機(jī)器學(xué)習(xí)中特征選擇概述
1. 背景
1.1 問題
在機(jī)器學(xué)習(xí)的實(shí)際應(yīng)用中��,特征數(shù)量可能較多�,其中可能存在不相關(guān)的特征�,特征之間也可能存在相關(guān)性,容易導(dǎo)致如下的后果:
(1) 特征個(gè)數(shù)越多����,分析特征、訓(xùn)練模型所需的時(shí)間就越長��,模型也會越復(fù)雜��。
(2) 特征個(gè)數(shù)越多�,容易引起“維度災(zāi)難”,其推廣能力會下降��。
(3) 特征個(gè)數(shù)越多�����,容易導(dǎo)致機(jī)器學(xué)習(xí)中經(jīng)常出現(xiàn)的特征稀疏的問題�,導(dǎo)致模型效果下降。
(4)對于模型來說���,可能會導(dǎo)致不適定的情況�,即是解出的參數(shù)會因?yàn)闃颖镜奈⑿∽兓霈F(xiàn)大的波動�����。
特征選擇����,能剔除不相關(guān)、冗余����、沒有差異刻畫能力的特征�,從而達(dá)到減少特征個(gè)數(shù)����、減少訓(xùn)練或者運(yùn)行時(shí)間、提高模型精確度的作用��。
1.2 如何做特征選擇
特征選擇�����,即是指從全部特征中選取一個(gè)特征子集���,使得使構(gòu)造出來的模型效果更好���,推廣能力更強(qiáng)。如何做特征選擇呢����,如果要從全部特征中選擇一個(gè)最優(yōu)的子集,使得其在一定的評價(jià)標(biāo)準(zhǔn)下��,在當(dāng)前訓(xùn)練和測試數(shù)據(jù)上表現(xiàn)最好��。
從這個(gè)層面上理解,特征選擇可以看作三個(gè)問題:
(1)從原始特征集中選出固定數(shù)目的特征���,使得分類器的錯(cuò)誤率最小這是一個(gè)無約束的組合優(yōu)化問題;
(2)對于給定的允許錯(cuò)誤率����,求維數(shù)最小的特征子集,這是一種有約束的最優(yōu)化問題����;
(3)在錯(cuò)誤率和特征子集的維數(shù)之間進(jìn)行折中。
上述3個(gè)問題都是一個(gè)NP難問題�,當(dāng)特征維度較小時(shí),實(shí)現(xiàn)起來可行�����,但是當(dāng)維度較大時(shí)��,實(shí)現(xiàn)起來的復(fù)雜度很大���,所以實(shí)際應(yīng)用中很難實(shí)用����。上述三種特征選擇都屬十NP難的問題。由于求最優(yōu)解的計(jì)算量太大����,需要在一定的時(shí)間限制下尋找能得到較好次優(yōu)解的算法。以下介紹對次優(yōu)解的求解過程�。
2. 特征選擇的一般過程
特征選擇的一般過程可用圖1表示。首先從特征全集中產(chǎn)生出一個(gè)特征子集����,然后用評價(jià)函數(shù)對該特征子集進(jìn)行評價(jià),評價(jià)的結(jié)果與停止準(zhǔn)則進(jìn)行比較�,若滿足停止準(zhǔn)則就停止,否則就繼續(xù)產(chǎn)生下一組特征子集��,繼續(xù)進(jìn)行特征選擇����。選出來的特征子集一般還要驗(yàn)證其有效性。
綜上所述����,特征選擇過程一般包括:特征子集產(chǎn)生過程,評價(jià)函數(shù)�,停止準(zhǔn)則,驗(yàn)證過程,這4個(gè)部分�。
特征子集產(chǎn)生過程( Generation Procedure )
采取一定的子集選取辦法,為評價(jià)函數(shù)提供特征子集�����。根據(jù)搜索過程的方法的不同�,可以將特征選擇分為窮舉、啟發(fā)式�����、隨機(jī)幾種方法�����。
以上幾種方法不改變特征的原始屬性���,而有些方法通過對特征進(jìn)行空間變換,去除相關(guān)性��。比如PCA��、傅立葉變換���、小波變換等.
評價(jià)函數(shù)( EvaluationFunction )
評價(jià)函數(shù)是評價(jià)一個(gè)特征子集好壞程度的一個(gè)準(zhǔn)則����。評價(jià)函數(shù)的設(shè)計(jì)在不同的應(yīng)用場景下會不同,比如有的會根據(jù)其分布是否均勻判斷�����,或者看對最終模型的效果進(jìn)行判斷���。每種評價(jià)函數(shù)各有優(yōu)劣�,所以需要根據(jù)實(shí)際情況進(jìn)行選擇����。根據(jù)不同的評價(jià)準(zhǔn)則,可以分為:篩選器模型���、封裝器模型以及混合模型�����。過濾器模型是將特征選擇作為一個(gè)預(yù)處理過程�����,利用數(shù)據(jù)的內(nèi)在特性對選取的特征子集進(jìn)行評價(jià)��,獨(dú)立于學(xué)習(xí)算法�。而封裝器模型則將后續(xù)學(xué)習(xí)算法的結(jié)果作為特征評價(jià)準(zhǔn)則的一部分。根據(jù)評價(jià)函數(shù)的不同(與采用的分類方法是否關(guān)聯(lián))���,可以將特征選擇分為獨(dú)立性準(zhǔn)則����、關(guān)聯(lián)性度量����。
篩選器通過分析特征子集內(nèi)部的特點(diǎn)來衡量其好壞���。篩選器一般用作預(yù)處理��,與分類器的選擇無關(guān)��。篩選器的原理如下圖1:
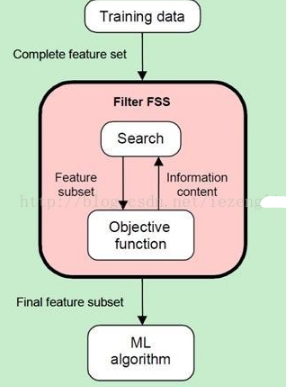
1. Filter原理(RicardoGutierrez-Osuna 2008 )
封裝器實(shí)質(zhì)上是一個(gè)分類器��,封裝器用選取的特征子集對樣本集進(jìn)行分類��,分類的精度作為衡量特征子集好壞的標(biāo)準(zhǔn)�。封裝器的原理如圖2所示。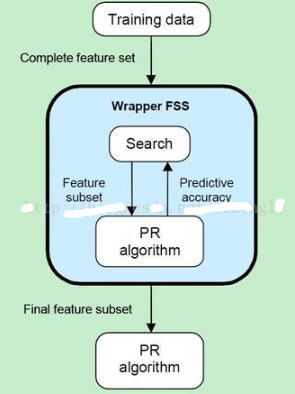
圖2. Wrapper原理(RicardoGutierrez-Osuna 2008 )
停止準(zhǔn)則( StoppingCriterion )
停止準(zhǔn)則是與評價(jià)函數(shù)相關(guān)的�,當(dāng)評價(jià)函數(shù)值達(dá)到某個(gè)閾值后就可停止搜索。比如對于獨(dú)立性準(zhǔn)則��,可以選擇樣本間平均間距最大�;對于關(guān)聯(lián)性度量,可以選擇使得分類器的準(zhǔn)確召回最高作為準(zhǔn)則���。
驗(yàn)證過程(Validation Procedure )
度量測試數(shù)據(jù)集上驗(yàn)證選出來的特征子集的有效性�����。最好采取與前期選擇方法不相關(guān)的度量方法����,這樣可以減少其間的耦合�。
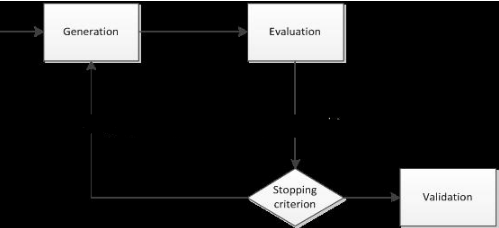
圖3特征選擇的過程 ( M.Dash and H. Liu 1997 )
這幾個(gè)過程中的不同方法可以看作一種組件,分別進(jìn)行組合����。比如可以采取啟發(fā)式特征篩選方法,結(jié)合相關(guān)性度量作為評價(jià)函數(shù)等�����。
3. 特征子集產(chǎn)生過程
產(chǎn)生過程是搜索特征子空間的過程。搜索的算法分為完全搜索(Complete)��,啟發(fā)式搜索(Heuristic)��,隨機(jī)搜索(Random)3大類�,如圖4所示。
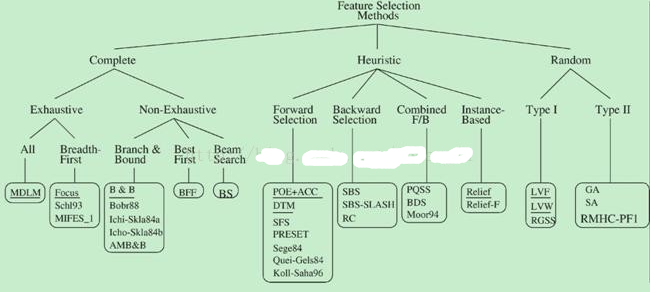
圖4 特征子集搜尋過程分類
當(dāng)然���,每種方法都不是互斥的���,也可以將多種方法結(jié)合起來使用,取長補(bǔ)短��。下面對常見的搜索算法進(jìn)行簡單介紹���。
3.1完全搜索(complete)
完全搜索分為窮舉搜索(Exhaustive)與非窮舉搜索(Non-Exhaustive)兩類。完全搜索部分考慮特征之間的相關(guān)性�����,從而能更好地找到最優(yōu)集合���。
A. 廣度優(yōu)先搜索( Breadth First Search )
算法描述:廣度優(yōu)先遍歷特征子空間���。
Step1:首先將根節(jié)點(diǎn)放入隊(duì)列中����。
Step2:從隊(duì)列中取出第一個(gè)節(jié)點(diǎn)���,并檢驗(yàn)它是否為目標(biāo)���。
substep:如果找到目標(biāo),則結(jié)束搜尋并回傳結(jié)果��。
substep:否則將它所有尚未檢驗(yàn)過的直接子節(jié)點(diǎn)加入隊(duì)列中��。
Step3:若隊(duì)列為空�,表示所有特征都檢查過了。結(jié)束搜尋并回傳「找不到目標(biāo)」�。
Step4:重復(fù)step2。
算法評價(jià):枚舉了所有的特征組合�,屬于窮舉搜索,時(shí)間復(fù)雜度是O(2n)��,實(shí)用性不高��。
B. 分支限界搜索( Branch and Bound )
算法描述:在窮舉搜索的基礎(chǔ)上加入分支限界�����。例如:若斷定某些分支不可能搜索出比當(dāng)前找到的最優(yōu)解更優(yōu)的解,則可以剪掉這些分支��。
C. 定向搜索(Beam Search )
算法描述:首先選擇N個(gè)得分最高的特征作為特征子集����,將其加入一個(gè)限制最大長度的優(yōu)先隊(duì)列,每次從隊(duì)列中取出得分最高的子集���,然后窮舉向該子集加入1個(gè)特征后產(chǎn)生的所有特征集��,將這些特征集加入隊(duì)列�����。
D. 最優(yōu)優(yōu)先搜索( Best First Search )
算法描述:與定向搜索類似����,唯一的不同點(diǎn)是不限制優(yōu)先隊(duì)列的長度�。
3.2啟發(fā)式搜索(heuristic)
啟發(fā)式搜索更多地采用貪心的思想���,某些算法沒有考慮特征之間的相關(guān)性�,而單純考慮單個(gè)特征對最終結(jié)果的影響,然而現(xiàn)實(shí)中的特征可能存在各種相關(guān)性�。某些算法也從這些方面進(jìn)行改進(jìn),比如增L去R選擇算法�����,序列浮動選擇�。
A. 序列前向選擇( SFS , Sequential Forward Selection )
算法描述:特征子集X從空集開始,每次選擇一個(gè)特征x加入特征子集X����,使得特征函數(shù)J( X)最優(yōu)。簡單說就是�,每次都選擇一個(gè)使得評價(jià)函數(shù)的取值達(dá)到更優(yōu)的特征加入,是一種簡單的貪心算法�。
算法評價(jià):缺點(diǎn)是只能加入特征而不能去除特征。例如:特征A完全依賴于特征B與C�,可以認(rèn)為如果加入了特征B與C則A就是多余的。假設(shè)序列前向選擇算法首先將A加入特征集��,然后又將B與C加入�����,那么特征子集中就包含了多余的特征A�����。
B. 序列后向選擇( SBS , Sequential Backward Selection )
算法描述:從特征全集O開始,每次從特征集O中剔除一個(gè)特征x��,使得剔除特征x后評價(jià)函數(shù)值達(dá)到最優(yōu)���。
算法評價(jià):序列后向選擇與序列前向選擇正好相反�����,它的缺點(diǎn)是特征只能去除不能加入��。
另外�����,SFS與SBS都屬于貪心算法�,容易陷入局部最優(yōu)值�����。
C. 雙向搜索( BDS , Bidirectional Search )
算法描述:使用序列前向選擇(SFS)從空集開始����,同時(shí)使用序列后向選擇(SBS)從全集開始搜索,當(dāng)兩者搜索到一個(gè)相同的特征子集C時(shí)停止搜索����。
雙向搜索的出發(fā)點(diǎn)是 。如下圖所示�,O點(diǎn)代表搜索起點(diǎn),A點(diǎn)代表搜索目標(biāo)�����?��;疑膱A代表單向搜索可能的搜索范圍���,綠色的2個(gè)圓表示某次雙向搜索的搜索范圍,容易證明綠色的面積必定要比灰色的要小��。
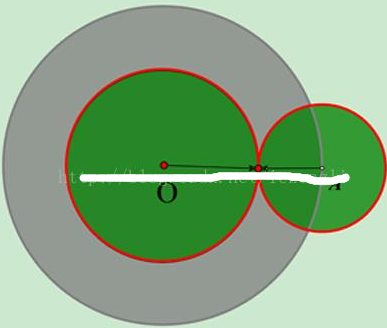
圖5. 雙向搜索
D. 增L去R選擇算法( LRS , Plus-L Minus-R Selection )
該算法有兩種形式:
<1>算法從空集開始�����,每輪先加入L個(gè)特征�����,然后從中去除R個(gè)特征,使得評價(jià)函數(shù)值最優(yōu)�。( L> R )
<2> 算法從全集開始,每輪先去除R個(gè)特征���,然后加入L個(gè)特征�����,使得評價(jià)函數(shù)值最優(yōu)����。( L< R )
算法評價(jià):增L去R選擇算法結(jié)合了序列前向選擇與序列后向選擇思想����, L與R的選擇是算法的關(guān)鍵。
E. 序列浮動選擇( Sequential Floating Selection )
算法描述:序列浮動選擇由增L去R選擇算法發(fā)展而來���,該算法與增L去R選擇算法的不同之處在于:序列浮動選擇的L與R不是固定的�,而是“浮動”的��,也就是會變化的��。
序列浮動選擇根據(jù)搜索方向的不同,有以下兩種變種����。
<1>序列浮動前向選擇( SFFS, Sequential Floating Forward Selection )
算法描述:從空集開始,每輪在未選擇的特征中選擇一個(gè)子集x����,使加入子集x后評價(jià)函數(shù)達(dá)到最優(yōu)�,然后在已選擇的特征中選擇子集z,使剔除子集z后評價(jià)函數(shù)達(dá)到最優(yōu)���。
<2>序列浮動后向選擇( SFBS, Sequential Floating Backward Selection )
算法描述:與SFFS類似�,不同之處在于SFBS是從全集開始��,每輪先剔除特征����,然后加入特征。
算法評價(jià):序列浮動選擇結(jié)合了序列前向選擇�����、序列后向選擇�����、增L去R選擇的特點(diǎn),并彌補(bǔ)了它們的缺點(diǎn)����。
F. 決策樹( Decision Tree Method , DTM)
算法描述:在訓(xùn)練樣本集上運(yùn)行C4.5或其他決策樹生成算法,待決策樹充分生長后�����,再在樹上運(yùn)行剪枝算法�。則最終決策樹各分支處的特征就是選出來的特征子集了。決策樹方法一般使用信息增益作為評價(jià)函數(shù)���。
3.3 隨機(jī)算法(random)
A. 隨機(jī)產(chǎn)生序列選擇算法(RGSS, Random Generation plus Sequential Selection)
算法描述:隨機(jī)產(chǎn)生一個(gè)特征子集����,然后在該子集上執(zhí)行SFS與SBS算法����。
算法評價(jià):可作為SFS與SBS的補(bǔ)充,用于跳出局部最優(yōu)值�����。
B. 模擬退火算法( SA, Simulated Annealing )
算法評價(jià):模擬退火一定程度克服了序列搜索算法容易陷入局部最優(yōu)值的缺點(diǎn),但是若最優(yōu)解的區(qū)域太?���。ㄈ缢^的“高爾夫球洞”地形),則模擬退火難以求解�。
C. 遺傳算法( GA, Genetic Algorithms )
算法描述:首先隨機(jī)產(chǎn)生一批特征子集,并用評價(jià)函數(shù)給這些特征子集評分�����,然后通過交叉����、突變等操作繁殖出下一代的特征子集����,并且評分越高的特征子集被選中參加繁殖的概率越高。這樣經(jīng)過N代的繁殖和優(yōu)勝劣汰后�����,種群中就可能產(chǎn)生了評價(jià)函數(shù)值最高的特征子集��。
隨機(jī)算法的共同缺點(diǎn):依賴于隨機(jī)因素����,有實(shí)驗(yàn)結(jié)果難以重現(xiàn)����。
3.4 特征變換方法
A. PCA
PCA(Principal ComponentAnalysis)����,中文名為主成份變換,是一種坐標(biāo)變換的方法�����,可以去除冗余特征��。
具體特征變換過程中����,去掉較小的特征值,從而達(dá)到去噪�����、去除相關(guān)性和特征減少的目的��。
B. 小波變換
小波也是一種特征空間變換的方法�,相較于傅立葉變換�,小波變換能更好地適應(yīng)劇烈的變換�。
4. 評價(jià)函數(shù)
評價(jià)函數(shù)的作用是評價(jià)產(chǎn)生過程所提供的特征子集的好壞。
4.1 獨(dú)立準(zhǔn)則
獨(dú)立準(zhǔn)則通常應(yīng)用在過濾器模型的特征選擇算法中�,試圖通過訓(xùn)練數(shù)據(jù)的內(nèi)在特性對所選擇的特征子集進(jìn)行評價(jià),獨(dú)立于特定的學(xué)習(xí)算法��。通常包括:距離度置�、信息度量,關(guān)聯(lián)性度量和一致性度量����。
在做比較通用的特征選擇方法時(shí),建議采用這種方法����,因?yàn)檫@是獨(dú)立于特定機(jī)器學(xué)習(xí)算法的���,適用于大多數(shù)后續(xù)機(jī)器學(xué)習(xí)方法���。
4.2關(guān)聯(lián)性度量
關(guān)聯(lián)準(zhǔn)則通常應(yīng)用在封裝器模型的特征選擇算法中,先確定一個(gè)學(xué)習(xí)算法并且利用機(jī)器學(xué)習(xí)算法的性能作為評價(jià)準(zhǔn)則���。對于特定的學(xué)習(xí)算法來說���,通?���?梢哉业奖冗^濾器模型更好的特征子集�,但是需要多次調(diào)用學(xué)習(xí)算法,一般時(shí)間開銷較大���,并且可能不適介其它學(xué)習(xí)算法����。
在我們做模式分類算法時(shí)���,可以根據(jù)自己的實(shí)際情況�,采用關(guān)聯(lián)性度量方法����,這樣能更好地和我們的分類方法相結(jié)合,通常能找到比較好的子集�。
綜上,兩種種評價(jià)函數(shù)的優(yōu)缺點(diǎn)和適用情況總結(jié)如下:

4.3 常見的評價(jià)函數(shù)
A. 卡方檢驗(yàn)
卡方檢驗(yàn)最基本的思想就是通過觀察實(shí)際值與理論值的偏差來確定理論的正確與否.具體做的時(shí)候常常先假設(shè)兩個(gè)變量確實(shí)是獨(dú)立的(“原假設(shè)”),然后觀察實(shí)際值(觀察值)與理論值(這個(gè)理論值是指“如果兩者確實(shí)獨(dú)立”的情況下應(yīng)該有的值)的偏差程度,如果偏差足夠小,我們就認(rèn)為誤差是很自然的樣本誤差,是測量手段不夠精確導(dǎo)致或者偶然發(fā)生的,兩者確確實(shí)實(shí)是獨(dú)立的,此時(shí)就接受原假設(shè)�;如果偏差大到一定程度,使得這樣的誤差不太可能是偶然產(chǎn)生或者測量不精確所致,我們就認(rèn)為兩者實(shí)際上是相關(guān)的,即否定原假設(shè),而接受備擇假設(shè).
理論值為E,實(shí)際值為x,偏差程度的計(jì)算公式為:
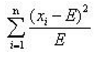
這個(gè)式子就是開方檢驗(yàn)使用的差值衡量公式.當(dāng)提供了數(shù)個(gè)樣本的觀察值x1,x2,……xi,……xn之后,代入到式中就可以求得開方值,用這個(gè)值與事先設(shè)定的閾值比較,如果大于閾值(即偏差很大),就認(rèn)為原假設(shè)不成立,反之則認(rèn)為原假設(shè)成立.[請參考我的另外一篇卡方檢驗(yàn)的普及文章]
B. 相關(guān)性( Correlation)
運(yùn)用相關(guān)性來度量特征子集的好壞是基于這樣一個(gè)假設(shè):好的特征子集所包含的特征應(yīng)該是與分類的相關(guān)度較高(相關(guān)度高),而特征之間相關(guān)度較低的(冗余度低)���。
可以使用線性相關(guān)系數(shù)(correlationcoefficient) 來衡量向量之間線性相關(guān)度�。
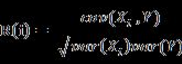
C. 距離(Distance Metrics )
運(yùn)用距離度量進(jìn)行特征選擇是基于這樣的假設(shè):好的特征子集應(yīng)該使得屬于同一類的樣本距離盡可能小,屬于不同類的樣本之間的距離盡可能遠(yuǎn)���。同樣基于此種思想的有fisher判別分類反法��。
常用的距離度量(相似性度量)包括歐氏距離���、標(biāo)準(zhǔn)化歐氏距離����、馬氏距離等��。
D. 信息增益( Information Gain )
假設(shè)存在離散變量Y�,Y中的取值包括{y1�����,y2,….���,ym} ��,yi出現(xiàn)的概率為Pi�。則Y的信息熵定義為:
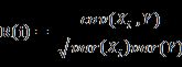
信息熵是對不確定性的一種描述。具有如下特性:若集合Y的元素分布不均���,則其信息熵越?����?;若Y分布越平均��,則其信息熵越大��。在極端的情況下:若Y只能取一個(gè)值���,即P1=1��,則H(Y)取最小值0����;反之若各種取值出現(xiàn)的概率都相等�����,即都是1/m����,則H(Y)取最大值log2m。
對于一個(gè)特征t,系統(tǒng)有它和沒它的時(shí)候信息量各是多少,兩者的差值就是這個(gè)特征給系統(tǒng)帶來的信息量.有它即信息熵,無它則是條件熵.
條件熵:計(jì)算當(dāng)一個(gè)特征t不能變化時(shí),系統(tǒng)的信息量是多少.
對于一個(gè)特征X,它可能的取值有n多種(x1,x2,……,xn),計(jì)算每個(gè)值的條件熵,再取平均值.
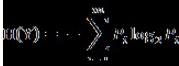
在文本分類中,特征詞t的取值只有t(代表t出現(xiàn))和(代表t不出現(xiàn)).那么
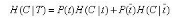
最后,信息增益
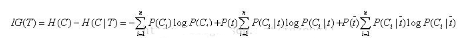
但信息增益最大的問題[對于多分類存在這個(gè)問題��,對于二分類則不存在]還在于它只能考察特征對整個(gè)系統(tǒng)的貢獻(xiàn),而不能具體到某個(gè)類別上,這就使得它只適合用來做所謂“全局”的特征選擇(指所有的類都使用相同的特征集合),而無法做“本地”的特征選擇(每個(gè)類別有自己的特征集合,因?yàn)橛械脑~,對這個(gè)類別很有區(qū)分度,對另一個(gè)類別則無足輕重).
同時(shí)�,信息熵會偏向于特征的分布較多的特征,所以改進(jìn)方法是可以嘗試信息增益率��。
E. 分類器錯(cuò)誤率(Classifier error rate )
使用特定的分類器��,用給定的特征子集對樣本集進(jìn)行分類���,用分類的精度來衡量特征子集的好壞��。
以上4種度量方法中��,卡方檢驗(yàn)���、相關(guān)性、距離、信息增益�、屬于篩選器,而分類器錯(cuò)誤率屬于封裝器�。篩選器由于與具體的分類算法無關(guān),因此其在不同的分類算法之間的推廣能力較強(qiáng)���,而且計(jì)算量也較小���。而封裝器由于在評價(jià)的過程中應(yīng)用了具體的分類算法進(jìn)行分類,因此其推廣到其他分類算法的效果可能較差���,而且計(jì)算量也較大�。
5. 應(yīng)用實(shí)例
此處舉出一個(gè)實(shí)際應(yīng)用中的栗子����,基本方法為啟發(fā)式搜索(順序添加)+關(guān)聯(lián)性準(zhǔn)則(卡方檢驗(yàn)、最大熵)+準(zhǔn)召停止準(zhǔn)則�����。以下詳細(xì)介紹操作步驟�。 數(shù)據(jù)分析師培訓(xùn)
Step1:統(tǒng)計(jì)每種特征的卡方值.
Step2:取topN的特征值.
Step3:帶入模型訓(xùn)練,并在測試集合上計(jì)算準(zhǔn)確和召回.
Step4:如果達(dá)標(biāo)�,停止��,否則�����,gotostep2.
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330