在講完原理之后���,現(xiàn)在開始嘗試寫代碼
因為里面涉及太多的選取數(shù)據(jù)工作。為了避免出現(xiàn)太多變量���,我最后是編了一個函數(shù)�����,輸出數(shù)據(jù)庫
函數(shù)部分
#下面開始寫代碼,首先寫一個函數(shù)getdata���,會輸出一個數(shù)據(jù)框
getdata<-function(page,urlwithoutpage){
url=paste0(urlwithoutpage,page) #這里輸入拉勾網(wǎng)沒有頁碼的url
web<-html(url,encoding="UTF-8") #讀取數(shù)據(jù),規(guī)定編碼,access用
list_lagou<-web %>% html_nodes("li.clearfix") #獲得一個清單���,15個職位
title<-list_lagou %>% html_nodes("div.hot_pos_l div.mb10 a")%>%html_text()
company<-list_lagou %>% html_nodes("div.hot_pos_r div.mb10 a")%>%html_text()
link<-gsub("\\?source\\=search","",list_lagou %>% html_nodes("div.hot_pos_l div.mb10 a")%>%html_attr("href"))
#接下來的由于數(shù)據(jù)都存在span里����,沒有很好的劃分�。這個取數(shù)要復(fù)雜一些。我在這里�����,研究他們的表,先取15個完整list�,然后用seq等序列取數(shù)
#之后要研究是否有更好的方法
#如果有table,可以直接用data.table取數(shù)更快����。。���。
temp<-list_lagou %>% html_nodes("div.hot_pos_l span")
city<-temp[seq(1,90,by=6)] %>% html_text()
salary<-gsub("月薪:","",temp[seq(2,90,by=6)]%>% html_text())
year<-gsub("經(jīng)驗:","",temp[seq(3,90,by=6)]%>% html_text())
degree<-gsub("最低學(xué)歷:","",temp[seq(4,90,by=6)]%>%html_text())
benefit<-gsub("職位誘惑:","",temp[seq(5,90,by=6)]%>% html_text())
time<-temp[seq(6,90,by=6)]%>%html_text()
data.frame(title,company,city,salary,year,degree,benefit,time,link)
}
然后是使用該函數(shù)��,我這里就爬兩頁
#使用該函數(shù)��,
library(rvest)
url<-"http://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90&spc=2&pl=&gj=&xl=&yx=&gx=&st=&labelWords=&lc=&workAddress=&city=%E6%B7%B1%E5%9C%B3&requestId=&pn="
final<-data.frame()
for (i in 3:5){
final<-rbind(final,getdata(i,url))
} #定義個數(shù)����,把上面的getdata得到的Data.frame合并
head(final)
上面完成了第一個列表���。爬出效果如圖
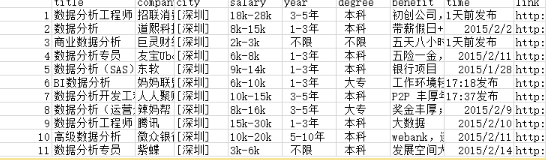
關(guān)于這個數(shù)據(jù)有什么用呢…… 簡單來說����,我們可以用它來看這個網(wǎng)上有多少在招的,各公司招人的比例��,以及薪資水平���,做一點基礎(chǔ)的數(shù)據(jù)分析�����。
雖然我現(xiàn)在不跳槽,不過了解一下市場狀況也是不錯的~譬如見下圖���,從目前這網(wǎng)上的平均薪資與工作年限的關(guān)系來看���,數(shù)據(jù)分析崗至少在職位前五年屬于薪資增長期,初始漲得快����,后面漲得慢,但平均應(yīng)有13%左右的增長����?然后這網(wǎng)上目前沒有什么高級崗位開出來(工作5-10年的崗位很少),反而是有些公司搞錯分類�,放了一堆數(shù)據(jù)錄入的到數(shù)據(jù)分析欄目。。����。
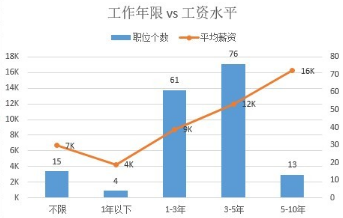
值得一提的是,因為數(shù)據(jù)分析這個類目里包含了不同的類別���,如數(shù)據(jù)錄入的也被歸到數(shù)據(jù)分析����,還有高薪也被歸到這里��,所以不能完全按這個做參考���。不過這個研究讓我深刻體會到了爬蟲的有效性����!好玩�����!實用�����!可以用到工作中去:) 還可以像個獵頭一樣了解人才市場~~做個有情調(diào)的數(shù)據(jù)分析師~~
另外,其實我們還可以遍歷JD�����,看近期是什么技術(shù)最吃香���,是R還是Python還是SQL還是SAS還是別的啥啥啥�����。下面是我隨機(jī)抽了個JD做的爬蟲����?��?梢灾苯幽玫较嚓P(guān)數(shù)據(jù)。
final[1,9]
## [1] http://www.lagou.com/jobs/378361.html
## 45 Levels: http://www.lagou.com/jobs/113293.html ...
url<-as.character(final[1,9])
w<-html(url,encoding = "UTF-8")
d<-w %>% html_nodes("dd.job_bt p") %>% html_text()
d
## [1] "1.金融�����、計算機(jī)�、財務(wù)、經(jīng)濟(jì)相關(guān)專業(yè)���;"
## [2] "2.有證券從業(yè)資格證者優(yōu)先�;"
## [3] "3.想從事文職類工作,對辦公軟件熟悉����;"
## [4] "4.可接收已拿到學(xué)歷證的應(yīng)屆畢業(yè)生。"
## [5] "<U+00A0>"
注意事項:
對于被編碼保護(hù)的數(shù)據(jù)(如國外yellow.local.ch�����,email被編碼保護(hù)了����。需要用 decodeURIComponent函數(shù)反編譯。)
xpath語句對html_nodes適用�����。但是它好像是全局語句����。。就是如果用div[1]//span[4]取數(shù)的話�����,它直接就只出全局的那個結(jié)果。����。。
如
取數(shù)��,可以用li.da或者li.daew取數(shù)�,兩者等價
正則表達(dá)式很有用!�����!尤其是對網(wǎng)頁數(shù)據(jù)����,某些不會寫,或者技術(shù)高超不愿意被我們爬蟲的工程師���,用rvest去抓數(shù)據(jù),會抓到一堆堆亂碼= =這幾天練習(xí)下來感受到了無盡惡意
中文�����,html(data,encoding='UTF-8')還有iconv(data,'utf-8','gbk')可以有效避免大部分亂碼����。但是R對中文支持真的很渣�。
rvest對于靜態(tài)抓取很方便��!但是對于腳本訪問的網(wǎng)頁��,還需要繼續(xù)學(xué)習(xí)RCurl包�。備查資料如下:
javascript數(shù)據(jù)提取-RCurl包-戴申: 介紹對腳本解析后抓取數(shù)據(jù)經(jīng)驗
RCurl提取統(tǒng)計之都論壇數(shù)據(jù)演示-medo
等學(xué)會了再寫總結(jié)。











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330