數(shù)據(jù)挖掘十大算法之決策樹詳解(1)
從分類問題開始
分類(Classification)任務(wù)就是確定對象屬于哪個預(yù)定義的目標(biāo)類��。分類問題不僅是一個普遍存在的問題��,而且是其他更加復(fù)雜的決策問題的基礎(chǔ)��,更是機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘技術(shù)中最龐大的一類算法家族�����。我們前面介紹過的很多算法(例如SVM���,樸素貝葉斯等)都可以用來解決分類問題。作為本文的開始���,我們首先來簡單回顧一下什么是分類�����。
假設(shè)我們現(xiàn)在有如下表所示的一個屬性集(feature set)�,它收集了幾個病患的癥狀和對應(yīng)的病癥����。癥狀包括頭疼的程度���、咳嗽的程度、體溫以及咽喉是否腫痛����,這些癥狀(feature)的組合就對應(yīng)一個病癥的分類(Cold 還是 Flu)。
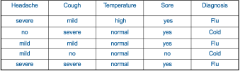
分類問題的本質(zhì)就是當(dāng)給定這樣一個數(shù)據(jù)集后��,要求我們訓(xùn)練出(或建立)一個模型f�����。當(dāng)出現(xiàn)一組新的特征向量時�����,要求我們預(yù)測(或判斷)擁有這樣一組特征向量的對象應(yīng)當(dāng)屬于哪個類別�。就我們現(xiàn)在給出的例子而言�����,假設(shè)你是一名醫(yī)生��,現(xiàn)在收治了一位新的病患,然后你通過問診得知他的一些癥狀(包括頭疼的程度���、咳嗽的程度�����、體溫以及咽喉是否腫痛)�����,然后你就要根據(jù)你已經(jīng)建立好的模型來判斷該病人得的到底是Cold(普通感冒)還是Flu(流行性感冒)����。
分類問題的類別數(shù)目可以是兩類也可以是多類�����。二分類問題是最簡單的分類問題���,而多分類問題模型可以在二分類模型的基礎(chǔ)上進(jìn)行構(gòu)建����。我們在前面文章中一直使用的鳶尾花數(shù)據(jù)集就是一個典型的多分類問題��,問題的最終目標(biāo)是判斷給定一朵花,它應(yīng)該屬于setosa����、versicolor和virginica中的哪一類。
決策樹基礎(chǔ)
決策樹是一種用于對實例進(jìn)行分類的樹形結(jié)構(gòu)���。決策樹由節(jié)點(node)和有向邊(directed edge)組成��。節(jié)點的類型有兩種:內(nèi)部節(jié)點和葉子節(jié)點��。其中���,內(nèi)部節(jié)點表示一個特征或?qū)傩缘臏y試條件(用于分開具有不同特性的記錄),葉子節(jié)點表示一個分類����。
一旦我們構(gòu)造了一個決策樹模型,以它為基礎(chǔ)來進(jìn)行分類將是非常容易的����。具體做法是�����,從根節(jié)點開始,地實例的某一特征進(jìn)行測試����,根據(jù)測試結(jié)構(gòu)將實例分配到其子節(jié)點(也就是選擇適當(dāng)?shù)姆种В谎刂摲种Э赡苓_(dá)到葉子節(jié)點或者到達(dá)另一個內(nèi)部節(jié)點時����,那么就使用新的測試條件遞歸執(zhí)行下去,直到抵達(dá)一個葉子節(jié)點��。當(dāng)?shù)竭_(dá)葉子節(jié)點時�,我們便得到了最終的分類結(jié)果。
下圖是一個決策樹的示例(注意我們僅用了兩個feature就對數(shù)據(jù)集中的5個記錄實現(xiàn)了準(zhǔn)確的分類):
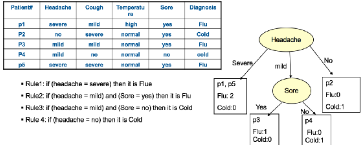
構(gòu)建
決策樹——Hunt算法
Hunt算法是一種采用局部最優(yōu)策略的決策樹構(gòu)建算法�����,它同時也是許多決策樹算法的基礎(chǔ)����,包括ID3、C4.5和CART等��。該算法的具體執(zhí)行步驟如下:
在Hunt算法中�,通過將訓(xùn)練記錄相繼劃分成較純的子集,以遞歸方式建立決策樹��。設(shè) Dt 是與結(jié)點 t 相關(guān)聯(lián)的訓(xùn)練記錄集,而y={y1,y2,?,yc}是類標(biāo)號�,Hunt算法的遞歸定義如下:
(1) 如果 Dt 中所有記錄都屬于同一個類,則 t 是葉結(jié)點�����,用 yt 標(biāo)記���。
(2) 如果 Dt 中包含屬于多個類的記錄����,則選擇一個屬性測試條件(attribute test condition)��,將記錄劃分成較小的子集���。對于測試條件的每個輸出�,創(chuàng)建一個子女結(jié)點�,并根據(jù)測試結(jié)果將 Dt 中的記錄分布到子女結(jié)點中。然后�,對于每個子女結(jié)點,遞歸地調(diào)用該算法��。
為了演示這方法���,我們選用文獻(xiàn)【2】中的一個例子來加以說明:預(yù)測貸款申請者是會按時歸還貸款�,還是會拖欠貸款�。對于這個問題,訓(xùn)練數(shù)據(jù)集可以通過考察以前貸款者的貸款記錄來構(gòu)造���。在下圖所示的例子中��,每條記錄都包含貸款者的個人信息�,以及貸款者是否拖欠貸款的類標(biāo)號���。
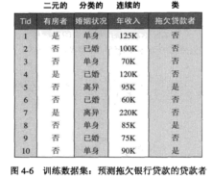
該分類問題的初始決策樹只有一個結(jié)點����,類標(biāo)號為“拖欠貨款者=否”(見圖a)���,意味大多數(shù)貸款者都按時歸還貸款����。然而�,該樹需要進(jìn)一步的細(xì)化,因為根結(jié)點包含兩個類的記錄��。根據(jù)“有房者”測試條件,這些記錄被劃分為較小的子集����,如圖b所示。接下來�,對根結(jié)點的每個子女遞歸地調(diào)用Hunt算法。從下圖給出的訓(xùn)練數(shù)據(jù)集可以看出�,有房的貸款者都按時償還了貸款,因此��,根結(jié)點的左子女為葉結(jié)點��,標(biāo)記為“拖欠貨款者二否”(見圖b)��。對于右子女�,我們需要繼續(xù)遞歸調(diào)用Hunt算法,直到所有的記錄都屬于同一個類為止�����。每次遞歸調(diào)用所形成的決策樹顯示在圖c和圖d中�����。
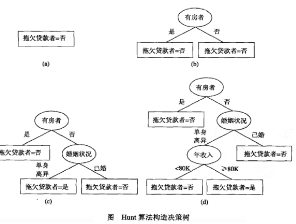
如果屬性值的每種組合都在訓(xùn)練數(shù)據(jù)中出現(xiàn),并且每種組合都具有唯一的類標(biāo)號����,則Hunt 算法是有效的����。但是對于大多數(shù)實際情況,這些假設(shè)太苛刻了�����,因此��,需要附加的條件來處理以下的情況:
算法的第二步所創(chuàng)建的子女結(jié)點可能為空����,即不存在與這些結(jié)點相關(guān)聯(lián)的記錄。如果沒有一個訓(xùn)練記錄包含與這樣的結(jié)點相關(guān)聯(lián)的屬性值組合���,這種情形就可能發(fā)生�����。這時�,該結(jié)點成為葉結(jié)點�����,類標(biāo)號為其父結(jié)點上訓(xùn)練記錄中的多數(shù)類。
在第二步����,如果與 Dt 相關(guān)聯(lián)的所有記錄都具有相同的屬性值(目標(biāo)屬性除外),則不可能進(jìn)一步劃分這些記錄����。在這種情況下,該結(jié)點為葉結(jié)點���,其標(biāo)號為與該結(jié)點相關(guān)聯(lián)的訓(xùn)練記錄中的多數(shù)類�。
此外���,在上面這個算法過程中�,你可能會疑惑:我們是依據(jù)什么原則來選取屬性測試條件的�����,例如為什第一次選擇“有房者”來作為測試條件���。事實上���,如果我們選擇的屬性測試條件不同���,那么對于同一數(shù)據(jù)集來說所建立的決策樹可能相差很大。如下圖所示為基于前面預(yù)測病人是患了Cold還是Flu的數(shù)據(jù)集所構(gòu)建出來的另外兩種情況的決策樹:
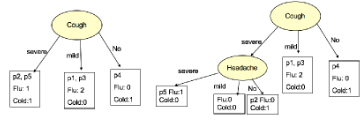
事實上���,在構(gòu)建決策樹時我們需要關(guān)心的問題包括:
How to build optimal Decision Tree?
How to choose attribute values at each decision point (node)?
How to choose number of branches at each node and attribute values for partitioning the data?
When to stop the growth of the tree?
我會在接下來的部分回答上述這些問題。
構(gòu)建決策樹進(jìn)階:Gini測度與劃分
構(gòu)建一棵最優(yōu)的決策樹是一個NP難問題����!所以我們只能采用一些啟發(fā)式策略來解決:
Choose an attribute to partition the data at the node such that each partition is as homogeneous (least impure) as possible. This means we would like to see most of the instances in each partition belonging to as few classes as possible and each partition should be as large as possible.
We can stop the growth of the tree if all the leaf nodes are largely dominated by a single class (that is the leaf nodes are nearly pure).
現(xiàn)在新的問題來了:如何評估節(jié)點的Impurity?通?����?梢允褂玫闹笜?biāo)有如下三個(實際應(yīng)用時����,只要選其中一個即可):
Gini Index
Entropy
Misclassification error
第一個可以用來評估節(jié)點Impurity的指標(biāo)是Gini系數(shù)。對于一個給定的節(jié)點 t�,它的Gini系數(shù)計算公式如下:
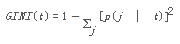
其中,p(j | t) is the relative frequency of class j at node t(即表示給定節(jié)點 t 中屬于類 j 的記錄所占的比例)���。通過這個計算公式你可以看出:
Maximum value of Gini index = (1 - 1/nc) when records are equally distributed among all classes, implying least interesting information or most impure.
Minimum is (0.0) when all records belong to one class, implying most interesting information or most pure or most homogeneous.
說到這里�,我們插一句題外話(如果你對這部分Background無感可以跳過)。你在生活中有沒有聽過基尼系數(shù)這個名詞�����?是的�,基尼系數(shù)本來是經(jīng)濟(jì)學(xué)里的一個概念?��;嵯禂?shù)是1943年美國經(jīng)濟(jì)學(xué)家阿爾伯特·赫希曼根據(jù)勞倫茨曲線所定義的判斷收入分配公平程度的指標(biāo)����?;嵯禂?shù)是比例數(shù)值,在0和1之間���,是國際上用來綜合考察居民內(nèi)部收入分配差異狀況的一個重要分析指標(biāo)��。其具體含義是指�,在全部居民收入中�,用于進(jìn)行不平均分配的那部分收入所占的比例?���;嵯禂?shù)最大為“1”�����,最小等于“0”��。前者表示居民之間的收入分配絕對不平均����,即100%的收入被一個單位的人全部占有了���;而后者則表示居民之間的收入分配絕對平均,即人與人之間收入完全平等����,沒有任何差異。但這兩種情況只是在理論上的絕對化形式���,在實際生活中一般不會出現(xiàn)�����。因此�,基尼系數(shù)的實際數(shù)值只能介于0~1之間,基尼系數(shù)越小收入分配越平均����,基尼系數(shù)越大收入分配越不平均。國際上通常把0.4作為貧富差距的警戒線�����,大于這一數(shù)值容易出現(xiàn)社會動蕩����。
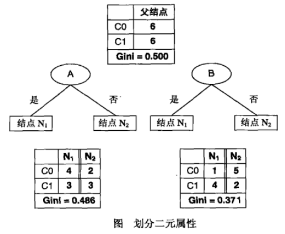
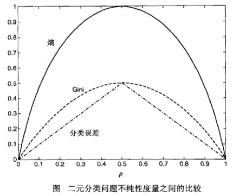
選擇最佳劃分的度量通常是根據(jù)劃分后子女結(jié)點不純性的程度。不純的程度越低��,類分布就越傾斜�����。例如�,類分布為 (0, 1)的結(jié)點具有零不純性,而均衡分布(0.5, 0.5)的結(jié)點具有最高的不純性?�,F(xiàn)在我們回過頭來看一個具體的計算例子?��,F(xiàn)在我們一共有6個records�����,以二元分類問題不純性度量值的比較為例����,下圖的意思表示有四個節(jié)點,然后分別計算了每一個節(jié)點的GINI系數(shù)值(注意決策樹中每一個內(nèi)節(jié)點都表示一種分支判斷��,也就可以將6個records分成幾類��,我們這里討論的是二元分類所以是分成兩個子類):

從上面的例子可以看出��,第一個結(jié)點�����,具有最低的不純性度量值�����,接下來節(jié)點的不純度度量值依次遞增�。為了確定測試條件的效果�,我們需要比較父結(jié)點(劃分前)的不純程度和子女結(jié)點(劃分后) 的不純程度,它們的差越大���,測試條件的效果就越好�����。增益Δ是一種可以用來確定劃分效果的標(biāo)準(zhǔn):
其中����,I(.) 是給定結(jié)點的不純性度量,N是父結(jié)點上的記錄總數(shù)��,k是屬性值的個數(shù)����,N(vj)是與子女結(jié)點 vj 相關(guān)聯(lián)的記錄個數(shù)。決策樹構(gòu)建算法通常選擇最大化增益Δ的測試條件�����,因為對所有的測試條件來說�����,I(parent)是一個不變的值����,所以最大化增益等價于最小化子女結(jié)點的不純性度量的加權(quán)平均值����。
考慮下面這個劃分的例子���。假設(shè)有兩種方法將數(shù)據(jù)劃分成較小的子集����。劃分前�����,Gini系數(shù)等于0.5�,因為屬于兩個類(C0和C1)的記錄個數(shù)相等。如果選擇屬性A來劃分?jǐn)?shù)據(jù)�����,節(jié)點N1的Gini系數(shù)為1?(4/7)2?(3/7)2=0.4898�����,而N2的Gini系數(shù)為1?(2/5)2?(3/5)2=0.48��,派生節(jié)點的Gini系數(shù)的加權(quán)平均為(7/12)×0.4898+(5/12)×0.48=0.486����。同理,我們還可以計算屬性B的Gini系數(shù)的加權(quán)平均為(7/12)×0.408+(5/12)×0.32=0.371�����。因為屬性B具有更小的Gini系數(shù)�����,所以它比屬性A更可取��。
考慮多分類的情況
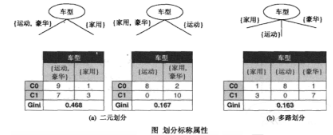
標(biāo)稱屬性可以產(chǎn)生二元劃分也可以產(chǎn)生多路劃分��,如下圖所示���。二元劃分的Gini系數(shù)的計算與二元屬性類似��。對于車型屬性第一種二元分類����,{運動����,豪華}的Gini系數(shù)是0.4922��,而{家用}的Gini系數(shù)是0.375����。這個劃分的Gini系數(shù)加權(quán)平均是:
類似地�����,對第二種二元劃分{運動}和{家用�����,豪華}����,Gini系數(shù)加權(quán)平均是0.167。第二種劃分的Gini系數(shù)相對更低����,因為其對應(yīng)的子集的純度更高。對于多路劃分����,需要計算每個屬性值的Gini系數(shù)。Gini({家用})=0.375��,Gini({運動})=0���,Gini({豪華})=0.219�����,所以多路劃分的Gini系數(shù)加權(quán)平均值為:
多路劃分的Gini系數(shù)比兩個二元劃分都小���。這是因為二元劃分實際上合并了多路劃分的某些輸出,自然降低了子集的純度����。
考慮特征值連續(xù)的情況
考慮下圖所示的例子,其中測試條件“年收入≤v”用來劃分拖欠貸款分類問題的訓(xùn)練記錄����。用窮舉方法確定 v 的值,將N個記錄中所有的屬性值都作為候選劃分點�。對每個候選v,都要掃描一次數(shù)據(jù)集����,統(tǒng)計年收入大于和小于v的記錄數(shù),然后計算每個候迭的Gini系數(shù),并從中選擇具有最小值的候選劃分點��。這種方法的計算代價顯然是高昂的���,因為對每個候選劃分點計算 Gini系數(shù)需要O(N)次操作��,由于有N個候選�����,總的計算復(fù)雜度為O(N2)����。為了降低計算復(fù)雜度�����, 按照年收入將訓(xùn)練記錄排序��,所需要的時間為O(NlogN)�,從兩個相鄰的排過序的屬性值中選擇中間值作為候選劃分點,得到候選劃分點55, 65, 72等�����。無論如何,與窮舉方法不同�����,在計算候選劃分點的Gini指標(biāo)時���,不需考察所有N個記錄。
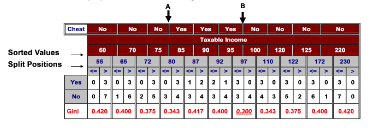
對第一個候選v=55�,沒有年收入小于$55K的記錄,所以年收入<$55K的派生結(jié)點的Gini系數(shù)是0�;另一方面,年收入≥$55K的樣本記錄數(shù)目分別為3(類Yes)和7(類No)�。如此一來,該結(jié)點的Gini系數(shù)是0.420����。該候選劃分的Gini系數(shù)的加權(quán)平均就等于0×0+1×0.42=0.42。
對第二個候選v=65����,通過更新上一個候選的類分布,就可以得到該候選的類分布��。更具體地說���,新的分布通過考察具有最低年收入(即$60K)的記錄的類標(biāo)號得到�。因為該記錄的類標(biāo)號是No所以類No的計數(shù)從0增加到1(對于年收入≤$65K),和從7降到6(對于年收入> $65K)�����,類Yes的分布保持不變����。新的候選劃分點的加權(quán)平均Gini系數(shù)為0.4。
重復(fù)這樣的計算���,直到算出所有候選的Gini系數(shù)值���。最佳的劃分點對應(yīng)于產(chǎn)生最小Gini系數(shù)值的點,即v=97�。該過程代價相對較低,因為更新每個候選劃分點的類分布所需的時間是一個常數(shù)���。該過程還可以進(jìn)一步優(yōu)化:僅考慮位于具有不同類標(biāo)號的兩個相鄰記錄之間的候選劃分點�。例如��,因為前三個排序后的記錄(分別具有年收入$60K���、 $70K和$75K)具有相同的類標(biāo)號��,所以最佳劃分點肯定不會在$60K和$75K之間��,因此�,候選劃分點 v = $55K、 $65K���、 $72K、 $87K�、 $92K、 $110K����、 $122K、 $172K 和 $230K都將被忽略��,因為它們都位于具有相同類標(biāo)號的相鄰記錄之間�����。該方法使得候選劃分點的個數(shù)從11個降到2個����。
其他純度測量指標(biāo)暨劃分標(biāo)準(zhǔn)
正如我們前面已經(jīng)提到的���,評估節(jié)點的Impurity可以是三個標(biāo)準(zhǔn)中的任何一個。而且我們已經(jīng)介紹了Gini系數(shù)����。
信息熵與信息增益
下面來談?wù)劻硗庖粋€可選的標(biāo)準(zhǔn):信息熵(entropy)。在信息論中���,熵是表示隨機(jī)變量不確定性的度量���。熵的取值越大,隨機(jī)變量的不確定性也越大��。
設(shè)X是一個取有限個值的離散隨機(jī)變量�����,其概率分布為
則隨機(jī)變量X的熵定義為
在上式中�����,如果pi=0�,則定義0log0=0。通常���,上式中的對數(shù)以2為底或以e為底��,這時熵的單位分別是比特(bit)或納特(nat)�����。由定義可知�,熵只依賴于 X 的分布,而與 X 的取值無關(guān)�,所以也可以將X 的熵記作 H(p),即
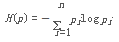
條件熵H(Y|X)表示在已知隨機(jī)變量X的條件下隨機(jī)變量Y的不確定性�,隨機(jī)變量X給定的條件下隨機(jī)變量Y的條件熵(conditional entropy)H(Y|X),定義為X給定條件下Y的條件概率分布的熵對X的數(shù)學(xué)期望:
就我們當(dāng)前所面對的問題而言�,如果給定一個節(jié)點 t��,它的(條件)熵計算公式如下:
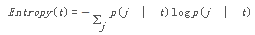
其中�,p(j | t) is the relative frequency of class j at node t(即表示給定節(jié)點 t 中屬于類 j 的記錄所占的比例)。通過這個計算公式你可以看出:
Maximum (lognc) when records are equally distributed among all classes implying least information
Minimum (0.0) when all records belong to one class, implying most information
還是來看一個具體的計算例子���,如下圖所示(基本情況與前面介紹Gini系數(shù)時的例子類似��,我們不再贅述):

以此為基礎(chǔ)��,我們要來定義信息增益(Information Gain)如下:
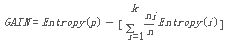
其中����,Parent Node, p is split into k partitions; ni is number of records in partition i.
與之前的情況相同,決策樹構(gòu)建算法通常選擇最大化信息增益的測試條件來對節(jié)點進(jìn)行劃分�。
使用信息增益的一個缺點在于:信息增益的大小是相對于訓(xùn)練數(shù)據(jù)集而言的。在分類問題困難時���,即訓(xùn)練數(shù)據(jù)集的經(jīng)驗熵比較大時�,信息增益會偏大�。反之,信息增益會偏小����。使用信息增益比(Information gain ratio)可以對這一問題進(jìn)行校正。
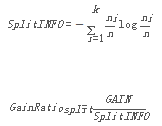
于是�,Higher entropy partitioning (large number of small partitions) is penalized!
分類誤差
給定一個節(jié)點t,它的分類誤差定義為:
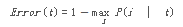
由此公式可知:
Maximum (1?1/nc) when records are equally distributed among all classes, implying least interesting information
Minimum (0.0) when all records belong to one class, implying most interesting information
話不多說��,還是一個簡單的算例:

下圖給出了二分類模型中����,熵、Gini系數(shù)���、分類誤差的比較情況�����。如果我們采用二分之一熵12H(p)的時候�,你會發(fā)現(xiàn)它與Gini系數(shù)將會相當(dāng)接近。
我們最后再來看一個Gini系數(shù)和分類誤差對比的例子:
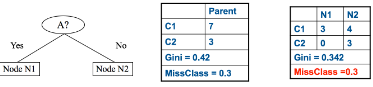
來計算一下加權(quán)平均的Gini系數(shù):
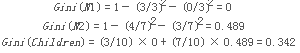
再來計算一下分類誤差:
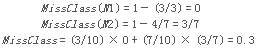
可見在這個例子中�����,Gini improves ! However��,Missclassification unchanged! 我們會在下一篇文章中繼續(xù)介紹關(guān)于ID3����、C4.5和CART算法的內(nèi)容,其中會更加具體地用到本文所介紹的各種純度評判標(biāo)準(zhǔn)���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情�����;

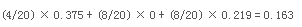
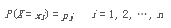
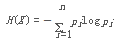
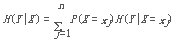










 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330