spss logistic回歸分析結(jié)果如何分析
如何用spss17.0進(jìn)行二元和多元logistic回歸分析
一���、二元logistic回歸分析
二元logistic回歸分析的前提為因變量是可以轉(zhuǎn)化為0����、1的二分變量,如:死亡或者生存�����,男性或者女性�����,有或無(wú)��,Yes或No��,是或否的情況��。
下面以醫(yī)學(xué)中不同類型腦梗塞與年齡和性別之間的相互關(guān)系來(lái)進(jìn)行二元logistic回歸分析����。
(一)數(shù)據(jù)準(zhǔn)備和SPSS選項(xiàng)設(shè)置
第一步��,原始數(shù)據(jù)的轉(zhuǎn)化:如圖1-1所示���,其中腦梗塞可以分為ICAS���、ECAS和NCAS三種�,但現(xiàn)在我們僅考慮性別和年齡與ICAS的關(guān)系���,因此將分組數(shù)據(jù)ICAS��、ECAS和NCAS轉(zhuǎn)化為1�����、0分類����,是ICAS賦值為1�,否賦值為0。年齡為數(shù)值變量��,可直接輸入到spss中���,而性別需要轉(zhuǎn)化為(1�����、0)分類變量輸入到spss當(dāng)中����,假設(shè)男性為1,女性為0��,但在后續(xù)分析中系統(tǒng)會(huì)將1�����,0置換(下面還會(huì)介紹)�����,因此為方便期間我們這里先將男女賦值置換�����,即男性為“0”��,女性為“1”���。 圖 1-1
第二步:打開(kāi)“二值Logistic 回歸分析”對(duì)話框:
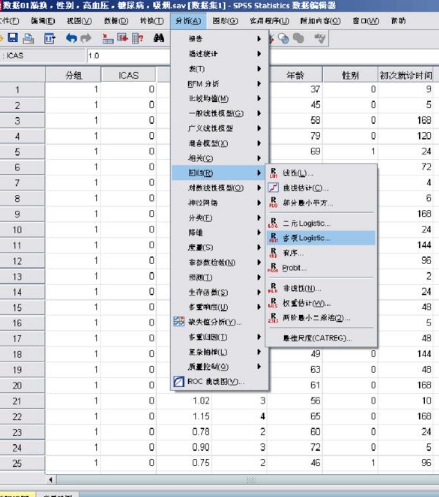
沿著主菜單的“分析(Analyze)→回歸(Regression)→二元logistic(Binary Logistic)”的路徑(圖1-2)打開(kāi)二值Logistic 回歸分析選項(xiàng)框(圖1-3)。
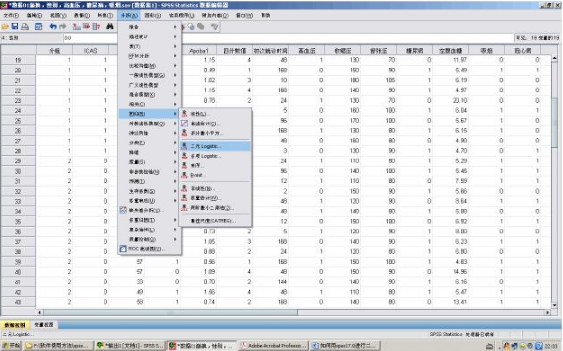
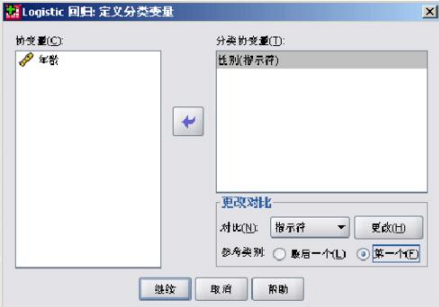
如圖1-3左側(cè)對(duì)話框中有許多變量��,但在單因素方差分析中與ICAS顯著相關(guān)的為性別、年齡����、有無(wú)高血壓,有無(wú)糖尿病等(P<0.05)��,因此我們這里選擇以性別和年齡為例進(jìn)行分析�����。
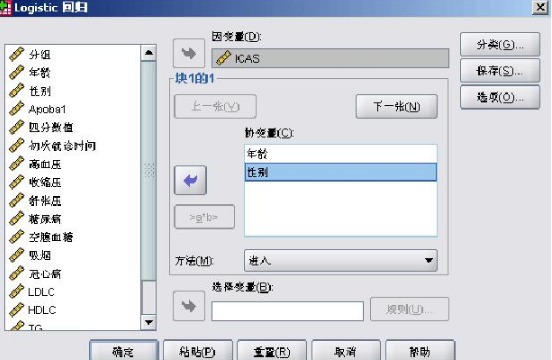
在圖1-3中�,因?yàn)槲覀円?a href="http://www.3lll3.cn/view/19600.html" target="_blank">分析性別和年齡與ICAS的相關(guān)程度,因此將ICAS選入因變量(Dependent)中�����,而將性別和年齡選入?yún)f(xié)變量(Covariates)框中��,在協(xié)變量下方的“方法(Method)”一欄中��,共有七個(gè)選項(xiàng)�。采用第一種方法,即系統(tǒng)默認(rèn)的強(qiáng)迫回歸方法(進(jìn)入“Enter”)�����。 接下來(lái)我們將對(duì)分類(Categorical),保存(Save)��,選項(xiàng)(Options)按照如圖1-4�、1-5、1-6中所示進(jìn)行設(shè)置�。在“分類”對(duì)話框中,因?yàn)樾詣e為二分類變量�����,因此將其選入分類協(xié)變量中�,參考類別為在分析中是以最小數(shù)值“0(第一個(gè))”作為參考,還是將最大數(shù)值“1(最后一個(gè))”作為參考�,這里我們選擇第一個(gè)“0”作為參考。在“存放”選項(xiàng)框中是指將不將數(shù)據(jù)輸出到編輯顯示區(qū)中����。在“選項(xiàng)”對(duì)話框中要勾選如圖幾項(xiàng),其中“exp(B)的CI(X)”一定要勾選���,這個(gè)就是輸出的OR和CI值�����,后面的95%為系統(tǒng)默認(rèn)�,不需要更改���。
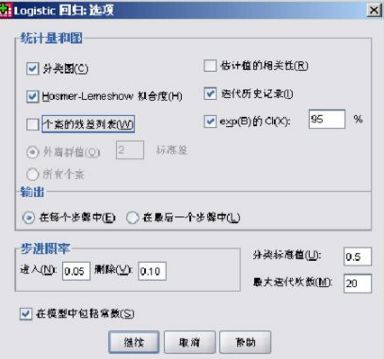
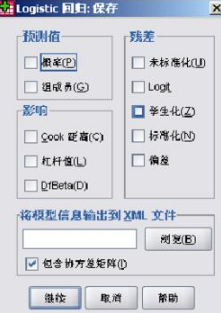
另外在“選項(xiàng)”對(duì)話框中�����,“輸出”一欄中����,系統(tǒng)默認(rèn)為“在每個(gè)步驟中”�����,這里更改為“在最后一個(gè)步驟中”���,即:輸出結(jié)果將僅僅給出最終結(jié)果����,而省略每一步的計(jì)算過(guò)程�。由于我們采用強(qiáng)迫回歸,逐步回歸概率選項(xiàng)可以不管
此外還有一個(gè)選項(xiàng)需要說(shuō)明��。一是分類臨界值(Classification cutoff),默認(rèn)值為0.5��,即按四舍五入的原則將概率預(yù)測(cè)值化為0 或者1
����。如果
將數(shù)值改為0.6,則大于等于0.6 的概率值才表示為1�,否則為0。其情況余依此類推�����。二是最大迭代值(Maximum Iterations)�,規(guī)定系統(tǒng)運(yùn)算的迭代次數(shù),默認(rèn)值為20 次�����,為安全起見(jiàn)����,我們將迭代次數(shù)增加到50。原因是���,有時(shí)迭代次數(shù)太少��,計(jì)算結(jié)果不能真正收斂�����。三是模型中包括常數(shù)項(xiàng)(Include constant in model)�����,即模型中保留截距�。除了迭代次數(shù)之外�����,其余兩個(gè)選項(xiàng)均采用系統(tǒng)默認(rèn)值���。
完成后�,點(diǎn)擊各項(xiàng)中“繼續(xù)(Continue)”按鈕����。返回圖1-3,單擊“確定”按鈕�。
(二)結(jié)果解讀
其他結(jié)果參照文章《利用SPSS進(jìn)行Logistic回歸分析》中解讀,這里重點(diǎn)將兩點(diǎn): 第一���,分類變量編碼(圖1-7)�,由于這里包括性別分類變量,而我們對(duì)性別賦值為1和0���,但在spss中系統(tǒng)會(huì)默認(rèn)把我們的數(shù)值進(jìn)行置換�,即1→參數(shù)編碼0���,0→參數(shù)編碼1����,而最終輸出結(jié)果是以1來(lái)計(jì)算的�,而0為參考數(shù)據(jù)。所以這也就是為什么我么之前要對(duì)研究組男性的賦值進(jìn)行置換了�。如果男性為1那么spss中最終輸出的將是女性的分析結(jié)果。
圖1-7
第二��,最終輸出數(shù)據(jù)(圖1-8)在該結(jié)果中���,Exp(B)即為文獻(xiàn)中提及的OR值�����,而EXP(B)的95%C.I.即為文獻(xiàn)中提及的CI值����。其中Exp(B)表示某因素(自變量)內(nèi)該類別是其相應(yīng)參考類別具有某種傾向性的倍數(shù)。而有的文獻(xiàn)中提到的Crode OR和Adjust OR則分別為單因素優(yōu)勢(shì)率(Crode odds ratio)和多因素優(yōu)勢(shì)率(Adjust odds ratio)��,即僅對(duì)性
別單個(gè)變量的單因素分析或者對(duì)性別和年齡等多個(gè)變量進(jìn)行多因素分析后所得到的不同結(jié)果�。CI則為可信區(qū)間(Confidence interval)。Sig.即我們常說(shuō)的P值�,P<0.05為顯著(無(wú)效假說(shuō)不成立,具有統(tǒng)計(jì)學(xué)意義)�����,P>0.05為不顯著(無(wú)效假說(shuō)成立����,不具有統(tǒng)計(jì)學(xué)意義)��。 二��、多項(xiàng)(多元�����、多分類���、Multinomial)logistic回歸分析
前面講的二元logistic回歸分析僅適合因變量Y只有兩種取值(二分類)的情況����,當(dāng)Y具有兩種以上的取值時(shí),就要用多項(xiàng)logistic回歸(Mutinomial Logistic Regression)分析了��。這種分析不僅可以用于醫(yī)療領(lǐng)域����,也可以用于社會(huì)學(xué)、經(jīng)濟(jì)學(xué)�、農(nóng)業(yè)研究等多個(gè)領(lǐng)域。如不同階段(初
一���、初二�����、初三)學(xué)生視力下降程度���,不同齲齒情況(輕度、中度�、重度)下與刷牙、飲食����、年齡的關(guān)系等�。
下面我們以圖1-2中�,對(duì)apoba1(ApoB/AI)項(xiàng)中數(shù)值做四分位數(shù)后,將病人的ApoB/AI的比值劃分為低���、較低�����、中�、高四個(gè)分位后利用多項(xiàng)logistic回歸分析其與ICAS之間的相互關(guān)系�。
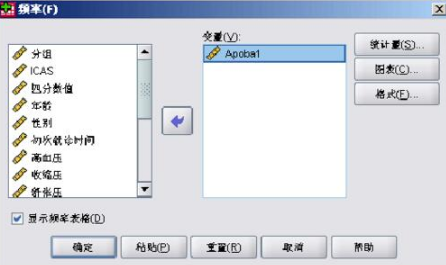
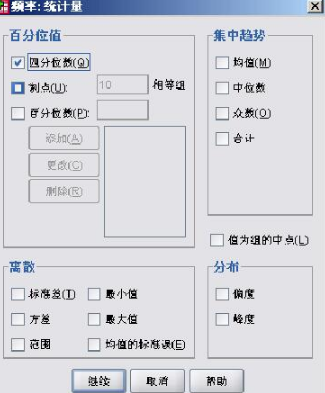
首先來(lái)做四分位數(shù),很多人在做四分位數(shù)的時(shí)候都是自己算出來(lái)的���,其實(shí)在SPSS里面給出了做四分位數(shù)的程度即分析(Aanlyze)→描述統(tǒng)計(jì)(Descriptive Statistics)→頻率(Frequencies)。打如圖2-1開(kāi)頻率對(duì)話框��。將我們要分析的數(shù)值變量Apoba1選入到變量對(duì)話框中�����。 選擇統(tǒng)計(jì)量�,按照?qǐng)D2-2中勾選四分位數(shù)選項(xiàng)����,其他選項(xiàng)按照自己需要勾選�����,然后點(diǎn)擊圖2-1中的確定按鈕�,開(kāi)始運(yùn)算。在圖2-3中可以讀取我們的四分位數(shù)
值�。圖中百分?jǐn)?shù)表示的是對(duì)該變量做的四分位數(shù)的百分比,25表示前25%的�,50表示前50%的,75表示前75%的���。每一項(xiàng)對(duì)應(yīng)的后面數(shù)值即為相應(yīng)的四分位數(shù)�,如0.5904�,即為前25%的個(gè)體與后75%個(gè)體的分位數(shù)。
按照如上方法得出ApoB/AI的比率后我們可以把該比值劃分為四個(gè)區(qū)間���,即當(dāng)ApoB/AI的比率<0.5904為低���、當(dāng)0.5904≤ApoB/AI的比率≤0.88時(shí)為較低、當(dāng)0.89≤ApoB/AI的比率≤1.0886時(shí)為中���,當(dāng)ApoB/AI的比率>1.0886時(shí)為高��。然后將這一劃分如圖1-1中“四分位數(shù)”一項(xiàng)用分類數(shù)值表示即1代表低����,2代表較低,3代表中�,4代表高。這里還要強(qiáng)調(diào)的是我們要研究其與ICAS之間的相互關(guān)系���,那么我們需要將其設(shè)為二分類變量����,即是ICAS的情況為1�,否則為0,但多項(xiàng)logistic回歸分析也會(huì)將1�����,0置換�����,所以我們需要在這里將我們需要研究的情況置換為0����,然后將其他置換為1。下面就可以進(jìn)行多項(xiàng)logistic回歸分析了�。如圖
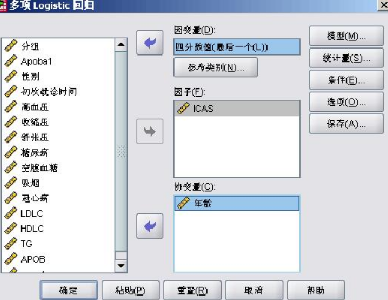
2-4打開(kāi)多項(xiàng)logistic回歸分析對(duì)話框(圖2-5)。
如圖2-5所示����,在”因變量”中選入剛才我們輸入的四分位數(shù)分類變量,在因子中輸入分類變量ICAS(這里一定是分類變量����,可以是一個(gè)也可以是多個(gè)),在“協(xié)變量”中輸入數(shù)值變量如年齡(這里一定是數(shù)值變量����,
可以是一個(gè)也可以是多個(gè)),但因本次沒(méi)有對(duì)年齡進(jìn)行分析���,僅對(duì)ICAS進(jìn)行了單因素分析�����,所以我們把年齡移出協(xié)變量選項(xiàng)����。
在SPSS中對(duì)因變量的定義是,如果因變量Y有J個(gè)值(即Y有J類)��,以其中一個(gè)類別作為參考類別���,其他類別都同他相比較生成J-1個(gè)冗余的Logit變換模型�����,而作為參考類別的其模型中所有系數(shù)均為0����。在SPSS中可以對(duì)所選因變量的參考類別進(jìn)行設(shè)置�,如圖2-5在因變量對(duì)話框下有一“參考類別”選項(xiàng)。點(diǎn)擊后會(huì)彈出圖2-6對(duì)話框����。在該對(duì)話框中我們選中設(shè)定,輸入數(shù)值1�,這代表我們以分類數(shù)值1所代表的類別作為參考類別,即最低數(shù)值作為參考類別��。 單擊繼續(xù)���。當(dāng)然也可以選擇“第一類別”和“最后類別”��,入選中分別表示以最低數(shù)值或最高數(shù)值作為參考類別����。其他設(shè)置與二元Logistic分析相似����,將我們要輸出的項(xiàng)勾選即可,點(diǎn)擊圖2-5中確定����,輸出數(shù)據(jù)。 輸出數(shù)據(jù)基本與二元Logistic分析相似���,我們重點(diǎn)講下最后一項(xiàng)“參考估計(jì)”���,如圖2-7所示,其中參考類別為ICAS=1的分類情況�,而其中的ICAS=0分為2、3�、4三種,分別給出了ICAS=0時(shí)的數(shù)值�����。而其中Exp(B)(即OR值)表示某因素(自變量)內(nèi)該類別是其相應(yīng)參考類別具有某種傾向性的倍數(shù)。如Exp(B)=2.235時(shí)�,即表示在較輕這一類別下ICAS患者數(shù)為其他類別(ECAS和NCAS)的2.235倍。這里面的顯著水平即為P值���。
這里要強(qiáng)調(diào)的是���,一些文獻(xiàn)中在輸出數(shù)據(jù)的時(shí)候經(jīng)常會(huì)給出“Referent(參考)”項(xiàng),這里的Referent��,即為我們這里所選的參考類別1�����,因?yàn)?
1作為參考類別�,所以其所有數(shù)值為0
,即無(wú)數(shù)據(jù)輸出���。因此在文中需標(biāo)注其為Referent����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材���,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�����,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330