用Python進(jìn)行梯度提升算法的參數(shù)調(diào)整
提升算法(Boosting)在處理偏差-方差權(quán)衡的問題上表現(xiàn)優(yōu)越����,和裝袋算法(Bagging)僅僅注重控制方差不同�,提升算法在控制偏差和方差的問題上往往更加有效��。在這里����,我們提供一個對梯度提升算法的透徹理解,希望他能讓你在處理這一問題上更加胸有成竹����。
這篇文章我們將會用Python語言實(shí)踐梯度提升算法,并通過調(diào)整參數(shù)來獲得更加可信的結(jié)果��。
提升算法的機(jī)制
提升算法是一個序列型的集成學(xué)習(xí)方法,它通過把一系列弱學(xué)習(xí)器集成為強(qiáng)學(xué)習(xí)器來提升它的預(yù)測精度���,對于第t次要訓(xùn)練的弱學(xué)習(xí)器����,它會更加重視之前第t-1次預(yù)測錯誤的樣本�����,相反給預(yù)測正確的樣本更低的權(quán)重�����,我們用圖來描述一下:
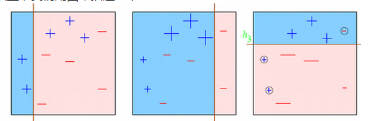
圖一:生成的第一個弱分類器
所有的樣本擁有相同的權(quán)重(用大小表示)�。
決策邊界成功預(yù)測了2個+樣本和5個-樣本。
圖二:生成的第二個弱分類器
在圖一中被正確分類的樣本給予了一個更小的權(quán)重���,而錯分類樣本權(quán)重更大����。
這個分類器更加重視那些權(quán)重大的樣本并把它們正確分類��,但是會造成其他樣本的錯分類�。
圖三也是一樣的�,這個過程會循環(huán)多次直到最后��,然后把所有的弱學(xué)習(xí)器基于他們的準(zhǔn)確性賦予權(quán)重��,并最終集成為強(qiáng)學(xué)習(xí)器���。
梯度提升算法的參數(shù)
梯度提升算法的參數(shù)可以被分為三類:
決策樹參數(shù):單獨(dú)影響每個弱學(xué)習(xí)器(決策樹)的參數(shù)
提升算法參數(shù):影響提升算法運(yùn)行的參數(shù)
其他參數(shù):整個模型中的其他參數(shù)
決策樹參數(shù)
下面是對決策樹參數(shù)的詳細(xì)介紹��,在這里我們用的是Python的scikit-learn包�,或許和R語言的一些包不同���,但是他們蘊(yùn)含的思想是一致的����。
分支最小樣本量:一個節(jié)點(diǎn)想要繼續(xù)分支所需要的最小樣本數(shù)����。
葉節(jié)點(diǎn)最小樣本量:一個節(jié)點(diǎn)要劃為葉節(jié)點(diǎn)所需最小樣本數(shù)���,與上一個參數(shù)相對應(yīng)����。
最小葉節(jié)點(diǎn)相對權(quán)重:和上一個參數(shù)類似,只不過按照權(quán)重的定義轉(zhuǎn)變?yōu)榉謹(jǐn)?shù)的形式��。
樹最大深度:樹的層次��,樹越深越有過擬合的風(fēng)險(xiǎn)��。
最大葉節(jié)點(diǎn)量:葉節(jié)點(diǎn)的最大數(shù)目�,和樹最大深度可以相互替代。
最大特征子集量:選擇最優(yōu)特征進(jìn)行分支的時候����,特征子集的最大數(shù)目,可以根據(jù)這個數(shù)目在特征全集中隨機(jī)抽樣�����。
在定義下面兩類參數(shù)之前�,我們先來看一下一個二分類問題的梯度提升算法框架:
生成初始模型
從1開始循環(huán)迭代
2.1根據(jù)上一個運(yùn)行的結(jié)果更新權(quán)重
2.2 用調(diào)整過的樣本子集重新擬合模型
2.3 對樣本全集做預(yù)測
2.4 結(jié)合預(yù)測和學(xué)習(xí)率來更新輸出結(jié)果
生成最終結(jié)果
這是一個非常樸素的梯度提升算法框架,我們剛才討論的哪些參數(shù)僅僅是影響2.2這一環(huán)節(jié)里的弱學(xué)習(xí)器模型擬合���。
提升算法參數(shù)
學(xué)習(xí)率:這個參數(shù)是2.4中針對預(yù)測的結(jié)果計(jì)算的學(xué)習(xí)率�。梯度提升算法就是通過對初始模型進(jìn)行一次次的調(diào)整來實(shí)現(xiàn)的���,學(xué)習(xí)率就是衡量每次調(diào)整幅度的一個參數(shù)���。這個參數(shù)值越小��,迭代出的結(jié)果往往越好�����,但所需要的迭代次數(shù)越多�,計(jì)算成本也越大�。
弱學(xué)習(xí)器數(shù)量:就是生成的所有的弱學(xué)習(xí)器的數(shù)目,也就是第2步當(dāng)中的迭代次數(shù)��,當(dāng)然不是越多越好�����,因?yàn)樘嵘惴ㄒ矔?a href='/map/guonihe/' style='color:#000;font-size:inherit;'>過擬合的風(fēng)險(xiǎn)����。
樣本子集所占比重:用來訓(xùn)練弱學(xué)習(xí)器的樣本子集占樣本總體的比重��,一般都是隨機(jī)抽樣以降低方差�����,默認(rèn)是選擇總體80%的樣本來訓(xùn)練。
其他參數(shù)
諸如損失函數(shù)(loss)�����、隨機(jī)數(shù)種子(random_state)等參數(shù)�����,不在本文調(diào)整的參數(shù)范圍內(nèi)����,大多是采用默認(rèn)狀態(tài)。
模型擬合與參數(shù)調(diào)整
我們用的是從Data Hackathon 3.x AV hackathon下載的數(shù)據(jù)����,在預(yù)處理以后,我們在Python中載入要用的包并導(dǎo)入數(shù)據(jù)����。
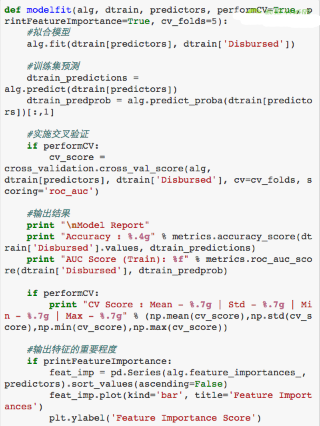
我們先定義一個函數(shù)來幫助我們創(chuàng)建梯度提升算法模型并實(shí)施交叉驗(yàn)證。
我們首先創(chuàng)建一個基準(zhǔn)模型�����,在這里我們選擇AUC作為預(yù)測標(biāo)準(zhǔn),如果你有幸擬合了一個好的基準(zhǔn)模型��,那你就不用進(jìn)行參數(shù)調(diào)整了���。下圖是擬合的結(jié)果:
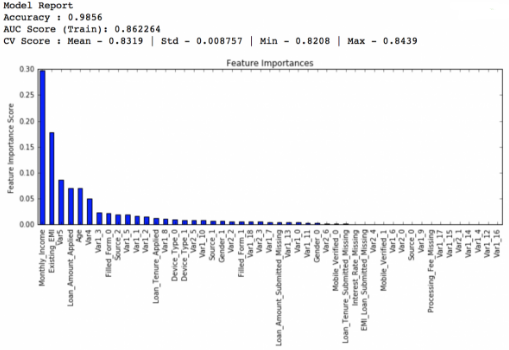
所以平均下來的交叉驗(yàn)證得分是0.8319�����,我們要讓模型表現(xiàn)得更好一點(diǎn)�。
參數(shù)調(diào)整的典型方法
事實(shí)上�,我們很難找到一個最佳的學(xué)習(xí)率參數(shù),因?yàn)橥∫稽c(diǎn)的學(xué)習(xí)率會訓(xùn)練更多的弱學(xué)習(xí)器從而使得集成起來的學(xué)習(xí)器表現(xiàn)優(yōu)越�,但是這樣也會導(dǎo)致過度擬合的問題,而且對于個人用的電腦來說���,計(jì)算成本太大�����。
下面的參數(shù)調(diào)整的思路要能夠謹(jǐn)記于心:
先選擇一個相對較高的學(xué)習(xí)率��,通常就是默認(rèn)值0.1但是一般0.05到0.2范圍內(nèi)的數(shù)值都是可以嘗試使用的��。
在學(xué)習(xí)率確定的情況下�����,進(jìn)一步確定要訓(xùn)練的弱學(xué)習(xí)器數(shù)量��,應(yīng)該在40到70棵決策樹之間�����,當(dāng)然選擇的時候還要根據(jù)電腦的性能量力而行�����。
決定好學(xué)習(xí)率和弱學(xué)習(xí)器數(shù)目后��,調(diào)整決策樹參數(shù)����,我們可以選擇不同的參數(shù)來定義每一棵決策樹的形式��,下面也會有范例���。
如果這樣訓(xùn)練的模型精度不夠理想�,降低當(dāng)前的學(xué)習(xí)率���、訓(xùn)練更多的弱學(xué)習(xí)器����。
調(diào)整弱學(xué)習(xí)器數(shù)量
首先先看一下Python默認(rèn)的一些參數(shù)值:分支最小樣本量=500;葉節(jié)點(diǎn)最小樣本量=50��;樹最大深度=8���; 樣本子集所占比重=0.8�;最大特征子集量=特征總數(shù)平方根���。這些默認(rèn)參數(shù)值我們要在接下來的步驟中調(diào)整��。我們現(xiàn)在要做的是基于以上這些默認(rèn)值和默認(rèn)的0.1學(xué)習(xí)率來決定弱學(xué)習(xí)器數(shù)量�����,我們用網(wǎng)格搜索(grid search)的方法���,以10為步長,在20到80之間測試弱學(xué)習(xí)器的最優(yōu)數(shù)量�。
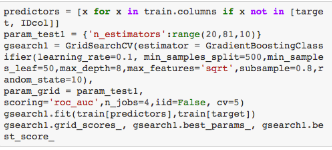
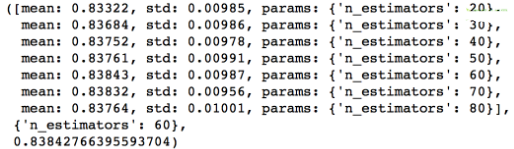
輸出結(jié)果顯示,我們確定60個弱學(xué)習(xí)器時得分最高�����,這個結(jié)果恰巧比較合理。但是情況往往不都是如此:如果最終結(jié)果顯示大概在20左右�����,那么我們應(yīng)該降低學(xué)習(xí)率到0.05����;如果顯示超過80(在80的時候得分最高)���,那么我們應(yīng)該調(diào)高學(xué)習(xí)率�����。最后再調(diào)整弱學(xué)習(xí)器數(shù)量�,直到進(jìn)入合理區(qū)間����。
調(diào)整決策樹參數(shù)
確定好弱學(xué)習(xí)器數(shù)量之后,現(xiàn)實(shí)情況下常用的調(diào)參思路為:
調(diào)整樹最大深度和分支最小樣本量���。
調(diào)整葉節(jié)點(diǎn)最小樣本量����。
調(diào)整最大特征子集量。
當(dāng)然上述調(diào)參順序是慎重決定的��,應(yīng)該先調(diào)整那些有更大影響的參數(shù)���。注意:接下來的網(wǎng)格搜索可能每次會花費(fèi)15~30分鐘甚至更長的時間�����,在實(shí)戰(zhàn)中�,你可以根據(jù)你的計(jì)算機(jī)情況合理選擇步長和范圍�。
首先我們以2為步長在5到15之間選擇樹最大深度,以200為步長在200到1000內(nèi)選擇分支最小樣本量�,這些都是基于我本人的經(jīng)驗(yàn)和直覺,現(xiàn)實(shí)中你也可以選擇更大的范圍更小的步長�����。
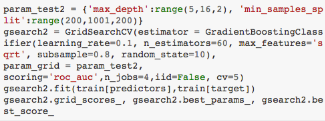
從運(yùn)行結(jié)果來看���,選擇深度為9���、分支最小樣本量為1000時得分最高�,而1000是我們所選范圍的上界�����,所以真實(shí)的最優(yōu)值可能在1000以上�,理論上應(yīng)該擴(kuò)大范圍繼續(xù)尋找最優(yōu)值。我們以200為步長在大于1000的范圍內(nèi)確定分支最小樣本量�,在30到70的范圍內(nèi)以10為步長確定葉節(jié)點(diǎn)最小樣本量�。
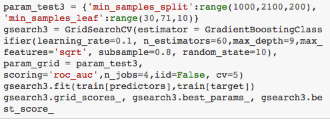
最終我們得到了分支最小樣本量為1200,葉節(jié)點(diǎn)最小樣本量為60�。這個時候我們階段性回顧一下,看之前的調(diào)參效果��。
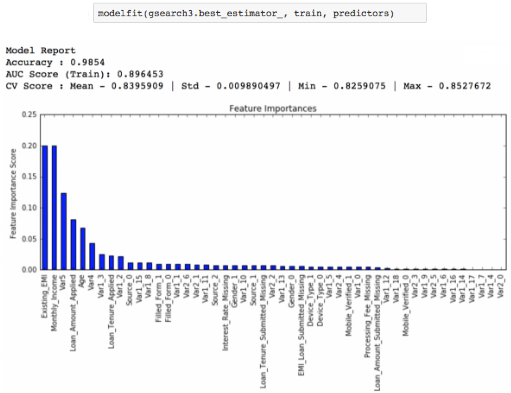
如果你對比了基準(zhǔn)模型和新模型的特征重要程度��,你會發(fā)現(xiàn)我們已經(jīng)能夠從更多的特征中獲其價(jià)值��,現(xiàn)在的模型已經(jīng)學(xué)會把凝視在前幾個特征的目光分散到后面的特征�����。
現(xiàn)在我們再來調(diào)整最后的決策樹參數(shù)—最大特征量�����。調(diào)整方式為以2為步長從7到19。
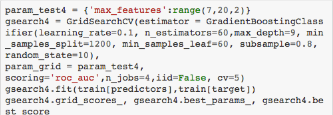
最終結(jié)果顯示最優(yōu)值是7�����,這也是算法默認(rèn)的平方根�����,所以這一參數(shù)的默認(rèn)值就是最好的����。當(dāng)然,你也可以選擇更小的值來測��,畢竟7同時是我們所選的范圍下界�,但我選擇安于現(xiàn)狀。接下來我們調(diào)整子集所占比重�,候選值為0.6、0.7����、0.75、0.8����、0.85���、0.9。

從結(jié)果來看�����,0.85是最優(yōu)值��。這樣我們就獲得了所有的調(diào)整后的決策樹參數(shù)���。最后看一下我們的調(diào)參結(jié)果:
分支最小樣本量:1200
葉節(jié)點(diǎn)最小樣本量:60
樹最大深度:9
最大特征子集量:7
樣本子集所占比重:85%
調(diào)整學(xué)習(xí)率
現(xiàn)在我們的任務(wù)是重新降低學(xué)習(xí)率���,尋找一個低于默認(rèn)值0.1的學(xué)習(xí)率并成比例地增加弱學(xué)習(xí)器的數(shù)量�,當(dāng)然這個時候弱學(xué)習(xí)器的數(shù)目已經(jīng)不再是一開始調(diào)整后那個最優(yōu)值了,但是新的參數(shù)值會是一個很好的基準(zhǔn)���。
當(dāng)樹增多的時候���,交叉驗(yàn)證尋找最優(yōu)值的計(jì)算成本會更大。為了讓你對模型表現(xiàn)有個直觀的把握���,我計(jì)算了接下來每次調(diào)試后模型的private leaderboard得分���,這個數(shù)據(jù)是不開源的���,所以你沒有辦法復(fù)制,但是它對你理解有幫助�。
首先我們降低學(xué)習(xí)率到0.05,弱學(xué)習(xí)器數(shù)量增加到120個:
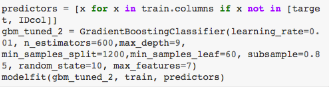
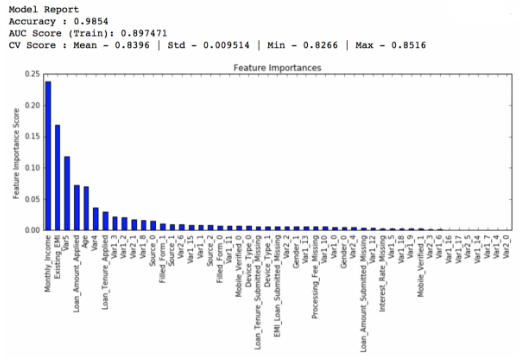
private leaderboard得分:0.844139
學(xué)習(xí)率降低到0.01��,弱學(xué)習(xí)器數(shù)量增加到600個:
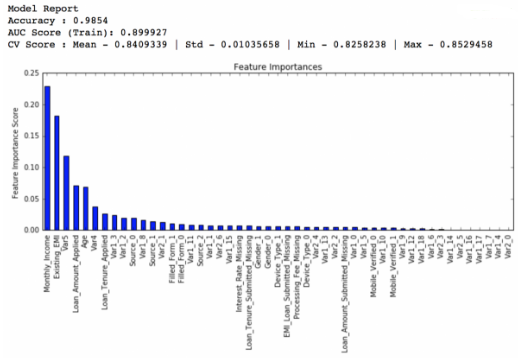
private leaderboard得分:0.848145
學(xué)習(xí)率降低到0.005����,弱學(xué)習(xí)器數(shù)量增加到1200個:
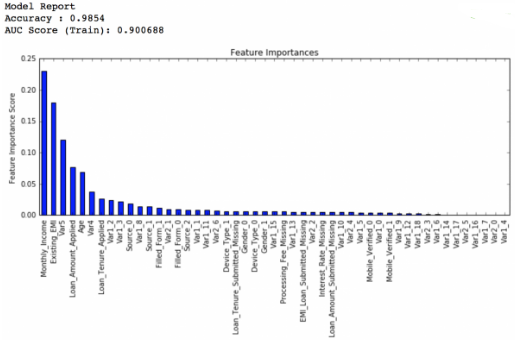
private leaderboard得分:0.848112
可以看到得分降低了一點(diǎn)點(diǎn),我們再做一次調(diào)整���,只把弱學(xué)習(xí)器數(shù)量增加到1500個:
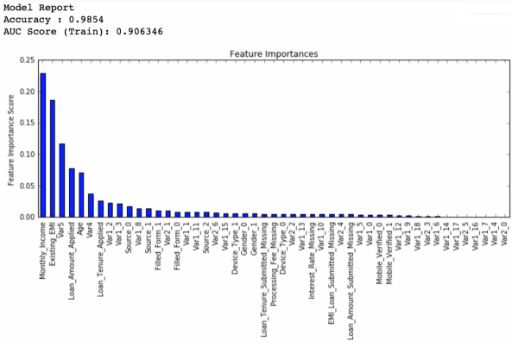
private leaderboard得分:0.848747
到此為止����,我們可以看到得分由0.844到0.849����,可以視為是比較顯著的變化。所以最終我們確定的學(xué)習(xí)率為0.005�����,弱學(xué)習(xí)器數(shù)量為1500,當(dāng)然這個計(jì)算成本是很高的��。
結(jié)語
本文基于優(yōu)化梯度提升算法模型���,分為三個部分:首先介紹了提升算法的思想�����,接下來討論了梯度提升算法的參數(shù)分類���,最后是模型擬合和參數(shù)調(diào)整,并結(jié)合Python予以示例�。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材�,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330