數(shù)據(jù)挖掘分類技術(shù)_數(shù)據(jù)挖掘分類
1、過(guò)分?jǐn)M合問(wèn)題:
造成原因有:(1)噪聲造成的過(guò)分?jǐn)M合(因?yàn)樗鼣M合了誤標(biāo)記的訓(xùn)練記錄�,導(dǎo)致了對(duì)檢驗(yàn)集中記錄的誤分類);(2)根據(jù)少量訓(xùn)練記錄做出分類決策的模型也容易受過(guò)分?jǐn)M合的影響���。(由于訓(xùn)練數(shù)據(jù)缺乏具有代表性的樣本����,在沒(méi)有多少訓(xùn)練記錄的情況下,學(xué)習(xí)算法仍然繼續(xù)細(xì)化模型就會(huì)產(chǎn)生這樣的模型��,當(dāng)決策樹(shù)的葉節(jié)點(diǎn)沒(méi)有足夠的代表性樣本時(shí)�,很可能做出錯(cuò)誤的預(yù)測(cè))(3)多重比較也可能會(huì)導(dǎo)致過(guò)分?jǐn)M合(大量的候選屬性和少量的訓(xùn)練記錄最后導(dǎo)致了模型的過(guò)分?jǐn)M合)
2、泛化誤差的估計(jì):
(1)樂(lè)觀估計(jì)(決策樹(shù)歸納算法簡(jiǎn)單的選擇產(chǎn)生最低訓(xùn)練誤差的模型作為最終的模型)(2)悲觀誤差估計(jì)(使用訓(xùn)練誤差與模型復(fù)雜度罰項(xiàng)的和計(jì)算泛化誤差)(3)最小描述長(zhǎng)度原則(模型編碼的開(kāi)銷加上誤分類記錄編碼的開(kāi)銷)(4)估計(jì)統(tǒng)計(jì)上界(泛化誤差可以用訓(xùn)練誤差的統(tǒng)計(jì)修正來(lái)估計(jì)����,因?yàn)榉夯`差傾向于比訓(xùn)練誤差大,所以統(tǒng)計(jì)修正通常是計(jì)算訓(xùn)練誤差的上界)(4)使用確認(rèn)集(如2/3的訓(xùn)練集來(lái)建立模型�����,剩下的用來(lái)做誤差估計(jì))
3���、處理決策樹(shù)中的過(guò)分?jǐn)M合:
A):先剪枝(提前終止規(guī)則):當(dāng)觀察到的不純性度量的增益(或估計(jì)的泛化誤差的改進(jìn))低于某個(gè)確定的閾值時(shí)就停止擴(kuò)展葉節(jié)點(diǎn)����。B):初始決策樹(shù)按照最大規(guī)模生長(zhǎng)�,然后進(jìn)行剪枝的步驟,按照自底向上的方式修剪完全增長(zhǎng)的決策樹(shù)�。修剪有兩種方法:(1)用新的葉節(jié)點(diǎn)替換子樹(shù),該葉節(jié)點(diǎn)的類標(biāo)號(hào)由子樹(shù)下記錄中的多數(shù)類確定�;(2)用子樹(shù)中常見(jiàn)的分支替代子樹(shù)。當(dāng)模型不能再改進(jìn)時(shí)終止剪枝步驟�����。與先剪枝相比�����,后剪枝技術(shù)傾向于產(chǎn)生更好的結(jié)果��。
4����、評(píng)估分類器的方法:
(A):保持方法(用訓(xùn)練集的一部分來(lái)做訓(xùn)練一部分做檢驗(yàn),用檢驗(yàn)的準(zhǔn)確度來(lái)評(píng)估)(B)隨機(jī)二次抽樣(第一種方法進(jìn)行K次不同的迭代���,取其平均值)(C)交叉驗(yàn)證(每個(gè)記錄用于訓(xùn)練的次數(shù)相同���,并且用于檢驗(yàn)恰好一次)(D)自助法(有放回抽樣)
1.1、決策樹(shù)分類
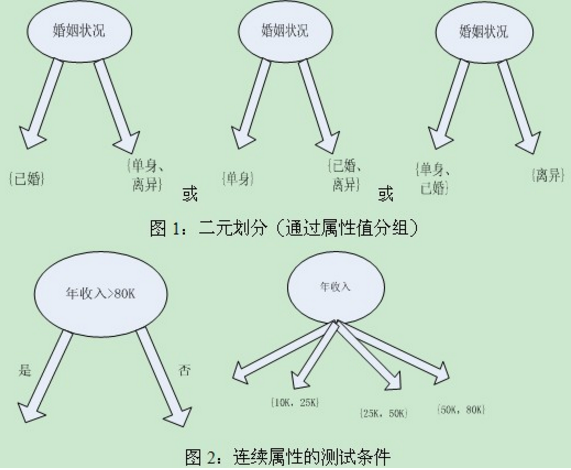
算法思想:遞歸的選擇一個(gè)屬性對(duì)對(duì)象集合的類標(biāo)號(hào)進(jìn)行分類�����,如果分類到某一屬性時(shí)發(fā)現(xiàn)剩下的對(duì)象屬于同一類,此時(shí)就不必再選擇屬性就行分類��,而只用創(chuàng)建一個(gè)葉節(jié)點(diǎn)并用共同的類來(lái)代表�����。否則���,繼續(xù)選擇下一屬性進(jìn)行分類操作�,直到某一分類結(jié)果全在同一類或者沒(méi)有屬性可供選擇為止��。根據(jù)選擇屬性的順序可以將決策樹(shù)算法分為ID3,C4.5等��。其中�����,決策樹(shù)算法CART只產(chǎn)生二元?jiǎng)澐?�,它們考慮創(chuàng)建K個(gè)屬性的二元?jiǎng)澐值乃?^(k-1)-1中方法��。圖1顯示了把婚姻狀況的屬性值劃分為兩個(gè)子集的三種不同的分組方法����。對(duì)于連續(xù)屬性來(lái)說(shuō)�����,測(cè)試條件可以是具有二元輸出的比較測(cè)試(A<v< font=”” style=”word-wrap: break-word;”>)或(A>=v),也可以是具有形如vi<=A<=vi+1(i=1,21��,…��,k)輸出的范圍查詢(如圖2所示)��。
問(wèn):預(yù)測(cè)集中的每條記錄的屬性取值集合是否就和訓(xùn)練集的某一個(gè)記錄的屬性取值集合相等����?
答:不一定,一般來(lái)說(shuō)是不可能的���。但是建立的決策樹(shù)一定包含該取值集合(但是可能范圍會(huì)大些)����。因?yàn)?a href='/map/jueceshu/' style='color:#000;font-size:inherit;'>決策樹(shù)建過(guò)程是只要當(dāng)前的所有對(duì)象屬于同一個(gè)標(biāo)號(hào)就不再繼續(xù)選擇屬性了��,所以�����,實(shí)際上建立的決策樹(shù)所包含的對(duì)象是比訓(xùn)練集中的對(duì)象要多得多的,這些多余的對(duì)象可能就包含當(dāng)前的預(yù)測(cè)對(duì)象����。這也是決策樹(shù)能夠用來(lái)進(jìn)行分類的原因。
決策樹(shù)歸納的特點(diǎn):
(1)找到最優(yōu)決策樹(shù)是NP完全問(wèn)題����;(2)采用避免過(guò)分?jǐn)M合的方法后決策樹(shù)算法對(duì)于噪聲的干擾具有相當(dāng)好的魯棒性。
1.2�、基于規(guī)則的分類
基于規(guī)則的分類使用一組if…then規(guī)則來(lái)分類記錄的技術(shù)。算法思想:先從訓(xùn)練集生成規(guī)則集合�,規(guī)則是使用合取條件表示的:如規(guī)則ri:(條件i)->yi,其中r1是如下形式:r1:(胎生=否)^(飛行動(dòng)物=是)->鳥(niǎo)類;其中左邊稱為規(guī)則前件或前提;規(guī)則右邊稱為規(guī)則后件�。如果規(guī)則r的前件和記錄x的屬性匹配,則稱r覆蓋x�����。當(dāng)r覆蓋給定的記錄時(shí)�,稱r被激發(fā)或被觸發(fā)。建立規(guī)則集合后�����,就進(jìn)行分類。對(duì)每個(gè)待分類的記錄和規(guī)則集合中的每條規(guī)則進(jìn)行比較�����,如果某條規(guī)則被觸發(fā)�����,該記錄就被分類了�����。
問(wèn):由于規(guī)則集中的規(guī)則不一定是互斥的�,所有有可能分類的時(shí)候某條記錄會(huì)屬于多個(gè)類(也就是說(shuō)某條記錄會(huì)同時(shí)觸發(fā)規(guī)則集中的超過(guò)1條的過(guò)則�����,而被觸發(fā)的規(guī)則的類標(biāo)號(hào)也不一樣)����,這種情況如何處理:
答:有兩種辦法解決這個(gè)問(wèn)題。(1)有序規(guī)則�����。將規(guī)則集中的規(guī)則按照優(yōu)先級(jí)降序排列�,當(dāng)一個(gè)測(cè)試記錄出現(xiàn)時(shí)�����,由覆蓋記錄的最高秩的規(guī)則對(duì)其進(jìn)行分類��,這就避免由多條分類規(guī)則來(lái)預(yù)測(cè)而產(chǎn)生的類沖突問(wèn)題(2)
無(wú)序規(guī)則����。允許一條測(cè)試記錄觸發(fā)多條分類規(guī)則�����,把每條被觸發(fā)規(guī)則的后件看作是對(duì)相應(yīng)類的一次投票�,然后計(jì)票確定測(cè)試記錄的類標(biāo)號(hào)。通常把記錄指派到得票最多的類����。
問(wèn):假設(shè)現(xiàn)在有一個(gè)記錄它不能觸發(fā)規(guī)則集合中的任何一個(gè)規(guī)則,那么它該如何就行分類呢���?
答:解決辦法也有兩個(gè):(1)窮舉規(guī)則���。如果對(duì)屬性值的任一組合,R中都存在一條規(guī)則加以覆蓋,則稱規(guī)則集R具有窮舉覆蓋�����。這個(gè)性質(zhì)確保每一條記錄都至少被R中的一條規(guī)則覆蓋����。(2)如果規(guī)則不是窮舉的,那么必須添加一個(gè)默認(rèn)規(guī)則rd:()->yd來(lái)覆蓋那些未被覆蓋的記錄�。默認(rèn)規(guī)則的前件為空,當(dāng)所有其他規(guī)則失效時(shí)被觸發(fā)��。yd是默認(rèn)類�����,通常被指定為沒(méi)有被現(xiàn)存規(guī)則覆蓋的訓(xùn)練記錄的多數(shù)類�����。
規(guī)則的排序方案:
(1)基于規(guī)則的排序方案:根據(jù)規(guī)則的某種度量對(duì)規(guī)則排序��。這種排序方案確保每一個(gè)測(cè)試記錄都是有=由覆蓋它的“最好的”規(guī)則來(lái)分類���。(2)基于類的排序方案。屬于同一類的規(guī)則在規(guī)則集R中一起出現(xiàn)。然后這些規(guī)則根據(jù)它們所屬的類信息一起排序�����。同一類的規(guī)則之間的相對(duì)順序并不重要�,因?yàn)樗鼈儗儆谕活悺#ù蠖鄶?shù)著名的基于規(guī)則的分類器(C4.5規(guī)則和RIPPER)都采用基于類的排序方案)�。
建立規(guī)則的分類器:
(1)順序覆蓋。直接從數(shù)據(jù)中提取規(guī)則�����,規(guī)則基于某種評(píng)估度量以貪心的方式增長(zhǎng)��,該算法從包含多個(gè)類的數(shù)據(jù)集中一次提取一個(gè)類的規(guī)則�����。在提取規(guī)則時(shí)�����,類y的所有訓(xùn)練記錄被看作是正例�����,而其他類的訓(xùn)練記錄則被看作反例。如果一個(gè)規(guī)則覆蓋大多數(shù)正例��,沒(méi)有或僅覆蓋極少數(shù)反例��,那么該規(guī)則是可取的��。一旦找到這樣的規(guī)則��,就刪掉它所覆蓋的訓(xùn)練記錄��,并把新規(guī)則追加到?jīng)Q策表R的尾部(規(guī)則增長(zhǎng)策略:從一般到特殊或從特殊到一般)(2)RIPPER算法����。(和前面那個(gè)差不多,只是規(guī)則增長(zhǎng)是從一般到特殊的�����,選取最佳的合取項(xiàng)添加到規(guī)則前件中的評(píng)判標(biāo)準(zhǔn)是FOIL信息增益����,直到規(guī)則開(kāi)始覆蓋反例時(shí)���,就停止添加合取項(xiàng)�����。而剪枝是從最后添加的合取項(xiàng)開(kāi)始的���,給定規(guī)則ABCD->y����,先檢查D是否應(yīng)該被刪除���,然后是CD�,BCD等)
基于規(guī)則的分類器的特征:
(1)規(guī)則集的表達(dá)能力幾乎等價(jià)于決策樹(shù)���,因?yàn)?a href='/map/jueceshu/' style='color:#000;font-size:inherit;'>決策樹(shù)可以用互斥和窮舉的規(guī)則集表示����。(2)被很多基于規(guī)則的分類器(如RIPPER)所采用的基于類的規(guī)則定序方法非常適合于處理不平衡的數(shù)據(jù)集���。
1.3��、最近鄰分類器
算法思想:將要測(cè)試的記錄與訓(xùn)練集的每條記錄計(jì)算距離�,然后選擇距離最小的K個(gè)���,將K個(gè)記錄中的類標(biāo)號(hào)的多數(shù)賦給該測(cè)試記錄����,如果所有的類標(biāo)號(hào)一樣多,則隨機(jī)選擇一個(gè)類標(biāo)號(hào)���。該算法的變種:先將訓(xùn)練集中所有的記錄中相同類標(biāo)號(hào)的記錄算出一個(gè)中心記錄��,然后將測(cè)試記錄與中心記錄算距離��,取最小的K個(gè)就行(這個(gè)方法大大的減少了計(jì)算量�,原來(lái)的算法計(jì)算量太大了)���。
問(wèn):該算法沒(méi)有學(xué)習(xí)的過(guò)程?��。?
答:是的�����。所以這個(gè)算法稱為消極學(xué)習(xí)方法��,而之前的那些算法稱為積極學(xué)習(xí)方法���。
最近鄰分類器的特征
最近鄰分類器基于局部信息進(jìn)行預(yù)測(cè)����,而決策樹(shù)和基于規(guī)則的分類器則試圖找到一個(gè)擬合整個(gè)輸入空間的全局模型�����。正因?yàn)檫@樣的局部分類決策�����,最近鄰分類器(K很小時(shí))對(duì)噪聲非常敏感����。
1.3、貝葉斯分類器
貝葉斯定理是一種對(duì)屬性集合類變量的概率關(guān)系建模的方法���,是一種把類的先驗(yàn)知識(shí)和從數(shù)據(jù)集中收集的新證據(jù)相結(jié)合的統(tǒng)計(jì)原理�。貝葉斯分類器的兩種實(shí)現(xiàn):樸素貝葉斯和貝葉斯信念網(wǎng)絡(luò)�。貝葉斯定理(如下)(樸素貝葉斯分類的前提假設(shè)是屬性之間條件獨(dú)立):
P(Y | X) = P(X | Y)P(Y) / P(X)(1-1)
樸素貝葉斯分類分類思想
假設(shè)(1-1)中的X為要分類的記錄,而Y是訓(xùn)練集中的類標(biāo)號(hào)集合��,要將X準(zhǔn)確分類就必須使對(duì)特定的X和所有的分類標(biāo)號(hào)yi�,讓P(yi|X)最大的yi即為測(cè)試記錄的類標(biāo)號(hào)����。由(1-1)知道要讓左邊最大就是讓后邊最大����,而因?yàn)閄是特定的所以就是使P(X | Y)P(Y)(1-2)最大。此時(shí)的yi即為測(cè)試記錄的類標(biāo)號(hào)����。而要計(jì)算(1-2)因?yàn)楦鱾€(gè)屬性是獨(dú)立的,所以直接乘即可(具體見(jiàn)hanjiawei的書(shū)P203例6-4)�����。
問(wèn):在計(jì)算(1-2)時(shí)假設(shè)出現(xiàn)某項(xiàng)是零了怎么辦�?
答:有兩種方法:(1)拉普拉斯校準(zhǔn)或拉普拉斯估計(jì)法。假定訓(xùn)練數(shù)據(jù)庫(kù)D很大�,使得需要的每個(gè)技術(shù)加1造成的估計(jì)概率的變化可以忽略不計(jì),但可以方便的避免概率值為零的情況�。(如果對(duì)q個(gè)計(jì)數(shù)都加上1,則我們必須在用于計(jì)算概率的對(duì)應(yīng)分母上加上q)����。(2)條件概率的m估計(jì)。P(Xi | Yi) = (nc + mp) / (n + m)其中,n是類yi中的實(shí)例總數(shù)�,nc是類yi的訓(xùn)練樣例中取值xi的樣例數(shù)�,m是稱為等價(jià)樣本大小的參數(shù),而p是用戶指定的參數(shù)�����。如果沒(méi)有訓(xùn)練集(即n=0)則P(xi|yi)=p�。因此p可以看作是在yi的記錄中觀察屬性值xi的先驗(yàn)概率。等價(jià)樣本大小決定先驗(yàn)概率p和觀測(cè)概率nc/n之間的平衡�����。
樸素貝葉斯分類器的特征
(1)面對(duì)孤立的噪聲點(diǎn)��,樸素貝葉斯分類器是健壯的����。因?yàn)樵趶臄?shù)據(jù)中估計(jì)條件概率時(shí),這些點(diǎn)被平均�。通過(guò)在建模和分類時(shí)忽略樣例,樸素貝葉斯分類器也可以處理屬性值遺漏問(wèn)題���。(2)面對(duì)無(wú)關(guān)屬性����,該分類器是健壯的。如果xi是無(wú)關(guān)屬性�����,那么P(Xi|Y)幾乎變成了均勻分布�。Xi的條件概率不會(huì)對(duì)總的后驗(yàn)概率產(chǎn)生影響。(3)相關(guān)屬性可能會(huì)降低樸素貝葉斯分類器的性能�����,因?yàn)閷?duì)這些屬性��,條件獨(dú)立假設(shè)已不成立�。
貝葉斯信念網(wǎng)絡(luò)(該方法不要求給定類的所有屬性都條件獨(dú)立,而是允許指定哪些屬性條件獨(dú)立):
貝葉斯信念網(wǎng)絡(luò)(BBN)
這個(gè)方法不要求給定類的所有屬性都條件獨(dú)立��,而是允許指定哪些屬性條件獨(dú)立���。貝葉斯信念網(wǎng)絡(luò)(用圖形表示一組隨機(jī)變量之間的概率關(guān)系)建立后主要有兩個(gè)主要成分:(1)一個(gè)有向無(wú)環(huán)圖��,表示變量之間的依賴關(guān)系(2)一個(gè)概率表(每個(gè)節(jié)點(diǎn)都有)����,把各節(jié)點(diǎn)和它的直接父節(jié)點(diǎn)關(guān)聯(lián)起來(lái)。一個(gè)貝葉斯信念網(wǎng)路的大體樣子如下(左邊):其中表右表只是LungCancer節(jié)點(diǎn)的概率表
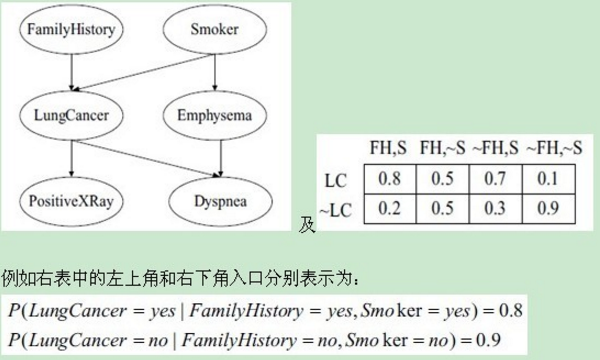
貝葉斯信念網(wǎng)絡(luò)主要思想
根據(jù)已經(jīng)建立好的貝葉斯信念網(wǎng)絡(luò)和每個(gè)節(jié)點(diǎn)的概率表來(lái)預(yù)測(cè)未知記錄的分類���。主要是按照已建立好的網(wǎng)絡(luò)根據(jù)節(jié)點(diǎn)的概率計(jì)算先驗(yàn)概率或后驗(yàn)概率����。計(jì)算概率的方法和前面的樸素貝葉斯計(jì)算過(guò)程相差無(wú)多���。
貝葉斯信念網(wǎng)絡(luò)的建立
網(wǎng)路拓?fù)浣Y(jié)構(gòu)可以通過(guò)主觀的領(lǐng)域?qū)<抑R(shí)編碼獲得,由于要尋找最佳的拓?fù)渚W(wǎng)路有d�����!種方案計(jì)算量較大�����,一種替代的方法是把變量分為原因變量和結(jié)果變量���,然后從各原因變量向其對(duì)應(yīng)的結(jié)果變量畫(huà)弧�。
BBN的特點(diǎn):
(1)貝葉斯網(wǎng)路很適合處理不完整的數(shù)據(jù)����。對(duì)屬性遺漏的實(shí)例可以通過(guò)對(duì)該屬性的所有可能取值的概率求或求積分來(lái)加以處理。(2)因?yàn)閿?shù)據(jù)和先驗(yàn)知識(shí)以概率的方式結(jié)合起來(lái)了,所以該方法對(duì)模型的過(guò)分?jǐn)M合問(wèn)題是非常魯棒的����。
問(wèn):樸素貝葉斯沒(méi)有學(xué)習(xí)的過(guò)程,那么是否可以說(shuō)樸素貝葉斯是消極學(xué)習(xí)法分類���?
答:(1)樸素貝葉斯只是貝葉斯分類的一種實(shí)現(xiàn)形式����,而實(shí)現(xiàn)形式還有貝葉斯網(wǎng)絡(luò)但是貝葉斯網(wǎng)絡(luò)是有學(xué)習(xí)過(guò)程的��。所以不能說(shuō)貝葉斯分類時(shí)消極學(xué)習(xí)法�����。(2)其實(shí)樸素貝葉斯是消極學(xué)習(xí)方法
1.4���、人工神經(jīng)網(wǎng)絡(luò)(ANN)
ANN是有相互連接的結(jié)點(diǎn)和有項(xiàng)鏈構(gòu)成�。
(1)感知器�����。感知器的一般模型如下所示:
分類思想:Ij = Sum(Wi*Oi) + a�����,其中Ij為特定的類標(biāo)號(hào),Wi為輸入向量的權(quán)重,Oi為輸入屬性的值,a為偏置因子���。用這個(gè)模型就可以對(duì)未知的記錄分類�����。圖中的激活函數(shù)的用處是:將某個(gè)Ij的計(jì)算值映射到相應(yīng)的類標(biāo)號(hào)中。在訓(xùn)練一個(gè)感知器時(shí)����,最初將所有的權(quán)重隨機(jī)取值,而訓(xùn)練一個(gè)感知器模型就相當(dāng)于不斷的調(diào)整鏈的權(quán)值����,直到能擬合訓(xùn)練數(shù)據(jù)的輸入輸出關(guān)系為止。其中權(quán)值更新公式如下:Wj(k+1) = Wjk + r(yi – yik)Xij��。其中Wk是第k次循環(huán)后第i個(gè)輸入鏈上的權(quán)值�����,參數(shù)r稱為學(xué)習(xí)率����,Xij是訓(xùn)練樣例的Xi的第j個(gè)屬性值�。學(xué)習(xí)率值在0到1之間����,可以用來(lái)控制每次循環(huán)時(shí)的調(diào)整量。自適應(yīng)r值:r在前幾次循環(huán)時(shí)值相對(duì)較大���,而在接下來(lái)的循環(huán)中逐漸減少�。
(2)多層人工神經(jīng)網(wǎng)絡(luò)
一個(gè)多層人工神經(jīng)網(wǎng)絡(luò)的示意圖如下兩圖所示:其中左邊是多類標(biāo)號(hào)情況����,右邊是一類情況。
ANN學(xué)習(xí)中的設(shè)計(jì)問(wèn)題:(1)確定輸入層的結(jié)點(diǎn)數(shù)目(2)確定輸出層的結(jié)點(diǎn)數(shù)目(3)選擇網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)(4)初始化權(quán)值和偏置(隨機(jī)值)(5)去掉有遺漏的訓(xùn)練樣例��,或者用最合理的值來(lái)代替�����。
ANN的特點(diǎn):
(1)至少含有一個(gè)隱藏層的多層神經(jīng)網(wǎng)絡(luò)是一種普適近似�����,即可以用來(lái)近似任何目標(biāo)函數(shù)���。(2)ANN可以處理冗余特征�����,因?yàn)闄?quán)值在訓(xùn)練過(guò)程中自動(dòng)學(xué)習(xí)�。冗余特征的權(quán)值非常小。(3)神經(jīng)網(wǎng)絡(luò)對(duì)訓(xùn)練數(shù)據(jù)中的噪聲非常敏感����。噪聲問(wèn)題的一種方法是使用確認(rèn)集來(lái)確定模型的泛化誤差;另一種方法是每次迭代把權(quán)值減少一個(gè)因子�����。(4)ANN權(quán)值學(xué)習(xí)使用的梯度下降方法經(jīng)常會(huì)收斂到局部最小值�。避免方法是在權(quán)值更新公式中加上一個(gè)自動(dòng)量�����。
1.5�����、支持向量機(jī)(SVM)
它可以很好的應(yīng)用于高維數(shù)據(jù)��,避免了維災(zāi)難問(wèn)題,它使用訓(xùn)練實(shí)例的一個(gè)子集來(lái)表示決策邊界��,該子集稱作支持向量����。SVM尋找具有最大邊緣的超平面(比那些較小的決策邊界具有更好的泛化誤差),因此也經(jīng)常稱為最大邊緣分類器���。最大邊緣的決策邊界如韓佳偉書(shū)P220圖6-21所示:分類思想(1)在線性可分的情況下就是要學(xué)習(xí)(找)到這個(gè)最大邊緣的決策邊界(通過(guò)線性規(guī)劃或拉格朗日乘子來(lái)求得)�,當(dāng)然也允許有一定的誤差(可以有少量的結(jié)點(diǎn)分在了它不該在的類����,但只要在能夠容忍的范圍就行),然后利用這個(gè)最大邊緣的決策邊界來(lái)分類���,結(jié)果落在一邊的為一類��,在另一邊的為另一類(2)在線性不可分的情況下����,將原來(lái)的數(shù)據(jù)從原先的坐標(biāo)空間X轉(zhuǎn)換到一個(gè)新的坐標(biāo)空間中�����,從而可以在變換后的坐標(biāo)空間中使用一個(gè)線性的決策邊界來(lái)劃分樣本的類標(biāo)號(hào)(主要技術(shù)包括:非線性變換、核技術(shù)和Mercer定理)�����。
SVM的特點(diǎn):
(1)SVM學(xué)習(xí)問(wèn)題可以表示為凸優(yōu)化問(wèn)題���,因此可以利用已知的有效算法發(fā)現(xiàn)目標(biāo)函數(shù)的全局最小值(2)通過(guò)對(duì)數(shù)據(jù)中每個(gè)分類屬性值引入一個(gè)啞變量����,SVM可以應(yīng)用于分類數(shù)據(jù)
1.6�����、組合方法
該方法聚集多個(gè)分類器的預(yù)測(cè)來(lái)提高分類的準(zhǔn)確率��,這些技術(shù)稱為組合或分類器組合方法��。組合方法由訓(xùn)練數(shù)據(jù)構(gòu)建一組基分類器�,然后通過(guò)對(duì)每個(gè)分類器的預(yù)測(cè)進(jìn)行投票來(lái)進(jìn)行分類��。預(yù)測(cè)過(guò)程如下所示:
由上面的分類過(guò)程可以看出當(dāng)誤差率大于0.5時(shí)�����,組合分類器的性能比基分類器更差。組合分類器的性能優(yōu)于單個(gè)分類器必須滿足兩個(gè)必要條件:(1)基分類器之間應(yīng)該是相互獨(dú)立的(輕微相關(guān)也行)�����;(2)基分類器應(yīng)當(dāng)好于隨機(jī)猜測(cè)分類器���。
構(gòu)建組合分類器的方法
(1)通過(guò)處理訓(xùn)練數(shù)據(jù)集�。根據(jù)某種抽樣分布�����,通過(guò)對(duì)原始數(shù)據(jù)進(jìn)行再抽樣來(lái)得到多個(gè)訓(xùn)練集(如有放回隨機(jī)抽樣)��。一般得到的訓(xùn)練集和原始數(shù)據(jù)集一樣大����。然后使用特定的學(xué)習(xí)算法為每個(gè)訓(xùn)練集建立一個(gè)分類器(裝袋和提升是兩種處理訓(xùn)練集的組合方法)。(2)通過(guò)處理輸入特征�����。通過(guò)選擇輸入特征的子集來(lái)形成每個(gè)訓(xùn)練集�。對(duì)那些含有大量冗余特征的數(shù)據(jù)集,這種方法的性能非常好(隨機(jī)深林就是一種處理輸入特征的組合方法,它使用決策樹(shù)作為基分類器)���。(3)通過(guò)處理類標(biāo)號(hào)�。這種方法適用于類數(shù)足夠多的情況���。這種方法先將所有的類劃分為兩個(gè)大類���,然后將兩個(gè)大類的每個(gè)大類劃分為兩個(gè)次大類……,預(yù)測(cè)時(shí)按照前面的分類遇到一個(gè)分類結(jié)點(diǎn)得一票�,最后得票數(shù)最多的那個(gè)就是最終的類。(4)通過(guò)處理學(xué)習(xí)算法����。如果在同一個(gè)訓(xùn)練集上用同一個(gè)學(xué)習(xí)算法得到的分類器模型不一樣,就可以多做幾次以建立多個(gè)基分類器�����。
組合方法對(duì)于不穩(wěn)定的分類器效果很好��。不穩(wěn)定分類器是對(duì)訓(xùn)練數(shù)據(jù)集微小的變化都很面干的基分類器�����。不穩(wěn)定分類器的例子包括決策樹(shù)�、基于規(guī)則的分類器和人工神經(jīng)網(wǎng)絡(luò)。
(1)裝袋�。裝袋又稱自助聚集,是一種根據(jù)均勻分布從數(shù)據(jù)集中重復(fù)抽樣的(有放回的)技術(shù)�����。每個(gè)自助樣本集都和原始數(shù)據(jù)一樣大����。然后對(duì)每個(gè)樣本集訓(xùn)練一個(gè)基分類器,訓(xùn)練k個(gè)分類器后����,測(cè)試樣本被指派到得票最高的類。用于噪聲數(shù)據(jù)���,裝袋不太受過(guò)分?jǐn)M合的影響��。
(2)提升���。是一個(gè)迭代過(guò)程,用來(lái)自適應(yīng)地改變樣本的分布�����,使得基分類器聚焦在那些很難分的樣本上。例如開(kāi)始時(shí)所有的樣本都賦予相同的權(quán)值1/N, 然后按這個(gè)概率抽取樣本集�����,然后得到一個(gè)分類器��,并用它對(duì)原始數(shù)據(jù)集中的所有樣本進(jìn)行分類�����。每一輪結(jié)束時(shí)更新樣本的權(quán)值���。增加錯(cuò)誤分類的樣本的權(quán)值�,減少被正確分類的樣本的權(quán)值�����,這迫使分類器在隨后的迭代中關(guān)注那些很難分類的樣本��。通過(guò)聚集每一輪得到的分類器��,就得到最終的分類器�����。目前有幾個(gè)提升算法的實(shí)現(xiàn)����,它們的差別在于:(1)每輪提升結(jié)束時(shí)如何更新訓(xùn)練樣本的權(quán)值;(2)如何組合每個(gè)分類器的預(yù)測(cè)����。
Android:在該算法中,基分類器Ci的重要性依賴于它的錯(cuò)誤率��。算法思想:首先初始化N個(gè)樣本的權(quán)值(w = 1/N)����,然后對(duì)于第i次(總共k次,產(chǎn)生k個(gè)基分類器)提升(其他次一樣)���,根據(jù)w通過(guò)對(duì)D進(jìn)行有放回抽樣得到訓(xùn)練集Di,然后根據(jù)Di得到一個(gè)基分類器Ci,用Ci對(duì)訓(xùn)練集D中的樣本進(jìn)行分類��。然后計(jì)算分類的加權(quán)誤差�,如果加權(quán)誤差大于0.5��,就將所有樣本的權(quán)值重設(shè)為為1/N���,否則用ai更新每個(gè)樣本的權(quán)值�����。得到k個(gè)基分類器后����,然后合并k個(gè)基分類器得到預(yù)測(cè)結(jié)果。Android 算法將每一個(gè)分類器Cj的預(yù)測(cè)值根據(jù) aj進(jìn)行加權(quán)����,而不是使用多數(shù)表決的方案。這種機(jī)制允許Android 懲罰那些準(zhǔn)確率很差的模型����,如那些在較早的提升輪產(chǎn)生的模型。另外���,如果任何中間輪產(chǎn)生高于50%的誤差�����,則權(quán)值將被恢復(fù)為開(kāi)始的一致值wi = 1/N����,并重新進(jìn)行抽樣。Android 算法傾向于那些被錯(cuò)誤分類的樣本���,提升技術(shù)很容易受過(guò)分?jǐn)M合的影響���。
(3)隨機(jī)森林���。它是一類專門(mén)為決策樹(shù)分類器設(shè)計(jì)的組合方法�。它結(jié)合多顆決策樹(shù)做出預(yù)測(cè)���。與Android算法使用的自適應(yīng)方法不同�,Android中概率分布是變化的����,以關(guān)注難分類的樣本,而隨機(jī)森林則采用一個(gè)固定的概率分布來(lái)產(chǎn)生隨機(jī)向量�。隨機(jī)森林與裝袋不同之處在于(1)裝袋可以用任何分類算法產(chǎn)生基分類器而隨機(jī)森林只能用決策樹(shù)產(chǎn)生基分類器。(2)裝袋最后組合基分類器時(shí)用的投票方法二隨機(jī)森林不一定用投票����。(3)隨機(jī)森林的每個(gè)基分類器是一個(gè)樣本集的隨機(jī)向量而裝袋是用的有放回抽樣來(lái)產(chǎn)生樣本。隨機(jī)森林的的決策樹(shù)在選擇分類屬性時(shí)�,隨機(jī)選擇F個(gè)輸入特征(而不是考察所有可用的特征)來(lái)對(duì)決策樹(shù)的節(jié)點(diǎn)進(jìn)行分裂��,然后樹(shù)完全增長(zhǎng)而不進(jìn)行任何剪枝��,最后用多數(shù)表決的方法來(lái)組合預(yù)測(cè)(這種方法叫Forest-RI��,其中RI是指隨機(jī)輸入選擇)�����。注意此時(shí)如果F太小�����,樹(shù)之間的相關(guān)度就減弱了�,F(xiàn)太大樹(shù)分類器的強(qiáng)度增加�,折中通常F取log2d + 1,其中d是輸入特征數(shù)����。如果d太小,可以創(chuàng)建輸入特征的線性組合��,在每個(gè)節(jié)點(diǎn)�����,產(chǎn)生F個(gè)這種隨機(jī)組合的新特征,并從中選擇最好的來(lái)分裂節(jié)點(diǎn)�����,這種方法稱為Forest-RC�����。隨機(jī)森林的分類準(zhǔn)確率和Android差不多�,但是隨機(jī)森林對(duì)噪聲更加魯棒�����,運(yùn)行速度也快得多�。
1.6、不平衡類問(wèn)題
有時(shí)候需要準(zhǔn)確分類訓(xùn)練集中的少數(shù)類而對(duì)多數(shù)類不是太關(guān)心�。如不合格產(chǎn)品對(duì)合格產(chǎn)品。但是這樣建立的模型同時(shí)也容易受訓(xùn)練數(shù)據(jù)中噪聲的影響����。
新定的指標(biāo)(過(guò)去的指標(biāo)不頂用如:準(zhǔn)確率不頂用):真正率(靈敏度)、真負(fù)率(特指度)��、假正率��、假負(fù)率、召回率��、精度�����。
(1)接受者操作特征(ROC)曲線����。該曲線是顯示分類器真正率和假正率之間的折中的一種圖形化方法。在一個(gè)ROC曲線中�,真正率沿y軸繪制,而假正率沿x軸繪制���。一個(gè)好的分類模型應(yīng)該盡可能靠近圖的左上角�。隨機(jī)預(yù)測(cè)分類器的ROC曲線總是位于主對(duì)角線上���。
ROC曲線下方的面積(AUC)提供了評(píng)價(jià)模型的平均性能的另一種方法�����。如果模型是完美的���,則它在ROC曲線下方的面積等于1���,如果模型僅僅是簡(jiǎn)單地隨機(jī)猜測(cè),則ROC曲線下方的面積等于0.5��。如果一個(gè)模型好于另一個(gè)���,則它的ROC曲線下方的面積較大��。為了繪制ROC曲線�����,分類器應(yīng)當(dāng)能夠產(chǎn)生可以用來(lái)評(píng)價(jià)它的預(yù)測(cè)的連續(xù)值輸出�,從最有可能分為正類的記錄到最不可能的記錄����。這些輸出可能對(duì)應(yīng)于貝葉斯分類器產(chǎn)生的后驗(yàn)概率或人工神經(jīng)網(wǎng)絡(luò)產(chǎn)生的數(shù)值輸出����。(繪制ROC曲線從左下角開(kāi)始到右上角結(jié)束,繪制過(guò)程見(jiàn)hanjiawei P243)�。
(2)代價(jià)敏感學(xué)習(xí)。代價(jià)矩陣對(duì)將一個(gè)類的記錄分類到另一個(gè)類的懲罰進(jìn)行編碼。代價(jià)矩陣中的一個(gè)負(fù)項(xiàng)表示對(duì)正確分類的獎(jiǎng)勵(lì)�����。算法思想:將稀有的類標(biāo)號(hào)預(yù)測(cè)錯(cuò)誤的代價(jià)權(quán)值設(shè)為很大�����,則在計(jì)算總代價(jià)時(shí)��,它的權(quán)值較高���,所以如果分類錯(cuò)誤的話�,代價(jià)就較高了����。代價(jià)敏感度技術(shù)在構(gòu)建模型的過(guò)程中考慮代價(jià)矩陣,并產(chǎn)生代價(jià)最低的模型���。例如:如果假負(fù)錯(cuò)誤代價(jià)最高���,則學(xué)習(xí)算法通過(guò)向父類擴(kuò)展它的決策邊界來(lái)減少這些錯(cuò)誤。
(2)代價(jià)敏感學(xué)習(xí). 主要思想:改變實(shí)例的分布�,而使得稀有類在訓(xùn)練數(shù)據(jù)集得到很好的表示��。有兩種抽樣方法:第一種選擇正類樣本的數(shù)目和稀有樣本的數(shù)目一樣多����,來(lái)進(jìn)行訓(xùn)練(可以進(jìn)行多次�,每次選擇不同的正類樣本)。第二種復(fù)制稀有樣本(或者在已有的稀有樣本的鄰域中產(chǎn)生新的樣本)使得和正類樣本一樣多����。注意,第二種方法對(duì)于噪聲數(shù)據(jù)可能導(dǎo)致模型過(guò)分?jǐn)M合��。
1.6��、多類問(wèn)題(結(jié)果類標(biāo)號(hào)不止兩個(gè)
解決方法:(1)將多類問(wèn)題分解成K個(gè)二類問(wèn)題��。為每一個(gè)類yi Y(所有的類標(biāo)號(hào)集合)創(chuàng)建一個(gè)二類問(wèn)題���,其中所有屬于yi的樣本都被看做正類�,而其他樣本都被看做負(fù)類���。然后構(gòu)建一個(gè)二元分類器,將屬于yi的樣本從其他的類中分離出來(lái)�����。(稱為一對(duì)其他(1-r)方法)。(2)構(gòu)建K(K-1)/2個(gè)二類分類器��,每一個(gè)分類器用來(lái)區(qū)分一對(duì)類(yi����,yj)。當(dāng)為類(yi���,yj)構(gòu)建二類分類器時(shí)�����,不屬于yi或yj的樣本被忽略掉(稱為一對(duì)一(1-1)方法)����。這兩種方法都是通過(guò)組合所有的二元分類器的預(yù)測(cè)對(duì)檢驗(yàn)實(shí)例分類��。組合預(yù)測(cè)的典型做法是使用投票表決�����,將驗(yàn)證樣本指派到得票最多的類��。
糾錯(cuò)輸出編碼(ECOC):前面介紹的兩種處理多類問(wèn)題的方法對(duì)二元分類的錯(cuò)誤太敏感。ECOC提供了一種處理多類問(wèn)題更魯棒的方法�����。該方法受信息理論中通過(guò)噪聲信道發(fā)送信息的啟發(fā)�。基本思想是借助于代碼字向傳輸信息中增加一些冗余�����,從而使得接收方能發(fā)現(xiàn)接受信息中的一些錯(cuò)誤�,而且如果錯(cuò)誤量很少,還可能恢復(fù)原始信息�。具體:對(duì)于多類學(xué)習(xí),每個(gè)類yi用一個(gè)長(zhǎng)度為n的唯一位串來(lái)表示��,稱為它的代碼字���。然后訓(xùn)練n個(gè)二元分類器���,預(yù)測(cè)代碼子串的每個(gè)二進(jìn)制位。檢驗(yàn)實(shí)例的預(yù)測(cè)類由這樣的代碼字給出���。該代碼字到二元分類器產(chǎn)生的代碼字海明距離最近(兩個(gè)位串之間的海明距離是它們的不同的二進(jìn)制位的數(shù)目)�����。糾錯(cuò)碼的一個(gè)有趣的性質(zhì)是�����,如果任意代碼字對(duì)之間的最小海明距離為d��,則輸出代碼任意 (d-1) / 2個(gè)錯(cuò)誤可以使用離它最近的代碼字糾正����。注意:為通信任務(wù)設(shè)計(jì)的糾正碼明顯不同于多類學(xué)習(xí)的糾正嗎����。對(duì)通信任務(wù),代碼字應(yīng)該最大化各行之間的海明距離�����,使得糾錯(cuò)可以進(jìn)行�����。然而����,多類學(xué)習(xí)要求將代碼字列向和行向的距離很好的分開(kāi)�����。較大的列向距離可以確保二元分類器是相互獨(dú)立的����,而這正是組合學(xué)習(xí)算法的一個(gè)重要要求����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫(kù)�,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330