spss進行判別分析步驟_spss判別分析結(jié)果解釋_spss判別分析案例詳解
1.Discriminant Analysis判別分析主對話框 如圖 1-1 所示
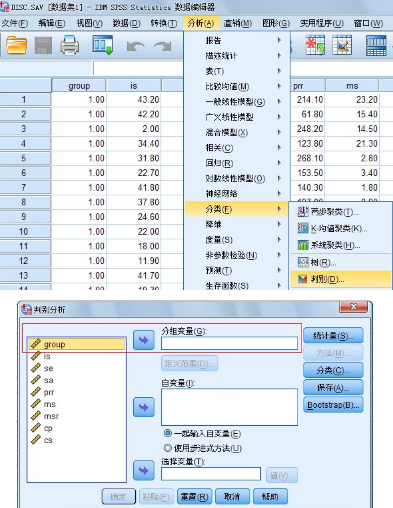
圖 1-1 Discriminant Analysis 主對話框
(1)選擇分類變量及其范圍
在主對話框中左面的矩形框中選擇表明已知的觀測量所屬類別的變量(一定是離散變量)��,
按上面的一個向右的箭頭按鈕���,使該變量名移到右面的Grouping Variable 框中。
此時矩形框下面的Define Range 按鈕加亮�,按該按鈕屏幕顯示一個小對話框如圖1-2 所示,供指定該分類變量的數(shù)值范圍��。
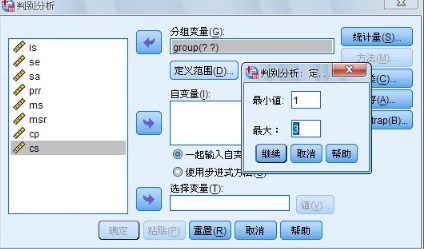
圖 1-2 Define Range 對話框
在Minimum 框中輸入該分類變量的最小值在Maximum 框中輸入該分類變量的最大值���。按Continue 按鈕返回主對話框��。
(2)指定判別分析的自變量
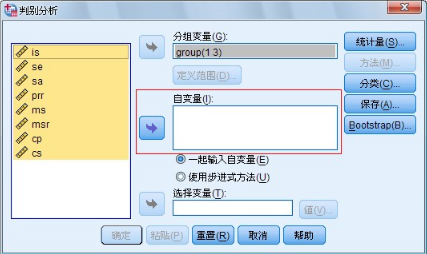
圖 1-3 展開 Selection Variable 對話框的主對話框
在主對話框的左面的變量表中選擇表明觀測量特征的變量����,按下面一個箭頭按鈕����。
把選中的變量移到Independents 矩形框中���,作為參與判別分析的變量�����。
(3) 選擇觀測量
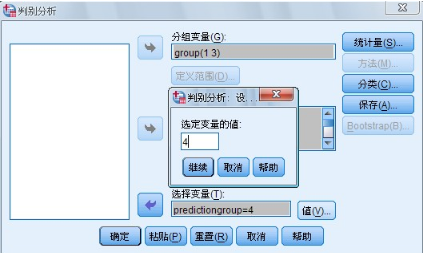
圖 1-4 Set Value 子對話框
如果希望使用一部分觀測量進行判別函數(shù)的推導(dǎo)而且有一個變量的某個值可以作為這些觀測量的標識����,
則用Select 功能進行選擇,操作方法是單擊Select 按鈕展開Selection Variable�����。選擇框如圖1-3 所示��。
并從變量列表框中選擇變量移入該框中再單擊Selection Variable 選擇框右側(cè)的Value按鈕�����,
展開Set Value(子對話框)對話框�����,如圖1-4 所示��,鍵入標識參與分析的觀測量所具有的該變量值�,
一般均使用數(shù)據(jù)文件中的所有合法觀測量此步驟可以省略���。
(4) 選擇分析方法
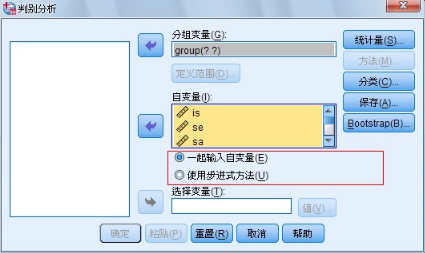
在主對話框中自變量矩形框下面有兩個選擇項����,被選中的方法前面的圓圈中加有黑點。這兩個選擇項是用于選擇判別分析方法的
l Enter independent together 選項�����,當認為所有自變量都能對觀測量特性提供豐富的信息時���,使用該選擇項���。選擇該項將不加選擇地使用所有自變量進行判別分析,建立全模型��,不需要進一步進行選擇�����。
l Use stepwise method 選項����,當不認為所有自變量都能對觀測量特性提供豐富的信息時�����,使用該選擇項。因此需要判別貢獻的大小�,再進行選擇當鼠標單擊該項時Method 按鈕加亮,可以進一步選擇判別分析方法��。
2.Method對話框 如圖 1-5 所示:
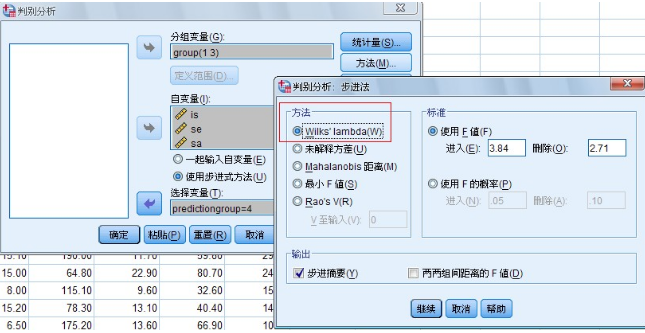
圖 1-5 Stepwise Method 對話框
單擊“Method”按鈕展開Stepwise Method對話框��。
(1)Method 欄選擇進行逐步判別分析的方法
可供選擇的判別分析方法有:
l Wilks’lambda 選項�����,每步都是Wilk 的概計量最小的進入判別函數(shù)
l Unexplained variance 選項���,每步都是使各類不可解釋的方差和最小的變量進入判別函數(shù)�����。
l Mahalanobis’distance 選項��,每步都使靠得最近的兩類間的Mahalanobis 距離最大的變量進入判別函數(shù)
l Smallest F ratio 選項���,每步都使任何兩類間的最小的F 值最大的變量進入判刑函數(shù)
l Rao’s V 選項���,每步都會使Rao V 統(tǒng)計量產(chǎn)生最大增量的變量進入判別函數(shù)??梢詫σ粋€要加入到模型中的變量的V 值指定一個最小增量。選擇此種方法后�����,應(yīng)該在該項下面的V-to-enter 后的矩形框中輸入這個增量的指定值���。當某變量導(dǎo)致的V值增量大于指定值的變量后進入判別函數(shù)����。
(2) Criteria 欄選擇逐步判別停止的判據(jù)
可供選擇的判據(jù)有:
l Use F value 選項��,使用F值�����,是系統(tǒng)默認的判據(jù)當加人一個變量(或剔除一個變量)后�����,對在判別函數(shù)中的變量進行方差分析�����。當計算的F值大于指定的Entry 值時���,該變量保留在函數(shù)中����。默認值是Entry為3.84:當該變量使計算的F值小于指定的Removal 值時����,該變量從函數(shù)中剔除。默認值是Removal為2.71�����。即當被加入的變量F 值為3.84 時才把該變量加入到模型中��,否則變量不能進入模型�;或者��,當要從模型中移出的變量F值<2.71時,該變量才被移出模型,否則模型中的變量不會被移出.設(shè)置這兩個值時應(yīng)該注意Entry值〉Removal 值����。 l Use Probability of F選項�����,用F檢驗的概率決定變量是否加入函數(shù)或被剔除而不是用F值��。加入變量的F值概率的默認值是0.05(5%);移出變量的F 值概率是0.10(10%)��。Removal值(移出變量的F值概率) >Entry值(加入變量的F值概率)���。
(3) Display欄顯示選擇的內(nèi)容
對于逐步選擇變量的過程和最后結(jié)果的顯示可以通過Display 欄中的兩項進行選擇:
l Summary of steps 復(fù)選項���,要求在逐步選擇變量過程中的每一步之后顯示每個變量的統(tǒng)計量。
l F for Pairwise distances 復(fù)選項�,要求顯示兩兩類之間的兩兩F 值矩陣。
3.Statistics對話框 指定輸出的統(tǒng)計量如圖1-6 所示:
圖 1-6 Statistics 對話框
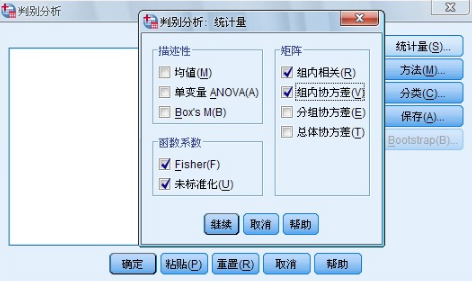
可以選擇的輸出統(tǒng)計量分為以下3 類:
(l) 描述統(tǒng)計量
在 Descriptives 欄中選擇對原始數(shù)據(jù)的描述統(tǒng)計量的輸出:
l Means 復(fù)選項���,可以輸出各類中各自變量的均值MEAN���、標準差std Dev 和各自變量總樣本的均值和標準差。
l Univariate ANOV 復(fù)選項�����,對各類中同一自變量均值都相等的假設(shè)進行檢驗����,輸出單變量的方差分析結(jié)果。
l Box’s M 復(fù)選項�,對各類的協(xié)方差矩陣相等的假設(shè)進行檢驗。如果樣本足夠大�����,表明差異不顯著的p 值表明矩陣差異不明顯�。
(2) Function coefficients 欄:選擇判別函數(shù)系數(shù)的輸出形式
l Fisherh’s 復(fù)選項,可以直接用于對新樣本進行判別分類的費雪系數(shù)���。對每一類給出一組系數(shù)���。并給出該組中判別分數(shù)最大的觀測量。
l Unstandardized 復(fù)選項���,未經(jīng)標準化處理的判別系數(shù)���。
(3) Matrices 欄:選擇自變量的系數(shù)矩陣
l Within-groups correlation matrix復(fù)選項�����,即類內(nèi)相關(guān)矩陣���,
它是根據(jù)在計算相關(guān)矩陣之前將各組(類)協(xié)方差矩陣平均后計算類內(nèi)相關(guān)矩陣。
l Within-groups covariance matrix復(fù)選項����,即計算并顯示合并類內(nèi)協(xié)方差矩陣,
是將各組(類)協(xié)方差矩陣平均后計算的�。區(qū)別于總協(xié)方差陣。
l Separate-groups covariance matrices復(fù)選項��,對每類輸出顯示一個協(xié)方差矩陣��。
l Total covariance matrix復(fù)選項���,計算并顯示總樣本的協(xié)方差矩陣����。
4.Classification 對話框指定分類參數(shù)和判別結(jié)果 如圖1-7 所示
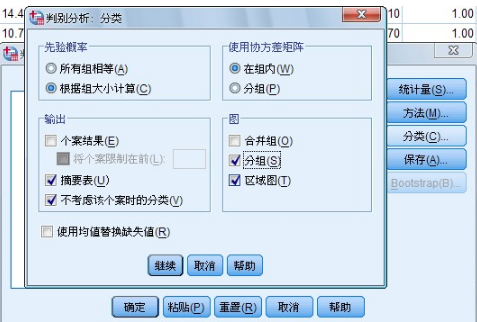
圖 1-7 Classification 對話框
5.Save對話框,指定生成并保存在數(shù)據(jù)文件中的新變量����。如圖1-8 所示:
圖 1-8 Save 對話框
6.選擇好各選擇項之后���,點擊“OK”按鈕����,提交運行Discriminant過程。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試��,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330