SPSS分析技術:兩個獨立樣本的非參數檢驗
在醫(yī)學類研究中��,經常會遇到治療效果無法量化���,但需要比較不同治療方法優(yōu)劣的需求��。例如�����,比較止痛藥的效果��,疼痛程度無法準確量化����,只能用主觀打分來描述;理療復健方法的優(yōu)劣也無法量化���,只能通過病人的情況粗略劃分成臥床�����,部分自主等層次����。當遇到這樣無法量化數據的比較要求時,應該如何進行比較呢����?兩個樣本的非參數檢驗是合適的分析方法。下面將介紹兩個獨立樣本的非參數檢驗方法����。
兩個獨立樣本的非參數檢驗
單個樣本的非參數檢驗對比的是樣本分布與已知分布��,從而得出隨機樣本所代表的總體是否服從已知分布��。兩獨立樣本的非參數檢驗是對兩個獨立樣本的分布情況直接進行對比�,目的是獲得關于兩總體分布狀況差異大小的信息。這與單個樣本假設檢驗和兩個樣本假設檢驗是一個套路���。
SPSS提供了4種檢驗方法:Mann-Whitney U檢驗(曼-惠特尼U檢驗)�、K-S檢驗����、Wald-Wolfowitz檢驗(隨機序列檢驗)和Moses極端反應檢驗。它們的原假設都是兩個樣本來自的總體分布沒有顯著性差異��,只不過它們的分析方法不同�。
Mann-Whitney U檢驗
Mann-Whitney U檢驗又稱Mann-Whitney秩和檢驗�����,可用于對兩總體分布的比例判斷��。其原假設為:兩個獨立樣本來自的兩個總體的分布無顯著差異�����。Mann-Whitney U檢驗通過對兩組樣本平均秩的研究來實現判斷�。
Mann-Whitney U檢驗原理:將兩個樣本混合后按升序排列���,得到每個樣本值的秩(排名)����,然后分別求得兩組樣本的平均秩��,并對這兩個平均秩進行比較�。如果兩個總體分布無顯著差異,其秩應該差別不大���,從而兩組樣本的平均秩差別較?����?���;反之,若兩總體差異顯著����,則二者的平均秩會有較大差異。此外���,Mann-Whitney U檢驗還要計算樣本A的秩大于樣本B的秩的個數U1���,以及樣本B的秩優(yōu)于A的秩的個數U2��,如果總體分布無顯著差異���,則兩者應該接近���;反之,若兩總體差異顯著����,則二者的平均秩會有較大差異��。
兩獨立樣本K-S檢驗
檢驗原理:首先將兩獨立樣本的數據混合并按升序排列���,然后分布計算兩個獨立樣本秩的累計頻率,并求得兩個累計頻率的差值序列數據以獲得D統(tǒng)計量����。SPSS將自動計算D統(tǒng)計量的概率P值,如果P值大于顯著性水平���,則接受原假設����;反之��,則拒絕原假設��,即兩個樣本來自的總體分布差異顯著�����。
兩個獨立樣本Wald-Wolfowitz檢驗
將兩組樣本混合并升序排列��。同時����,兩組樣本的每個觀測值對應的樣本組標志值序列也將隨之重新排序����,求出此游程��。如果所得游程數較小��,說明兩總體的分布差異較大���;反之�,則不存在顯著性差異��。同時SPSS將據此自動計算相伴概率P值���,如果P值大于顯著性水平臨界值,則接受原假設�;反之則拒絕原假設,即兩個樣本來自的總體分布差異顯著�����。
兩獨立樣本Moses極端反應檢驗
原理為:將一組樣本作為控制樣本��;另一組作為比較樣本。一般按升序排列的第一個值定義控制組��,第二個值定義比較組�。以控制組作為參照,檢驗比較組相對于控制組是否出現極端反應��。為此����,將兩組樣本混合并升序排列,求得控制樣本最高秩次和最低秩次之間包含的觀測值個數�����,即跨度�����,以及去掉兩個極端值后的截頭跨度�����。如果跨度和截頭跨度都很小�,說明比較樣本可能存在極端反應,兩總體的分布差異顯著;如果比較樣本沒有出現極端反應��,則兩總體分布無顯著差異���。
范例分析
現在由一份運用藥物治療和物理治療方法對中風患者治療結果的數據�,治療結果被分成5各層次:正常����、可以自主活動、部分肢體可以自主活動�����、臥床和無自理能力���;總共記錄了100位患者的治療效果��,需要分析兩種治療方法的結果是否有顯著性差異�����。
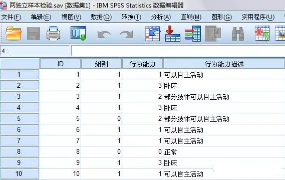
分析步驟
1、選擇菜單【分析】-【非參數檢驗】-【舊對話框】-【2個獨立樣本】��,在跳出的對話框中����,做如下操作���,然后點擊確定。
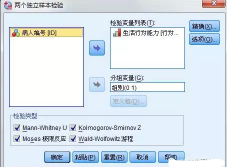
2�����、或者也可以選擇【分析】-【非參數檢驗】-【獨立樣本】����,跳出如下對話框:
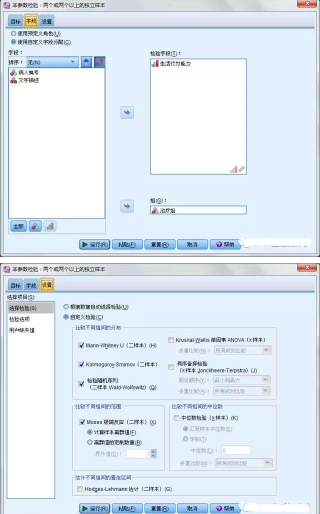
在字段頁將生活行為能力選為檢驗字段,將治療組選為組�����;在設置頁選中所有4種兩個樣本的非參數檢驗方法��。最后點擊運行��。
結果分析
兩種操作方式的計算結果是一致的���,由于第二種操作的顯示結果是綜合顯示��,所以選取第二種操作的顯示結果進行講解�。
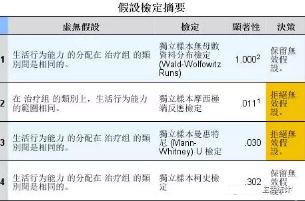
從結果可知;K-S檢驗和Wald-Wolfowitz游程檢驗的結果是接受原假設��,即兩種治療方法的效果沒有顯著性差異���;Moses檢驗和Mann-Whitney U檢驗的結果是拒絕原假設��,即兩種治療方法的效果有顯著性差異�;所以����,不同的檢驗方法可能會有不同的結論,這也說明了非參數檢驗是一種近似的檢驗方法����,提示我們一定要根據數據的性質和檢驗方法的側重點合理的選擇檢驗方法。
可以對比不同的檢驗方法原理��,Mann-Whitney U檢驗常用判別兩獨立樣本所屬的總體是否具有相同分布��,Moses檢驗和K-S檢驗主要用于檢驗兩個樣本是否來自相同總體����,所以本題中�����,建議選擇Mann-Whitney U檢驗的分析結果,即兩種治療方法的治療效果有顯著性差異���。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學習CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330