(confidence)來度量��。支持度確定規(guī)則可以用于給定數(shù)據(jù)集的頻繁程度���,而置信度確定Y在包含X的交易中出現(xiàn)的頻繁程度�����。支持度(s:Fraction of transactions that contain both X and Y)和置信度(c:How often items in Y appear in transactions that contain X)這兩種度量的形式定義如下:
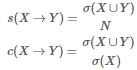
例如考慮規(guī)則{Milk, Diaper}→{Beer}���,則易得:
Association Rule Mining Task:Given a set of transactions T, the goal of association rule mining is to find all rules having
support ≥ minsup threshold
confidence ≥ minconf threshold
因此�,大多數(shù)關(guān)聯(lián)規(guī)則挖掘算法通常采用的一種策略是����,將關(guān)聯(lián)規(guī)則挖掘任務(wù)分解為如下兩個(gè)主要的子任務(wù)。
頻繁項(xiàng)集產(chǎn)生:其目標(biāo)是發(fā)現(xiàn)滿足最小支持度閾值的所有項(xiàng)集���,這些項(xiàng)集稱作頻繁項(xiàng)集(frequent itemset)����。
規(guī)則的產(chǎn)生:其目標(biāo)是從上一步發(fā)現(xiàn)的頻繁項(xiàng)集中提取所有高置信度的規(guī)則�����,這些規(guī)則稱作強(qiáng)規(guī)則(strong rule)����。
通常����,頻繁項(xiàng)集產(chǎn)生所需的計(jì)算開銷遠(yuǎn)大于產(chǎn)生規(guī)則所需的計(jì)算開銷���。
最容易想到��、也最直接的進(jìn)行關(guān)聯(lián)關(guān)系挖掘的方法或許就是暴力搜索(Brute-force)的方法:
List all possible association rules
Compute the support and confidence for each rule
Prune rules that fail the minsup and minconf thresholds
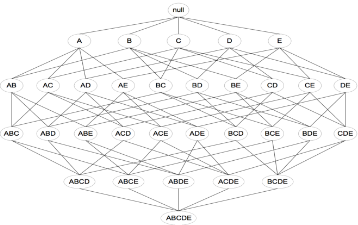
然而���,由于Brute-force的計(jì)算量過大,所以采樣這種方法并不現(xiàn)實(shí)�����!格結(jié)構(gòu)(Lattice structure)常被用來枚舉所有可能的項(xiàng)集�����。如下圖所示為I={a,b,c,d,e}的項(xiàng)集格�。一般來說�,排除空集后,一個(gè)包含k個(gè)項(xiàng)的數(shù)據(jù)集可能產(chǎn)生2k?1個(gè)頻繁項(xiàng)集���。由于在實(shí)際應(yīng)用中k的值可能非常大����,需要探查的項(xiàng)集搜索空集可能是指數(shù)規(guī)模的。
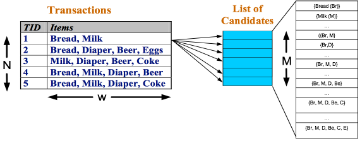
發(fā)現(xiàn)頻繁項(xiàng)集的一種原始方法是確定格結(jié)構(gòu)中每個(gè)候選項(xiàng)集(candidate itemset)的支持度計(jì) 數(shù)��。為了完成這一任務(wù)�,必須將每個(gè)候選項(xiàng)集與每個(gè)交易進(jìn)行比較,如下圖所示����。如果候選項(xiàng)集包含在交易中,則候選項(xiàng)集的支持度計(jì)數(shù)增加�����。例如�����,由于項(xiàng)集{Bread, Milk}出現(xiàn)在事務(wù)1���、4 和5中�,其支持度計(jì)數(shù)將增加3次�����。這種方法的開銷可能非常大,因?yàn)樗枰M(jìn)行O(NMw)次比 較�����,其中N是交易數(shù)���,M=2k?1是候選項(xiàng)集數(shù)��,而w是交易的最大寬度(也就是交易中最大的項(xiàng)數(shù))���。
先驗(yàn)原理
在上一小節(jié)的末尾,我們已經(jīng)看到Brute-force在實(shí)際中并不可取����。我們必須設(shè)法降低產(chǎn)生頻繁項(xiàng)集的計(jì)算復(fù)雜度。此時(shí)我們可以利用支持度對(duì)候選項(xiàng)集進(jìn)行剪枝�,這也是Apriori所利用的第一條先驗(yàn)原理:
Apriori定律1:如果一個(gè)集合是頻繁項(xiàng)集�,則它的所有子集都是頻繁項(xiàng)集。
例如:假設(shè)一個(gè)集合{A,B}是頻繁項(xiàng)集�����,即A、B同時(shí)出現(xiàn)在一條記錄的次數(shù)大于等于最小支持度min_support���,則它的子集{A},{B}出現(xiàn)次數(shù)必定大于等于min_support��,即它的子集都是頻繁項(xiàng)集����。
Apriori定律2:如果一個(gè)集合不是頻繁項(xiàng)集����,則它的所有超集都不是頻繁項(xiàng)集。
舉例:假設(shè)集合{A}不是頻繁項(xiàng)集�����,即A出現(xiàn)的次數(shù)小于 min_support���,則它的任何超集如{A,B}出現(xiàn)的次數(shù)必定小于min_support��,因此其超集必定也不是頻繁項(xiàng)集��。
下圖表示當(dāng)我們發(fā)現(xiàn){A,B}是非頻繁集時(shí)�����,就代表所有包含它的超級(jí)也是非頻繁的��,即可以將它們都剪除�����。
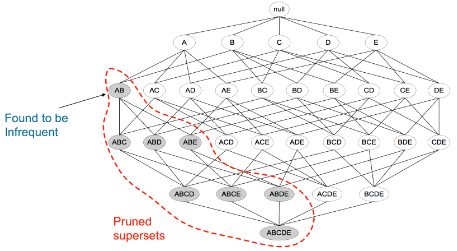
Apriori算法與實(shí)例
R. Agrawal 和 R. Srikant于1994年在文獻(xiàn)【2】中提出了Apriori算法�����,該算法的描述如下:
Let k=1
Generate frequent itemsets of length k
Repeat until no new frequent itemsets are identified
Generate length (k+1) candidate itemsets from length k frequent itemsets
Prune candidate itemsets containing subsets of length k+1 that are infrequent
Count the support of each candidate by scanning the DB
Eliminate candidates that are infrequent, leaving only those that are frequent
或者在其他資料上更為常見的是下面這種形式化的描述(注意這跟前面的文字描述是一致的):

下面是一個(gè)具體的例子����,最開始數(shù)據(jù)庫里有4條交易,{A��、C�����、D}�,{B、C���、E}���,{A、B�、C、E}�����,{B���、E}��,使用min_support=2作為支持度閾值�,最后我們篩選出來的頻繁集為{B��、C�、E}。
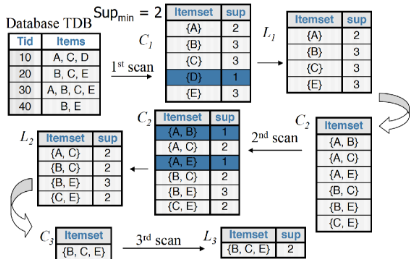
上述例子中��,最值得我們從L2到C3的這一步����。這其實(shí)就是在執(zhí)行偽代碼中第一個(gè)藍(lán)色框條所標(biāo)注的地方:Ck+1=GenerateCandidates(Lk),具體來說在Apriori算法中�,它所使用的策略如下:

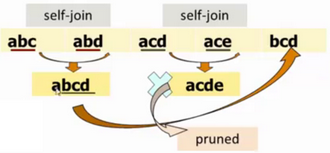
可見生成策略由兩部分組成�,首先是self-joining部分�����。例如��,假設(shè)我們有一個(gè)L3={abc, abd, acd, ace, bcd}(注意這已經(jīng)是排好序的}�。選擇兩個(gè)itemsets,它們滿足條件:前k-1個(gè)item都相同�����,但最后一個(gè)item不同���,把它們組成一個(gè)新的Ck+1的項(xiàng)集c�����。如下圖所示���,{abc}和{abd}組成{abcd},{acd}和{ace}組成{acde}��。生成策略的第二部分是pruning�。對(duì)于一個(gè)位于Ck+1中的項(xiàng)集c�,s是c的大小為k的子集�����,如果s不存在于Lk中�,則將c從Ck+1中刪除����。如下圖所示,因?yàn)閧acde}的子集{cde}并不存在于L3中����,所以我們將{acde}從C4中刪除。最后得到的C4�����,僅包含一個(gè)項(xiàng)集{abcd}��。 數(shù)據(jù)分析師培訓(xùn)
回到之前的例子�,從L2到C3的這一步,我們就只能獲得{B����、C�、E}�����。以上便是Apriori算法的最核心思想���。當(dāng)然在具體實(shí)現(xiàn)的時(shí)候����,如何Count Supports of Candidates也是需要考慮的問題���,我們這里略去這部分內(nèi)容的討論
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�;

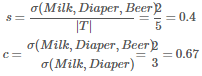










 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330