(干貨)數(shù)據(jù)分析案例--以上海二手房為例
如果你手上有一批數(shù)據(jù)�,你可能應(yīng)用統(tǒng)計學(xué)、挖掘算法��、可視化方法等技術(shù)玩轉(zhuǎn)你的數(shù)據(jù)��,但你沒有數(shù)據(jù)的時候,我該怎么玩呢���?接下來就帶著大家玩玩沒有數(shù)據(jù)情況下的數(shù)據(jù)分析����。
本文從如下幾個目錄詳細(xì)講解數(shù)據(jù)分析的流程:
1���、數(shù)據(jù)源的獲?��。?br />
2�、數(shù)據(jù)探索與清洗;
3�����、模型構(gòu)建(聚類算法和線性回歸)���;
4��、模型預(yù)測����;
5���、模型評估�;
一�、數(shù)據(jù)源的獲取
正如本文的題目一樣,我要分析的是上海二手房數(shù)據(jù)�����,我想看看哪些因素會影響房價�?哪些房源可以歸為一類?我該如何預(yù)測二手房的價格��?可我手上沒有這樣的數(shù)據(jù)樣本�����,我該如何回答上面的問題呢����?
互聯(lián)網(wǎng)時代,網(wǎng)絡(luò)信息那么發(fā)達(dá)�,信息量那么龐大,隨便找點(diǎn)數(shù)據(jù)就夠喝一壺了��。前幾期我們已經(jīng)講過了如何從互聯(lián)網(wǎng)中抓取信息,采用Python這個靈活而便捷的工具完成爬蟲�,例如:
通過Python抓取天貓評論數(shù)據(jù)
使用Python實(shí)現(xiàn)豆瓣閱讀書籍信息的獲取
使用Python爬取網(wǎng)頁圖片
當(dāng)然,上海二手房的數(shù)據(jù)仍然是通過爬蟲獲取的���,爬取的平臺來自于鏈家���,頁面是這樣的:
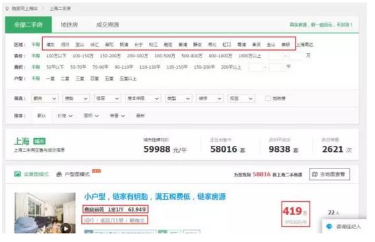
我所需要抓取下來的數(shù)據(jù)就是紅框中的內(nèi)容,即上海各個區(qū)域下每套二手房的 小區(qū)名稱�����、戶型�、面積、所屬區(qū)域���、樓層���、朝向、售價及單價 ���。先截幾張Python爬蟲的代碼�����,源代碼和數(shù)據(jù)分析代碼寫在文后的鏈接中���,如需下載可以到指定的百度云盤鏈接中下載。
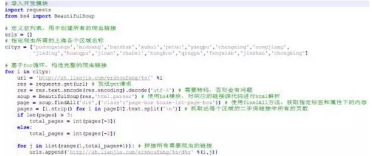
上面圖中的代碼是構(gòu)造所有需要爬蟲的鏈接��。
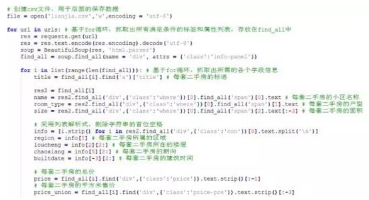
上面圖中的代碼是爬取指定字段的內(nèi)容��。
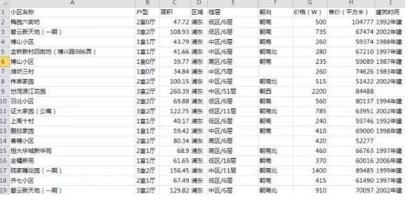
爬下來的數(shù)據(jù)是長這樣的(總共28000多套二手房):
二�、數(shù)據(jù)探索與清洗(一下均以R語言實(shí)現(xiàn))
當(dāng)數(shù)據(jù)抓下來后,按照慣例����,需要對數(shù)據(jù)做一個探索性分析,即了解我的數(shù)據(jù)都長成什么樣子�����。
1���、戶型分布
# 戶型分布
library(ggplot2)
type_freq <- data.frame(table(house$戶型))
# 繪圖
type_p <- ggplot(data = type_freq, mapping = aes(x = reorder(Var1, -Freq),y = Freq)) + geom_bar(stat = 'identity', fill = 'steelblue') + theme(axis.text.x = element_text(angle = 30, vjust = 0.5)) + xlab('戶型') + ylab('套數(shù)')
type_p
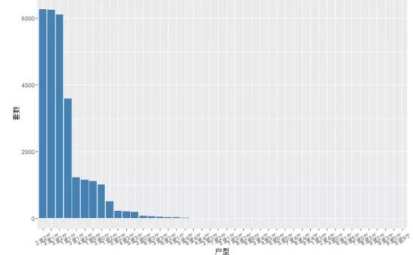
我們發(fā)現(xiàn)只有少數(shù)幾種的戶型數(shù)量比較多����,其余的都非常少��,明顯 屬于長尾分布類型(嚴(yán)重偏態(tài)) ,所以���,考慮將1000套一下的戶型統(tǒng)統(tǒng)歸為一類�����。
# 把低于一千套的房型設(shè)置為其他
type <- c('2室2廳','2室1廳','3室2廳','1室1廳','3室1廳','4室2廳','1室0廳','2室0廳')
house$type.new <- ifelse(house$戶型 %in% type, house$戶型,'其他')
type_freq <- data.frame(table(house$type.new))
# 繪圖
type_p <- ggplot(data = type_freq, mapping = aes(x = reorder(Var1, -Freq),y = Freq)) + geom_bar(stat = 'identity', fill = 'steelblue') + theme(axis.text.x = element_text(angle = 30, vjust = 0.5)) + xlab('戶型') + ylab('套數(shù)')
type_p
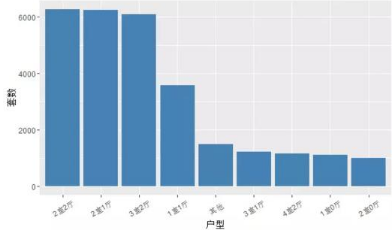
2��、二手房的面積和房價的分布
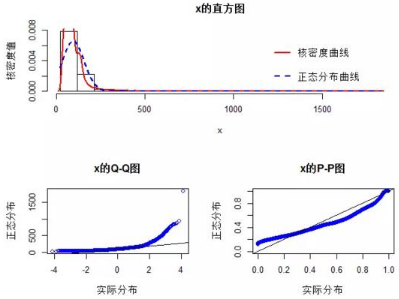
# 面積的正態(tài)性檢驗(yàn)
norm.test(house$面積)
# 房價的正態(tài)性檢驗(yàn)
norm.test(house$價格.W.)
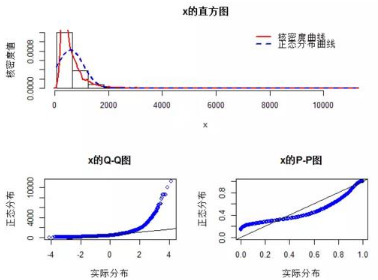
上面的norm.test函數(shù)是我自定義的函數(shù) ��,函數(shù)代碼也在下文的鏈接中���,可自行下載。從上圖可知�����, 二手房的面積和價格均不滿足正態(tài)分布��,那么就不能直接對這樣的數(shù)據(jù)進(jìn)行方差分析或構(gòu)建線性回歸模型 ����,因?yàn)檫@兩種統(tǒng)計方法,都要求正態(tài)性分布的前提假設(shè)���,后面我們會將講解如何處理這樣的問題�����。
3��、二手房的樓層分布
原始數(shù)據(jù)中關(guān)于樓層這一變量��,總共有151種水平����,如地上5層�、低區(qū)/6層、中區(qū)/11層�、高區(qū)/40層等,我們覺得有必要將這151種水平設(shè)置為低區(qū)�����、中區(qū)和高區(qū)三種水平����,這樣做有助于后面建模的需要。
# 把樓層分為低區(qū)�、中區(qū)和高區(qū)三種
house$floow <- ifelse(substring(house$樓層,1,2) %in% c('低區(qū)','中區(qū)','高區(qū)'), substring(house$樓層,1,2),'低區(qū)')
# 各樓層類型百分比分布
percent <- paste(round(prop.table(table(house$floow))*100,2),'%',sep = '')
df <- data.frame(table(house$floow))
df <- cbind(df, percent)
df
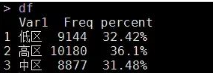
可見����,三種樓層的分布大體相當(dāng)�,最多的為高區(qū),占了36.1%���。
4��、上海各地區(qū)二手房的均價
# 上海各區(qū)房價均價
avg_price <- aggregate(house$單價.平方米., by = list(house$區(qū)域), mean)
#繪圖
p <- ggplot(data = avg_price, mapping = aes(x = reorder(Group.1, -x), y = x, group = 1)) + geom_area(fill = 'lightgreen') + geom_line(colour = 'steelblue', size = 2) + geom_point() + xlab('') + ylab('均價')
p
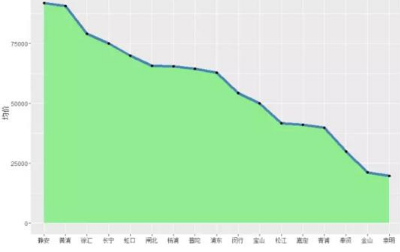
很明顯���,上海二手房價格最高的三個地區(qū)為:靜安、黃埔和徐匯�����,均價都在7.5W以上����,價格最低的三個地區(qū)為:崇明、金山和奉賢����。
5、房屋建筑時間缺失嚴(yán)重
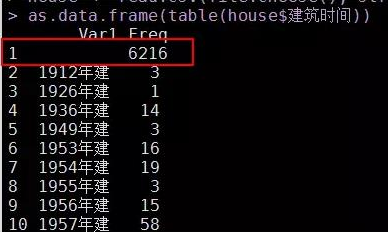
建筑時間這個變量有6216個 缺失,占了總樣本的22% �。雖然缺失嚴(yán)重,但我也不能簡單粗暴的把該變量扔掉����, 所以考慮到按各個區(qū)域分組,實(shí)現(xiàn)眾數(shù)替補(bǔ)法 �����。這里構(gòu)建了兩個自定義函數(shù):
library(Hmisc)
# 自定義眾數(shù)函數(shù)
stat.mode <- function(x, rm.na = TRUE){
if (rm.na == TRUE){
y = x[!is.na(x)]
}
res = names(table(y))[which.max(table(y))]
return(res)
}
# 自定義函數(shù)�����,實(shí)現(xiàn)分組替補(bǔ)
my.impute <- function(data, category.col = NULL,
miss.col = NULL, method = stat.mode){
impute.data = NULL
for(i in as.character(unique(data[,category.col]))){
sub.data = subset(data, data[,category.col] == i)
sub.data[,miss.col] = impute(sub.data[,miss.col], method)
impute.data = c(impute.data, sub.data[,miss.col])
}
data[,miss.col] = impute.data
return(data)
}
# 將建筑時間中空白字符串轉(zhuǎn)換為缺失值
house$建筑時間[house$建筑時間 == ''] <- NA
#分組替補(bǔ)缺失值��,并對數(shù)據(jù)集進(jìn)行變量篩選
final_house <- subset(my.impute(house, '區(qū)域', '建筑時間'),select = c(type.new,floow,面積,價格.W.,單價.平方米.,建筑時間))
#構(gòu)建新字段�,即建筑時間與當(dāng)前2016年的時長
final_house <- transform(final_house, builtdate2now = 2016-as.integer(substring(as.character(建筑時間),1,4)))
#刪除原始的建筑時間這一字段
final_house <- subset(final_house, select = -建筑時間)
最終完成的干凈數(shù)據(jù)集如下:
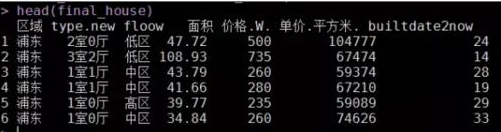
接下來就可以針對這樣的干凈數(shù)據(jù)集�,作進(jìn)一步的分析,如聚類���、線性回歸等���。
三、模型構(gòu)建
這么多的房子,我該如何把它們分分類呢�����?即應(yīng)該把哪些房源歸為一類����?這就要用到聚類算法了, 我們就使用簡單而快捷的k-means算法實(shí)現(xiàn)聚類的工作 �。但聚類前,我需要掂量一下我該聚為幾類�����?根據(jù) 聚類原則:組內(nèi)差距要小��,組間差距要大 �����。我們繪制不同類簇下的組內(nèi)離差平方和圖����,聚類過程中,我們選擇面積�、房價和單價三個數(shù)值型變量:
tot.wssplot <- function(data, nc, seed=1234){
#假設(shè)分為一組時的總的離差平方和
tot.wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:nc){
#必須指定隨機(jī)種子數(shù)
set.seed(seed)
tot.wss[i] <- kmeans(data, centers=i, iter.max = 100)$tot.withinss
}
plot(1:nc, tot.wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares",col = 'blue',
lwd = 2, main = 'Choose best Clusters')
}
# 繪制不同聚類數(shù)目下的組內(nèi)離差平方和
standrad <- data.frame(scale(final_house[,c('面積','價格.W.','單價.平方米.')]))
myplot <- tot.wssplot(standrad, nc = 15)
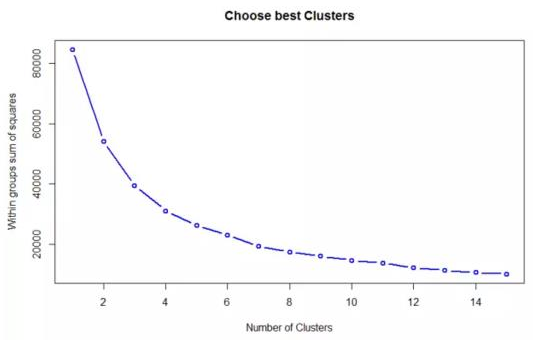
當(dāng)把所有樣本當(dāng)作一類時��,離差平方和達(dá)到最大����,隨著聚類數(shù)量的增加���,組內(nèi)離差平方和會逐漸降低�,直到極端情況�����,每一個樣本作為一類����,此時組內(nèi)離差平方和為0�����。從上圖看�����,聚類數(shù)量在5次以上���,組內(nèi)離差平方降低非常緩慢���,可以把拐點(diǎn)當(dāng)作5���,即聚為5類。
# 將樣本數(shù)據(jù)聚為5類
set.seed(1234)
clust <- kmeans(x = standrad, centers = 5, iter.max = 100)
table(clust$cluster)
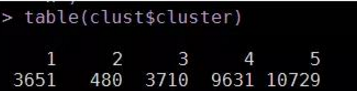
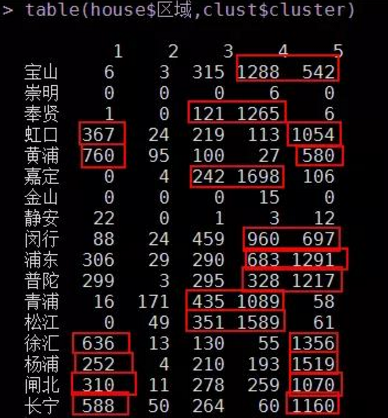
# 按照聚類的結(jié)果�����,查看各類中的區(qū)域分布
table(final_house$區(qū)域,clust$cluster)
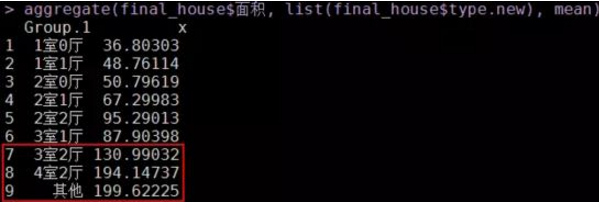
# 各戶型的平均面積
aggregate(final_house$面積, list(final_house$type.new), mean)
# 按聚類結(jié)果�,比較各類中房子的平均面積、平均價格和平均單價
aggregate(final_house[,3:5], list(clust$cluster), mean)
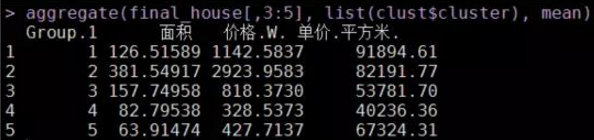
從平均水平來看�����,我大體可以將28000多套房源合成為如下幾種說法:
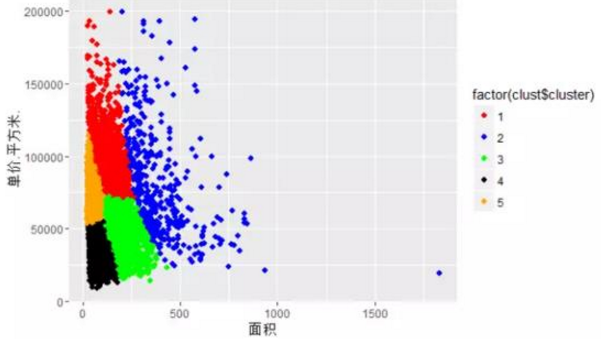
a�����、大戶型(3室2廳���、4室2廳)����,屬于第2類。 平均面積都在130平以上��,這種大戶型的房源主要分布在青浦�����、黃埔�����、松江等地(具體可從 各類中的區(qū)域分布圖可知 )����。
b、地段型(房價高)��,屬于第1類�����。 典型的區(qū)域有黃埔�����、徐匯��、長寧�、浦東等地(具體可從 各類中的區(qū)域分布圖可知 )。
c���、大眾蝸居型(面積小�����、價格適中���、房源多),屬于第4和5類�����。 典型的區(qū)域有寶山���、虹口��、閔行�����、浦東����、普陀、楊浦等地
d�����、徘徊型(大戶型與地段型之間的房源)�����,屬于第3類����。 典型的區(qū)域有奉賢、嘉定�、青浦、松江等地���。這些地區(qū)也是將來迅速崛起的地方�����。
# 繪制面積與單價的散點(diǎn)圖����,并按聚類進(jìn)行劃分
p <- ggplot(data = final_house[,3:5], mapping = aes(x = 面積,y = 單價.平方米., color = factor(clust$cluster)))
p <- p + geom_point(pch = 20, size = 3)
p + scale_colour_manual(values = c("red","blue", "green", "black", "orange"))
接下來我想 借助于已有的數(shù)據(jù)(房價�、面積、單價���、樓層���、戶型、建筑時長��、聚類水平)構(gòu)建線性回歸方程 �,用于房價因素的判斷及預(yù)測。由于數(shù)據(jù)中有離散變量���,如戶型��、樓層等��,這些變量入模的話需要對其 進(jìn)行啞變量處理 �����。
# 構(gòu)造樓層和聚類結(jié)果的啞變量
# 將幾個離散變量轉(zhuǎn)換為因子��,目的便于下面一次性處理啞變量
final_house$cluster <- factor(clust$cluster)
final_house$floow <- factor(final_house$floow)
final_house$type.new <- factor(final_house$type.new)
# 篩選出所有因子型變量
factors <- names(final_house)[sapply(final_house, class) == 'factor']
# 將因子型變量轉(zhuǎn)換成公式formula的右半邊形式
formula <- f <- as.formula(paste('~', paste(factors, collapse = '+')))
dummy <- dummyVars(formula = formula, data = final_house)
pred <- predict(dummy, newdata = final_house)
head(pred)
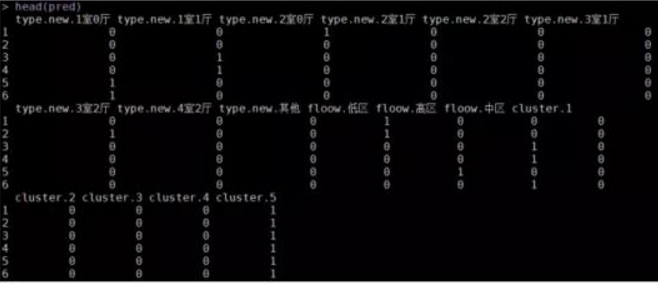
# 將啞變量規(guī)整到final_house數(shù)據(jù)集中
final_house2 <- cbind(final_house,pred)
# 篩選出需要建模的數(shù)據(jù)
model.data <- subset(final_house2,select = -c(1,2,3,8,17,18,24))
# 直接對數(shù)據(jù)進(jìn)行線性回歸建模
fit1 <- lm(價格.W. ~ .,data = model.data)
summary(fit1)
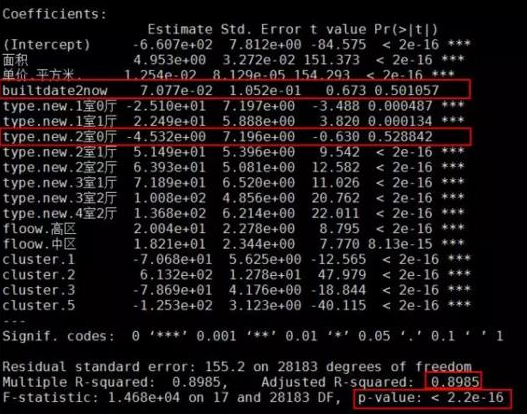
從體看上去還行���,只有建筑時長和2室0廳的房型參數(shù)不顯著�,其他均在0.01置信水平下顯著�。 不要贊贊自喜 ,我們說���,使用線性回歸是有假設(shè)前提的����,即因變量滿足正態(tài)或近似于正態(tài)分布����,前面說過,房價明顯在樣本中是偏態(tài)的���,并不服從正態(tài)分布���,所以這里 使用COX-BOX變換處理 。根據(jù)COX-BOX變換的lambda結(jié)果����,我們針對y變量進(jìn)行轉(zhuǎn)換,即:
# Cox-Box轉(zhuǎn)換
library(car)
powerTransform(fit1)
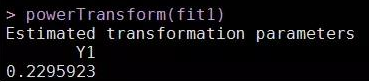
根據(jù)結(jié)果顯示, 0.23非常接近上表中的0值�����,故考慮將二手房的價格進(jìn)行對數(shù)變換���。
fit2 <- lm(log(價格.W.) ~ .,data = model.data)
summary(fit2)
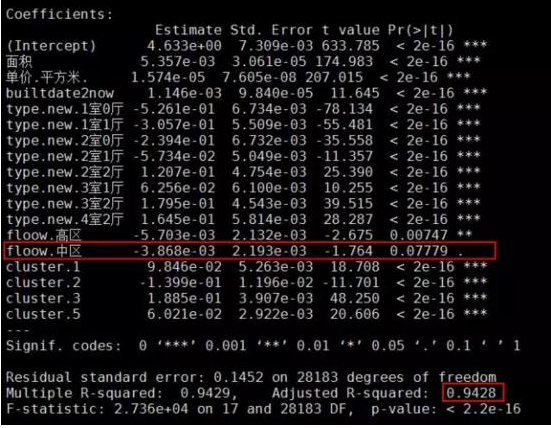
這次的結(jié)果就明顯比fit1好很多 ,僅有樓層的中區(qū)在0.1置信水平下顯著���,其余變量均在0.01置信水平下顯著����, 而且調(diào)整的R方值也提高到了94.3% ���,即這些自變量對房價的解釋度達(dá)到了94.3%����。
最后我們再看一下�,關(guān)于最終模型的診斷結(jié)果:
# 使用plot方法完成模型定性的診斷
opar <- par(no.readonly = TRUE)
par(mfrow = c(2,2))
plot(fit2)
par(opar)
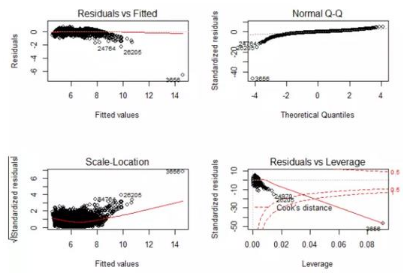
從上圖看,基本上滿足了線性回歸模型的幾個假設(shè)����,即:殘差項服從均值為0(左上),標(biāo)準(zhǔn)差為常數(shù)(左下)的正態(tài)分布分布(右上)?����;谶@樣的模型�����,我們就可以有針對性的預(yù)測房價啦~
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330