Python數(shù)據(jù)挖掘之線性回歸知識及預(yù)測糖尿病實(shí)例
今天主要講述的內(nèi)容是關(guān)于一元線性回歸的知識,Python實(shí)現(xiàn)����,包括以下內(nèi)容:
1.機(jī)器學(xué)習(xí)常用數(shù)據(jù)集介紹
2.什么是線性回顧
3.LinearRegression使用方法
4.線性回歸判斷糖尿病
希望這篇文章對你有所幫助,尤其是剛剛接觸數(shù)據(jù)挖掘以及大數(shù)據(jù)的同學(xué)���,同時(shí)準(zhǔn)備嘗試以案例為主的方式進(jìn)行講解���。如果文章中存在不足或錯(cuò)誤的地方����,還請海涵~
同時(shí)這篇文章是我上課的內(nèi)容����,所以參考了一些知識,強(qiáng)烈推薦大家學(xué)習(xí)斯坦福的機(jī)器學(xué)習(xí)Ng教授課程和Scikit-Learn中的內(nèi)容�。由于自己數(shù)學(xué)不是很好,自己也還在學(xué)習(xí)中��,所以文章以代碼和一元線性回歸為主����,數(shù)學(xué)方面的當(dāng)自己學(xué)到一定的程度��,才能進(jìn)行深入的分享及介紹����。抱歉~
一. 數(shù)據(jù)集介紹
1.diabetes dataset數(shù)據(jù)集
數(shù)據(jù)集參考:http://scikit-learn.org/stable/datasets/
這是一個(gè)糖尿病的數(shù)據(jù)集,主要包括442行數(shù)據(jù)��,10個(gè)屬性值,分別是:Age(年齡)�����、性別(Sex)�、Body mass index(體質(zhì)指數(shù))、Average Blood Pressure(平均血壓)����、S1~S6一年后疾病級數(shù)指標(biāo)。Target為一年后患疾病的定量指標(biāo)����。
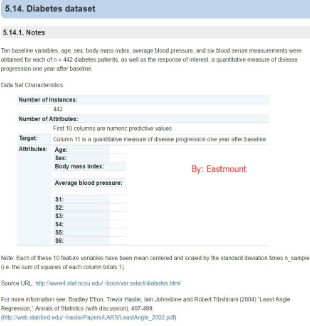
輸出如下所示:
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 27 02:37:05 2016
@author: yxz15
"""
from sklearn import datasets
diabetes = datasets.load_diabetes() #載入數(shù)據(jù)
print diabetes.data #數(shù)據(jù)
print diabetes.target #類標(biāo)
print u'總行數(shù): ', len(diabetes.data), len(diabetes.target) #數(shù)據(jù)總行數(shù)
print u'特征數(shù): ', len(diabetes.data[0]) #每行數(shù)據(jù)集維數(shù)
print u'數(shù)據(jù)類型: ', diabetes.data.shape #類型
print type(diabetes.data), type(diabetes.target) #數(shù)據(jù)集類型
"""
[[ 0.03807591 0.05068012 0.06169621 ..., -0.00259226 0.01990842
-0.01764613]
[-0.00188202 -0.04464164 -0.05147406 ..., -0.03949338 -0.06832974
-0.09220405]
...
[-0.04547248 -0.04464164 -0.0730303 ..., -0.03949338 -0.00421986
0.00306441]]
[ 151. 75. 141. 206. 135. 97. 138. 63. 110. 310. 101.
...
64. 48. 178. 104. 132. 220. 57.]
總行數(shù): 442 442
特征數(shù): 10
數(shù)據(jù)類型: (442L, 10L)
<type 'numpy.ndarray'> <type 'numpy.ndarray'>
"""
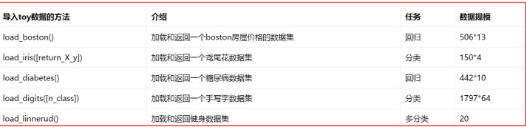
2.sklearn常見數(shù)據(jù)集
常見的sklearn數(shù)據(jù)集包括,強(qiáng)烈推薦下面這篇文章:
sklearn包含一些不許要下載的toy數(shù)據(jù)集��,見下表��,包括波士頓房屋數(shù)據(jù)集����、鳶尾花數(shù)據(jù)集、糖尿病數(shù)據(jù)集�����、手寫字?jǐn)?shù)據(jù)集和健身數(shù)據(jù)集等。
3.UCI數(shù)據(jù)集
二. 什么是線性回歸
1.機(jī)器學(xué)習(xí)簡述
機(jī)器學(xué)習(xí)(Machine Learning )包括:
a.監(jiān)督學(xué)習(xí)(Supervised Learning):回歸(Regression)���、分類(Classification)
例:訓(xùn)練過程中知道結(jié)果�����。小孩給水果分類�,給他蘋果告訴他是蘋果�����,反復(fù)訓(xùn)練學(xué)習(xí)��。在給他說過�����,問他是什么�����?他回答準(zhǔn)確����,如果是桃子,他不能回答為蘋果����。
b.無監(jiān)督學(xué)習(xí)(Unsupervised Learning):聚類(Clustering)
例:訓(xùn)練過程中不知道結(jié)果。給小孩一堆水果����,如蘋果、橘子���、桃子��,小孩開始不知道需要分類的水果是什么�,讓小孩對水果進(jìn)行分類�����。分類完成后��,給他一個(gè)蘋果����,小孩應(yīng)該把它放到蘋果堆中。
c.增強(qiáng)學(xué)習(xí)(Reinforcement Learning)
例:ML過程中��,對行為做出評價(jià),評價(jià)有正面的和負(fù)面兩種���。通過學(xué)習(xí)評價(jià)����,程序應(yīng)做出更好評價(jià)的行為����。
d.推薦系統(tǒng)(Recommender System)
2.斯坦福公開課:第二課 單變量線性回歸
這是NG教授的很著名的課程,這里主要引用52nlp的文章�,真的太完美了。推薦閱讀該作者的更多文章:
Coursera公開課筆記: 斯坦福大學(xué)機(jī)器學(xué)習(xí)第二課"單變量線性回歸(Linear regression with one variable)"
<1>模型表示(Model Representation)
房屋價(jià)格預(yù)測問題�����,有監(jiān)督學(xué)習(xí)問題��。每個(gè)樣本的輸入都有正確輸出或答案�,它也是一個(gè)回歸問題,預(yù)測一個(gè)真實(shí)值的出書�。
訓(xùn)練集表示如下:
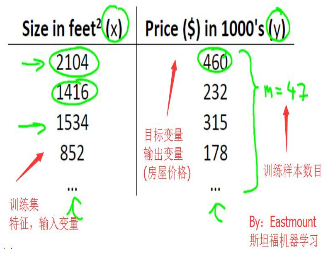
對于房價(jià)預(yù)測問題,訊息過程如下所示:
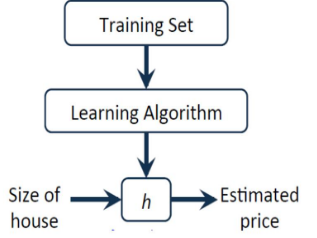
其中x代表房屋的大小�,y代表預(yù)測的價(jià)格�,h(hypothesis)將輸入變量映射到輸出變量y中��,如何表示h呢�?可以表示如下公式����,簡寫為h(x),即帶一個(gè)變量的線性回歸或單變量線性回歸問題��。
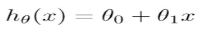
<2>成本函數(shù)(Cost Function)
對于上面的公式函數(shù)h(x)��,如何求theta0和theta1參數(shù)呢��?
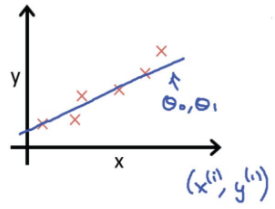
構(gòu)想: 對于訓(xùn)練集(x, y)���,選取參數(shù)θ0, θ1使得hθ(x)盡可能的接近y��。如何做呢��?一種做法就是求訓(xùn)練集的平方誤差函數(shù)(squared error function)�。
Cost Function可表示為:
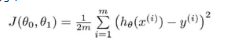
并且選取合適的參數(shù)使其最小化���,數(shù)學(xué)表示如下:
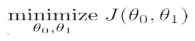
總的來說����,線性回歸主要包括一下四個(gè)部分,分別是Hypothesis����、Parameters、Cost Function�����、Goal����。右圖位簡化版,theta0賦值為0����。

然后令θ1分別取1、0.5���、-0.5等值�����,同步對比hθ(x)和J(θ0,θ1)在二維坐標(biāo)系中的變化情況���,具體可參考原PPT中的對比圖�����,很直觀。
<3>梯度下降(Gradient descent)
應(yīng)用的場景之一最小值問題:
對于一些函數(shù)�����,例如J(θ0,θ1)
目標(biāo): minθ0,θ1J(θ0,θ1)
方法的框架:
a. 給θ0, θ1一個(gè)初始值���,例如都等于0;
b. 每次改變θ0, θ1的時(shí)候都保持J(θ0,θ1)遞減�����,直到達(dá)到一個(gè)我們滿意的最小值��;
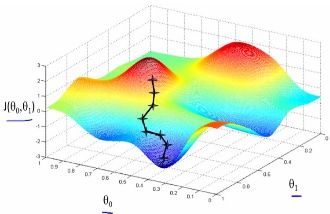
對于任一J(θ0,θ1) , 初始位置不同��,最終達(dá)到的極小值點(diǎn)也不同�,例如以下例子:
3.一元回歸模型
<1>什么是線性回歸�����?
回歸函數(shù)的具體解釋和定義,可查看任何一本“概率論與數(shù)理統(tǒng)計(jì)”的書�����。我看的是“陳希孺”的�。
這里我講幾點(diǎn):
1)統(tǒng)計(jì)回歸分析的任務(wù),就在于根據(jù) x1,x2,...,xp 線性回歸和Y的觀察值�����,去估計(jì)函數(shù)f�,尋求變量之間近似的函數(shù)關(guān)系。
2)我們常用的是����,假定f函數(shù)的數(shù)學(xué)形式已知,其中若干個(gè)參數(shù)未知����,要通過自變量和因變量的觀察值去估計(jì)未知的參數(shù)值。這叫“參數(shù)回歸”�。其中應(yīng)用最廣泛的是f為線性函數(shù)的假設(shè):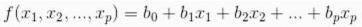
這種情況叫做“線性回歸”。
3)自變量只有一個(gè)時(shí)����,叫做一元線性回歸����。
f(x) = b0+b1x
自變量有多個(gè)時(shí)����,叫做多元線性回歸。
f(x1,x2,...,xp) = b0 + b1x1 + b2x2 + ... + bpxp
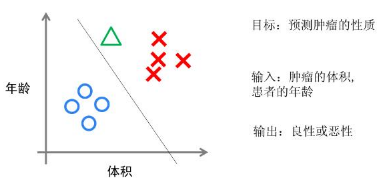
4)分類(Classification)與回歸(Regression)都屬于監(jiān)督學(xué)習(xí)���,他們的區(qū)別在于:
分類:用于預(yù)測有限的離散值,如是否得了癌癥(0����,1),或手寫數(shù)字的判斷����,是0,1,2,3,4,5,6,7,8還是9等。分類中�,預(yù)測的可能的結(jié)果是有限的,且提前給定的���。
回歸:用于預(yù)測實(shí)數(shù)值���,如給定了房子的面積��,地段��,和房間數(shù)���,預(yù)測房子的價(jià)格。
<2>一元線性回歸
假設(shè):我們要預(yù)測房價(jià)���。當(dāng)前自變量(輸入特征)是房子面積x�����,因變量是房價(jià)y.給定了一批訓(xùn)練集數(shù)據(jù)���。我們要做的是利用手上的訓(xùn)練集數(shù)據(jù),得出x與y之間的函數(shù)f關(guān)系�����,并用f函數(shù)來預(yù)測任意面積x對應(yīng)的房價(jià)�����。
假設(shè)x與y是線性關(guān)系�,則我們可以接著假設(shè)一元線性回歸函數(shù)如下來代表y的預(yù)測值:
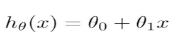
我們有訓(xùn)練集了�,那么問題就成了如何利用現(xiàn)有的訓(xùn)練集來判定未知參數(shù) (θ0,θ1) 的值����,使其讓h的值更接近實(shí)際值y? 訓(xùn)練集指的是已知x,y值的數(shù)據(jù)集合!
一種方法是計(jì)算它的成本函數(shù)(Cost function)����,即預(yù)測出來的h的值與實(shí)際值y之間的方差的大小來決定當(dāng)前的(θ0,θ1)值是否是最優(yōu)的!
常用的成本函數(shù)是最小二乘法:
<3>模型總結(jié)
整個(gè)一元線性回歸通過下面這張圖總結(jié)即可:

最后���,梯度下降和多元回歸模型將繼續(xù)學(xué)習(xí)����,當(dāng)我學(xué)到一定程度�����,再進(jìn)行分享���。
三. LinearRegression使用方法
LinearRegression模型在Sklearn.linear_model下,它主要是通過fit(x,y)的方法來訓(xùn)練模型�,其中x為數(shù)據(jù)的屬性,y為所屬類型��。
sklearn中引用回歸模型的代碼如下:
from sklearn import linear_model #導(dǎo)入線性模型
regr = linear_model.LinearRegression() #使用線性回歸
print regr
輸出的函數(shù)原型如下所示:
LinearRegression(copy_X=True,
fit_intercept=True,
n_jobs=1,
normalize=False)
fit(x, y): 訓(xùn)練。分析模型參數(shù)�,填充數(shù)據(jù)集。其中x為特征��,y位標(biāo)記或類屬性�����。
predict(): 預(yù)測����。它通過fit()算出的模型參數(shù)構(gòu)成的模型,對解釋變量進(jìn)行預(yù)測其類屬性��。預(yù)測方法將返回預(yù)測值y_pred��。
這里推薦"搬磚小工053"大神的文章�����,非常不錯(cuò)��,強(qiáng)烈推薦�。
引用他文章的例子,參考:scikit-learn : 線性回歸���,多元回歸���,多項(xiàng)式回歸
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 28 00:44:55 2016
@author: yxz15
"""
from sklearn import linear_model #導(dǎo)入線性模型
import matplotlib.pyplot as plt #繪圖
import numpy as np
#X表示匹薩尺寸 Y表示匹薩價(jià)格
X = [[6], [8], [10], [14], [18]]
Y = [[7], [9], [13], [17.5], [18]]
print u'數(shù)據(jù)集X: ', X
print u'數(shù)據(jù)集Y: ', Y
#回歸訓(xùn)練
clf = linear_model.LinearRegression() #使用線性回歸
clf.fit(X, Y) #導(dǎo)入數(shù)據(jù)集
res = clf.predict(np.array([12]).reshape(-1, 1))[0] #預(yù)測結(jié)果
print(u'預(yù)測一張12英寸匹薩價(jià)格:$%.2f' % res)
#預(yù)測結(jié)果
X2 = [[0], [10], [14], [25]]
Y2 = clf.predict(X2)
#繪制線性回歸圖形
plt.figure()
plt.title(u'diameter-cost curver') #標(biāo)題
plt.xlabel(u'diameter') #x軸坐標(biāo)
plt.ylabel(u'cost') #y軸坐標(biāo)
plt.axis([0, 25, 0, 25]) #區(qū)間
plt.grid(True) #顯示網(wǎng)格
plt.plot(X, Y, 'k.') #繪制訓(xùn)練數(shù)據(jù)集散點(diǎn)圖
plt.plot(X2, Y2, 'g-') #繪制預(yù)測數(shù)據(jù)集直線
plt.show()
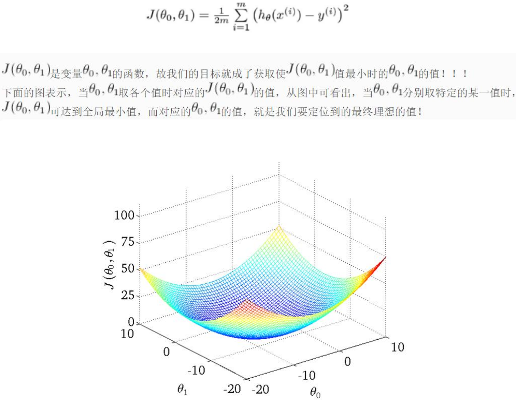
運(yùn)行結(jié)果如下所示��,首先輸出數(shù)據(jù)集��,同時(shí)調(diào)用sklearn包中的LinearRegression()回歸函數(shù)���,fit(X, Y)載入數(shù)據(jù)集進(jìn)行訓(xùn)練,然后通過predict()預(yù)測數(shù)據(jù)12尺寸的匹薩價(jià)格�����,最后定義X2數(shù)組�,預(yù)測它的價(jià)格���。
數(shù)據(jù)集X: [[6], [8], [10], [14], [18]]
數(shù)據(jù)集Y: [[7], [9], [13], [17.5], [18]]
預(yù)測一張12英寸匹薩價(jià)格:$13.68
輸出的圖形如下所示:
線性模型的回歸系數(shù)W會保存在他的coef_方法中��,截距保存在intercept_中�。score(X,y,sample_weight=None) 評分函數(shù)��,返回一個(gè)小于1的得分���,可能會小于0�����。
print u'系數(shù)', clf.coef_
print u'截距', clf.intercept_
print u'評分函數(shù)', clf.score(X, Y)
'''
系數(shù) [[ 0.9762931]]
截距 [ 1.96551743]
評分函數(shù) 0.910001596424
'''
其中具體的系數(shù)介紹推薦如下資料:sklearn學(xué)習(xí)筆記之簡單線性回歸 - Magle
四. 線性回歸判斷糖尿病
1.Diabetes數(shù)據(jù)集(糖尿病數(shù)據(jù)集)
糖尿病數(shù)據(jù)集包含442個(gè)患者的10個(gè)生理特征(年齡��,性別���、體重�、血壓)和一年以后疾病級數(shù)指標(biāo)�。
然后載入數(shù)據(jù),同時(shí)將diabetes糖尿病數(shù)據(jù)集分為測試數(shù)據(jù)和訓(xùn)練數(shù)據(jù)�,其中測試數(shù)據(jù)為最后20行,訓(xùn)練數(shù)據(jù)從0到-20行(不包含最后20行)��,即diabetes.data[:-20]����。
from sklearn import datasets
#數(shù)據(jù)集
diabetes = datasets.load_diabetes() #載入數(shù)據(jù)
diabetes_x = diabetes.data[:, np.newaxis] #獲取一個(gè)特征
diabetes_x_temp = diabetes_x[:, :, 2]
diabetes_x_train = diabetes_x_temp[:-20] #訓(xùn)練樣本
diabetes_x_test = diabetes_x_temp[-20:] #測試樣本 后20行
diabetes_y_train = diabetes.target[:-20] #訓(xùn)練標(biāo)記
diabetes_y_test = diabetes.target[-20:] #預(yù)測對比標(biāo)記
print u'劃分行數(shù):', len(diabetes_x_temp), len(diabetes_x_train), len(diabetes_x_test)
print diabetes_x_test
輸出結(jié)果如下所示,可以看到442個(gè)數(shù)據(jù)劃分為422行進(jìn)行訓(xùn)練回歸模型����,20行數(shù)據(jù)用于預(yù)測。輸出的diabetes_x_test共20行數(shù)據(jù),每行僅一個(gè)特征�。
劃分行數(shù): 442 422 20
[[ 0.07786339]
[-0.03961813]
[ 0.01103904]
[-0.04069594]
[-0.03422907]
[ 0.00564998]
[ 0.08864151]
[-0.03315126]
[-0.05686312]
[-0.03099563]
[ 0.05522933]
[-0.06009656]
[ 0.00133873]
[-0.02345095]
[-0.07410811]
[ 0.01966154]
[-0.01590626]
[-0.01590626]
[ 0.03906215]
[-0.0730303 ]]
2.完整代碼
改代碼的任務(wù)是從生理特征預(yù)測疾病級數(shù),但僅獲取了一維特征���,即一元線性回歸��?����!?a href="http://www.3lll3.cn/view/19879.html" target="_blank">線性回歸】的最簡單形式給數(shù)據(jù)集擬合一個(gè)線性模型����,主要是通過調(diào)整一系列的參以使得模型的殘差平方和盡量小���。
線性模型:y = βX+b
X:數(shù)據(jù) y:目標(biāo)變量 β:回歸系數(shù) b:觀測噪聲(bias��,偏差)
參考文章:Linear Regression Example - Scikit-Learn
# -*- coding: utf-8 -*-
"""
Created on Fri Oct 28 01:21:30 2016
@author: yxz15
"""
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
#數(shù)據(jù)集
diabetes = datasets.load_diabetes() #載入數(shù)據(jù)
#獲取一個(gè)特征
diabetes_x_temp = diabetes.data[:, np.newaxis, 2]
diabetes_x_train = diabetes_x_temp[:-20] #訓(xùn)練樣本
diabetes_x_test = diabetes_x_temp[-20:] #測試樣本 后20行
diabetes_y_train = diabetes.target[:-20] #訓(xùn)練標(biāo)記
diabetes_y_test = diabetes.target[-20:] #預(yù)測對比標(biāo)記
#回歸訓(xùn)練及預(yù)測
clf = linear_model.LinearRegression()
clf.fit(diabetes_x_train, diabetes_y_train) #注: 訓(xùn)練數(shù)據(jù)集
#系數(shù) 殘差平法和 方差得分
print 'Coefficients :\n', clf.coef_
print ("Residual sum of square: %.2f" %np.mean((clf.predict(diabetes_x_test) - diabetes_y_test) ** 2))
print ("variance score: %.2f" % clf.score(diabetes_x_test, diabetes_y_test))
#繪圖
plt.title(u'LinearRegression Diabetes') #標(biāo)題
plt.xlabel(u'Attributes') #x軸坐標(biāo)
plt.ylabel(u'Measure of disease') #y軸坐標(biāo)
#點(diǎn)的準(zhǔn)確位置
plt.scatter(diabetes_x_test, diabetes_y_test, color = 'black')
#預(yù)測結(jié)果 直線表示
plt.plot(diabetes_x_test, clf.predict(diabetes_x_test), color='blue', linewidth = 3)
plt.show()
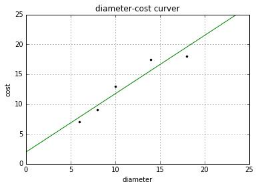
運(yùn)行結(jié)果如下所示���,包括系數(shù)、殘差平方和���、方差分?jǐn)?shù)。
Coefficients :[ 938.23786125]
Residual sum of square: 2548.07
variance score: 0.47
繪制圖形如下所示,每個(gè)點(diǎn)表示真實(shí)的值���,而直線表示預(yù)測的結(jié)果�����,比較接近吧��。
同時(shí)繪制圖形時(shí)��,想去掉坐標(biāo)具體的值�����,可增加如下代碼:
plt.xticks(())
plt.yticks(())
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330