決策樹(專家藥物模型)操作案例
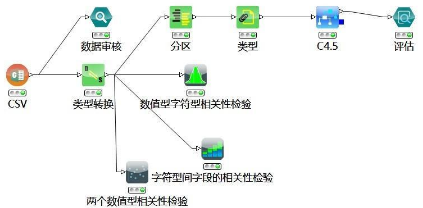
依據(jù)常用案例專家藥物模型使用SmartMining桌面版����,以決策樹算法為背景��,說明大數(shù)據(jù)如何構(gòu)建專家診病模型,以及如何通過可視化探索數(shù)據(jù)��,實現(xiàn)決策樹同樣的計算結(jié)果!案例側(cè)重于大數(shù)據(jù)思維的形成和可視化探索在數(shù)據(jù)挖掘中重要作用有所體驗����。專家預(yù)測模型工作流如下:
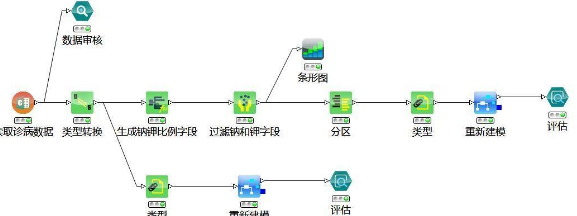
1)商業(yè)目標(biāo)
業(yè)務(wù)理解:
該案例所用的數(shù)據(jù)是一份模擬醫(yī)生診病的數(shù)據(jù),如下:
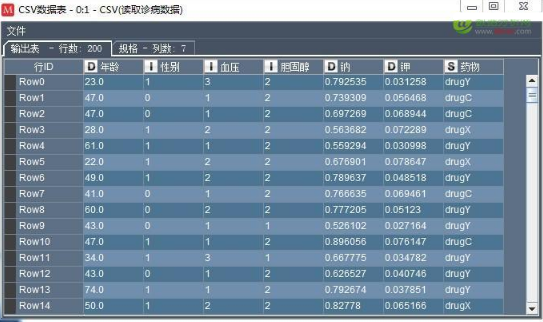
在處理一個陌生的業(yè)務(wù)時��,一是直接從業(yè)務(wù)中學(xué)習(xí)���,二是從數(shù)據(jù)中學(xué)習(xí)業(yè)務(wù)�����。從圖中可以看出���,其中,年齡�����、性別���、血壓���、膽固醇�、鈉����、鉀是病人的指標(biāo),而藥物是醫(yī)生針對病人的情況開出的藥物�����。
確定業(yè)務(wù)目標(biāo):建立專家診病系統(tǒng)���,當(dāng)把病人的指標(biāo)輸入到該系統(tǒng)時��,系統(tǒng)會自動輸出該給此類病人開出的藥物。核心關(guān)鍵就是將業(yè)務(wù)目標(biāo)轉(zhuǎn)化為數(shù)據(jù)挖掘目標(biāo)���。
數(shù)據(jù)挖掘目標(biāo):建立專家診病模型�,該模型以病人的病例指標(biāo)為輸入�����,以藥物為目標(biāo),建立預(yù)測模型����,該模型可以根據(jù)輸入指標(biāo)的值,計算預(yù)測值(藥物)����。
操作實現(xiàn):
2)新建工作流
可以點擊文件菜單下的“新建”開始創(chuàng)建工作流。點擊后會彈出以下向?qū)Ы缑妫?
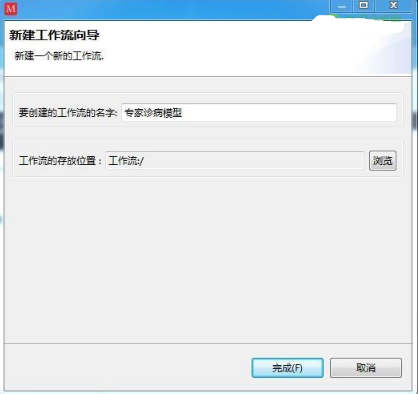
輸入工作流的名字后即可完成創(chuàng)建:
3)導(dǎo)入數(shù)據(jù)
此時要根據(jù)數(shù)據(jù)存儲文件的格式選擇相應(yīng)的導(dǎo)入節(jié)點����。在這里由于數(shù)據(jù)源是CSV文件,因此可以選擇CSV導(dǎo)入節(jié)點(也可以使用可變文件)�����。左側(cè)節(jié)點庫中CSV導(dǎo)入節(jié)點拖到右側(cè)的工作流中�。雙擊節(jié)點或者右鍵菜單中選擇“配置”,彈出如下配置窗口:
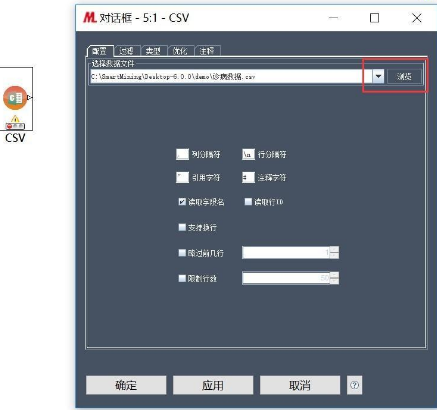
點擊<瀏覽>按鈕���,選擇相應(yīng)的數(shù)據(jù)文件�。
注意���,根據(jù)數(shù)據(jù)表的數(shù)據(jù)結(jié)構(gòu)進(jìn)行配置�����,此數(shù)據(jù)如圖配置即可����。配置好之后點擊<確認(rèn)>。
節(jié)點下方的預(yù)警符號從變?yōu)辄S色說明配置正確�,黃色表示節(jié)點可以執(zhí)行。紅色表示節(jié)點尚未配置或者配置有誤����,此時節(jié)點不可執(zhí)行。單擊節(jié)點����,點擊右鍵菜單的或者點擊工具欄的,即可執(zhí)行工作流���。執(zhí)行完成后預(yù)警符號變成綠色����。
點擊右鍵菜單的文件表可以查詢數(shù)據(jù)��。
4)理解數(shù)據(jù)
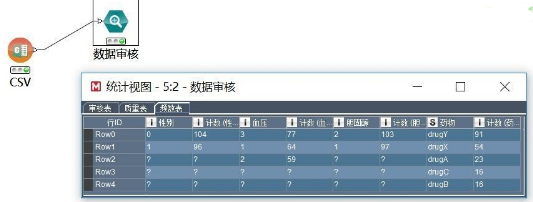
使用統(tǒng)計學(xué)習(xí)菜單下的數(shù)據(jù)審核可以對數(shù)據(jù)進(jìn)行描述�,這是建模之前必須要做的工作,一方面是為了設(shè)計合理的實施方案��,另外一方面也是為了更好的選擇合適的算法�����。
將數(shù)據(jù)審核節(jié)點與數(shù)據(jù)源節(jié)點連接�����,右鍵單擊執(zhí)行��,執(zhí)行結(jié)束之后���,右鍵點擊查看統(tǒng)計視圖�����。結(jié)果如下圖:
從中可以看出每種分類變量的取值及每種取值的個數(shù)��。比如�,從這里我們可以看出藥物字段一共包含五種取值���,且出現(xiàn)最多的是Y藥物����。在這里目標(biāo)變量為分類型,因此只能選擇分類預(yù)測類模型�,如決策樹、邏輯回歸等���。
5)預(yù)建模
接下來便是嘗試建模��,看看建模效果���。
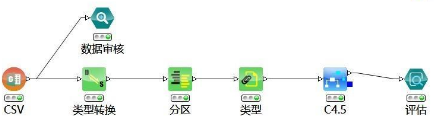
首先,從數(shù)據(jù)準(zhǔn)備>列菜單下選擇類型轉(zhuǎn)換節(jié)點���。由于性別�����、血壓���、膽固醇三個字段實際存儲類型該是字符型,但這里是整型�����,因此為了便于以下分析����,使用類型轉(zhuǎn)換節(jié)點將它們的類型從整型轉(zhuǎn)化為字符型。在數(shù)據(jù)挖掘過程匯總�����,一定要注意數(shù)據(jù)類型�����。配置如下:
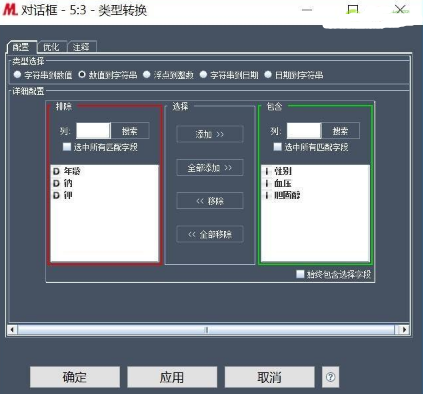
其次�����,使用類型節(jié)點指定目標(biāo)變量的角色�����,將藥物的角色設(shè)為目標(biāo)�����。
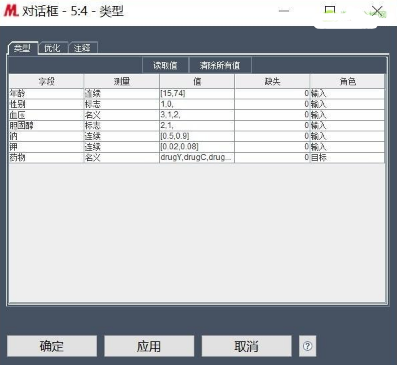
在進(jìn)行模型構(gòu)建的時候一定要確定字段的角色�,給算法以明確的指示���。
然后,選擇分類預(yù)測節(jié)點�,因為目標(biāo)變量(藥物)為分類型。此處我們重點學(xué)習(xí)決策樹算法��。節(jié)點連接如工作流所示���,在決策樹節(jié)點配置中選擇目標(biāo)變量藥物���。其中,決策樹節(jié)點連接分區(qū)節(jié)點��。決策樹訓(xùn)練節(jié)點可以采用默認(rèn)配置���,無需修改配置�����,如下:
最后����,使用評估節(jié)點評估模型的準(zhǔn)確性,默認(rèn)無需配置����。評估結(jié)果:
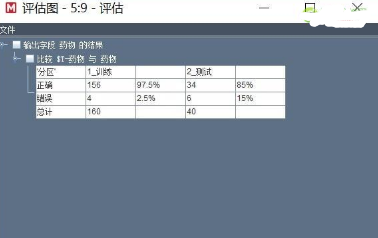
從表3中可以看出�����,模型測試準(zhǔn)確度為97.5%��,誤判2.5%����。但是測試數(shù)據(jù)的錯誤率達(dá)到了15%。一般我們通過分區(qū)節(jié)點將數(shù)據(jù)分為訓(xùn)練數(shù)據(jù)和測試數(shù)據(jù)�����,這樣做主要的目標(biāo)是檢測模型是否存在過度擬合�,如果沒有測試數(shù)據(jù)集,單獨看模型的訓(xùn)練結(jié)果很好��,但是這樣的模型在實際中的適應(yīng)性比較差�。
恭喜你完成了一個簡化的數(shù)據(jù)預(yù)建模過程。
從本模型看�����,預(yù)測的準(zhǔn)確性比較高,�,但是模型的應(yīng)用結(jié)果不好,我們繼續(xù)嘗試����,看是否還有優(yōu)化的可能。
6)數(shù)據(jù)探索
數(shù)據(jù)探索最核心的一項工作就是探索輸入變量與目標(biāo)變量(自變量與因變量)的相關(guān)性���。分析變量的相關(guān)性可以使用相關(guān)性計算�,也可以使用圖形分析�,而后者直觀常用。分析兩個分類型變量可以使用條形圖�����、散點圖或者直方圖�。分析兩個數(shù)值型變量可以使用散點圖。分析一個數(shù)值型變量和一個分類型變量可以使用直方圖����。分析兩個字符型變量的關(guān)系可以使用條形圖。
選擇交互條形圖進(jìn)行字符串字段的可視化探索�。(節(jié)點在可視化探索>交互視圖>交互條形圖)。分類字段選擇目標(biāo)字段藥物,顏色標(biāo)記選擇字符型的字段��。通過觀察條形圖�,我們來看藥物與幾個字段間的相關(guān)性。
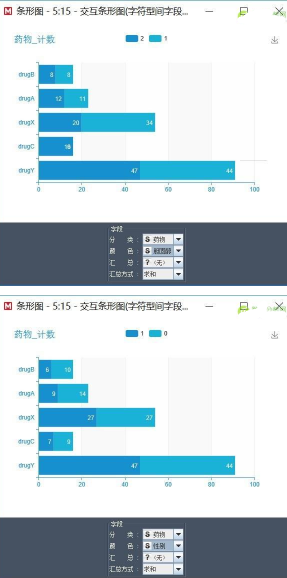
通過分析����,血壓和藥物字段有著強相關(guān)性���,因為從圖中可以看出使用藥物B和藥物A的人都是高血壓(3表示高血壓��,2表示正常�����,1表示低血壓)����,使用藥物C的人都是正常���,這種很明細(xì)的規(guī)律反映出兩個字段間存在很強的相關(guān)關(guān)系�����,如下圖所示:

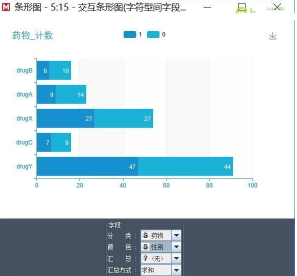
同理�����,膽固醇和選擇藥物之間也有一定相關(guān)性����,而性別和選擇藥物相關(guān)性不大,如下圖所示:
接下來分析數(shù)值型字段的相關(guān)性��,此時我們使用條形圖����。從圖中可以看出血液中的鈉和鉀相關(guān)性很弱或者沒有。從圖形化的方式判斷相關(guān)性強弱的方法就是看圖形中的規(guī)律����,規(guī)律越明顯,相關(guān)性就越強��,否則越弱�。
就此圖來說,散點圖中的每一個點表示一個病例����,而我們最想知道的還不是鈉和鉀的相關(guān)性���,而是兩者與藥物的相關(guān)性,因為藥物才是我們分析的目標(biāo)�����。所以我們還想知道散點圖中的每個病例使用的什么藥物����。可視化探索的核心是目標(biāo)變量與輸入變量的關(guān)系��,所以探索不能夠脫離目標(biāo)變量����。
因此��,我們使用藥物作為顏色區(qū)分���,重新修正散點圖�����。如下:
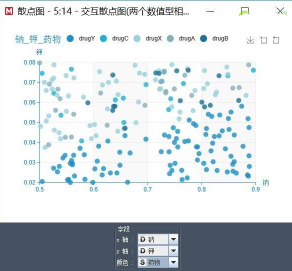
從圖中可見����,下三角區(qū)都是深藍(lán)色,說明這部分病例使用的都是Y藥物����。這是很明顯的規(guī)律,說明這里面有一種很強的關(guān)聯(lián)�����。用數(shù)學(xué)的語言來描述�,就是鈉和鉀的比例與藥物有很強的相關(guān)性。因此����,我們發(fā)現(xiàn)了一個很重要的變量就是鈉和鉀的比例。因此�����,我們可以派生一個變量:鈉鉀比�����。
7)優(yōu)化輸入
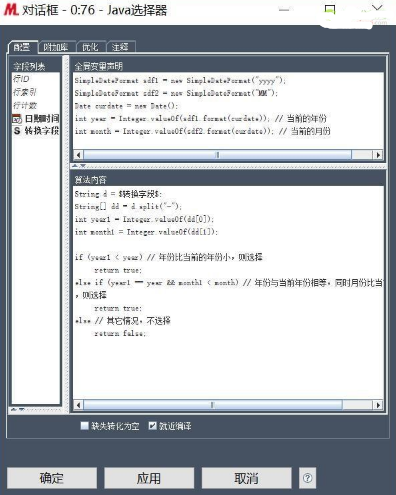
首先���,使用派生字段節(jié)點或者Java代碼段節(jié)點生成鈉鉀比字段���。配置如下:
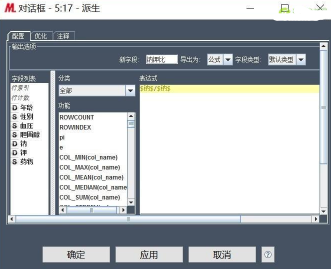
其次��,使用過濾節(jié)點過濾鈉和鉀字段�����,嘗試在不適用鈉���、鉀字段,而引入鈉鉀比字段的����,通過以上的可視化探索,性別與藥物的相關(guān)性不強��,也過濾掉��。所以�����,配置如下:
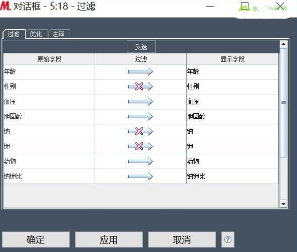
過濾后預(yù)覽數(shù)據(jù)如下(右鍵執(zhí)行�����,執(zhí)行完成后�,右鍵查看數(shù)據(jù)表):
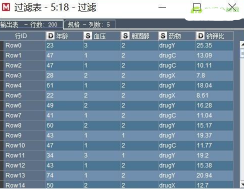
8)重新建模
模型整體評估如下:
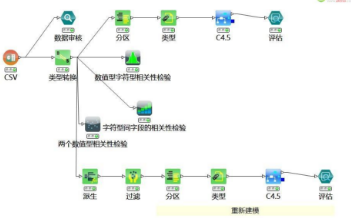
我們點擊決策樹節(jié)點右鍵查看變量重要性視圖。

結(jié)果如下所示:
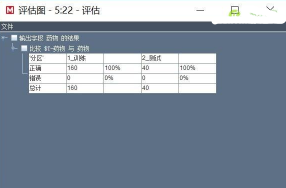
從評估圖中可看出����,模型精度從原來的85%提升帶了100%。當(dāng)然實際中如果遇到預(yù)測精度為100%的情況一定就是錯的��。
下面我們再來解讀一下得到的決策樹模型���,可以直觀的了解決策樹算法��。如下圖所示:
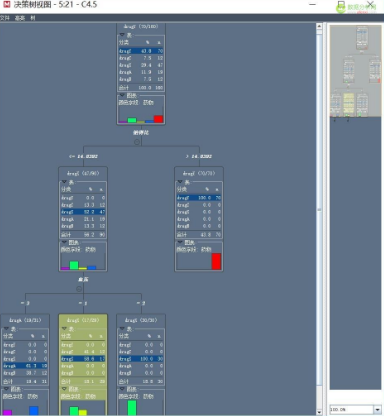
從整體來看����,得此類病的人有大約一半的人(45%)選擇服用了Y藥物;
如果病人血液中鈉和鉀的比例大于14.8285�����,則選擇服用Y藥物�,準(zhǔn)確率為100%;
如果病人血液中鈉和鉀的比例不大于14.8285,若全部判成X藥物準(zhǔn)確率只有47.5%�,因此再看病人的另外一個指標(biāo)血壓;
如果血壓(其值有1�����、2和3)為2�����,則全部判為X藥物����,準(zhǔn)確率為100%;
如果血壓為1����,全部判為C藥物,準(zhǔn)確率僅50%�。再看另外一個指標(biāo)膽固醇,若膽固醇的值為1��,全部判為X藥物����,則準(zhǔn)確率為100%����。若膽固醇的值為2��,全部判為C藥物���,則準(zhǔn)確率為100%。
如果血壓為3���,全部判為A藥物��,則準(zhǔn)確率僅56.8%����。再看另外一個指標(biāo)年齡����,若年齡大于50.5歲,判為B藥物����,則準(zhǔn)確率100%。若年齡不大于50.5歲����,判為A藥物,準(zhǔn)確率為100%。
總結(jié)
第一��,在建模中�,應(yīng)該注意過擬合問題。在商業(yè)中建模的目的是為了商業(yè)應(yīng)用���,因此不僅要保證模型的準(zhǔn)確性�����,更要保證模型的穩(wěn)定性�����。
第二�,模型應(yīng)用的核心是模型的風(fēng)險控制���。只有可以控制風(fēng)險的模型才可以使用�����,否則不管理論模型建的多么漂亮都是沒有實際意義的�。
第三�����,數(shù)據(jù)挖掘的成果并不只是數(shù)學(xué)模型�,數(shù)據(jù)挖掘也不等價于高級模型(如決策樹、神經(jīng)網(wǎng)絡(luò)等)�����。數(shù)據(jù)挖掘關(guān)鍵是實際應(yīng)用與指導(dǎo)�����。
第四�,數(shù)據(jù)挖掘的一個核心工作就是圖形化探索,貌似很簡單卻又最為重要���。因為這是數(shù)據(jù)挖掘思路的源泉���。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情����;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330