SPSS分析技術:非線性回歸;科學種田!肥料應該用多少合適
非線性回歸
非線性關系可以分為本質是線性關系的非線性關系和完全非線性關系,有點拗口�����。在曲線回歸總已經介紹,可以通過變量裝換�,轉化為線性關系,并進行線性回歸分析的就是本質是線性關系的非線性關系���。如果無法通過變量裝換���,轉化為線性關系,無法進行線性回歸分析的叫完全非線性關系��。今天我們介紹的非線性關系就是完全非線性關系的回歸分析���。
非線性回歸的優(yōu)勢
曲線估計只能用于一個自變量和因變量相關關系的模型的分析,而非線性回歸分析可以用來探討因變量和一組自變量之間的非線性相關模型��。非線性回歸可以估計因變量和自變量之間任意關系的模型��,可以根據自身需要隨意設定估計方程的具體形式�����。因此��,非線性回歸在實際應用中價值更大,應用范圍更廣���。
非線性回歸模型
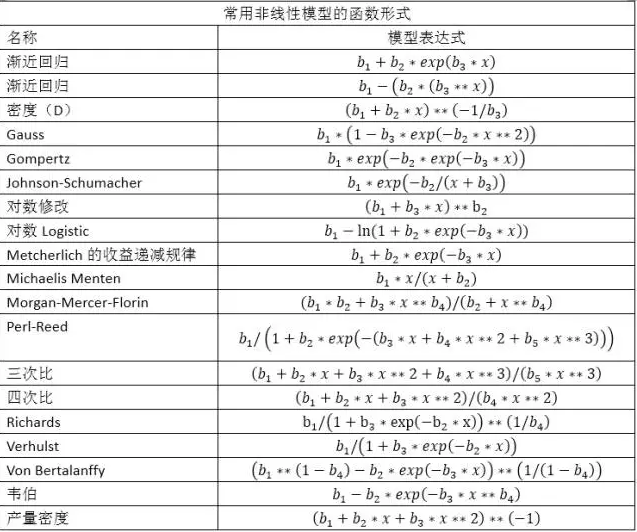
范例分析
某省農科院新培育了一種高產量農作物���,并在海南的試驗田中進行實驗種植,現有試驗田施肥量及其對應的農作物產量數據����,根據該數據文件推定施肥量與產量之間的關系。
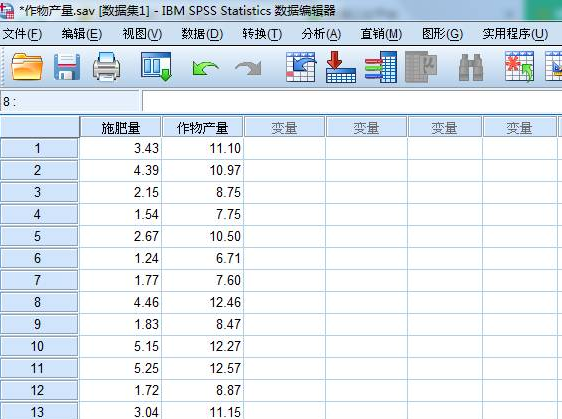
分析步驟
1�����、做散點圖�,觀察施肥量與農作物產量的關系;選擇菜單【圖形】-【舊對話框】-【散點/點狀】���,將施肥量選為自變量����,產量選為因變量��。
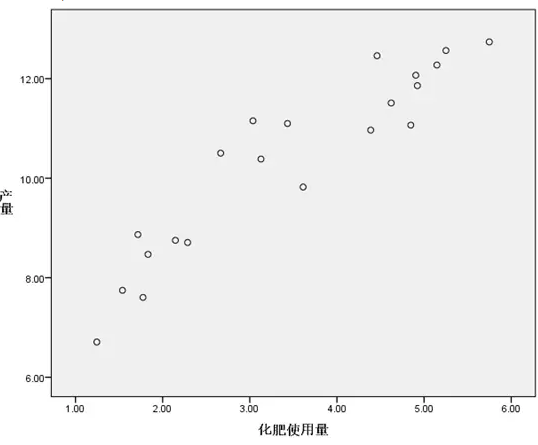
2��、 估計初始值;根據上圖���,施肥量和產量之間似乎存在線性關系��。但是根據實際經驗可知�����,這種推斷不正確��。因為作物產量不可能隨著施肥量的增加而一直增加下去,當產量達到一定水平時���,施肥量的增加不會帶來產量的進一步提高�����,二者的關系可以用漸進回歸模型:
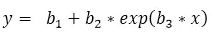
要確定回歸方程���,首要估算出參數b1�����、b2���、b3的初始值����。由散點圖看出�����,產量最大值接近13,不妨設b1=13���;x=0時,y=6���,故b2=6-13=-7;b3為散點圖中兩個分隔較寬的點之間的連線的斜率的倒數��,在此取b3=-1.5�。
3、參數設置��;選擇【分析】-【回歸】-【非線性】菜單��,打開非線性回歸對話框���。按照下圖輸入數據。
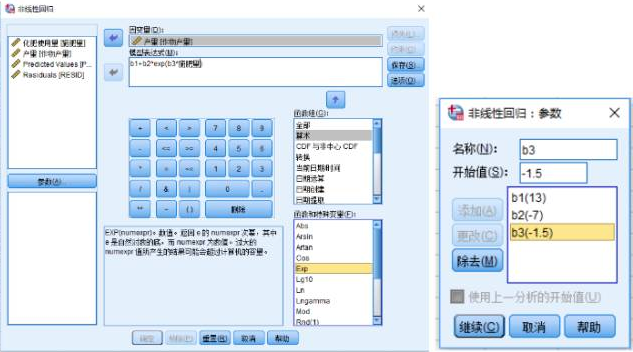
4、損失函數設置;單擊“損失”�����,設置損失函數。所謂損失函數是指一個包括當前工作文件中的變量以及所設定的參數并通過計算法使之最小化的函數。系統(tǒng)默認狀態(tài)下��,非線性回歸過程根據算法將殘差平方和最小化為損失函數�。如果選擇“用戶定義的損失函數”,可以再“用戶定義的損失函數”列表框中鍵入或者粘貼一個表達式���。字符串常數必須包含在引號或撇號中�����,數字常數必須按以美式格式鍵入�,并用句點作為小數分隔符�。本案例選擇系統(tǒng)默認設置。單擊“繼續(xù)”��。
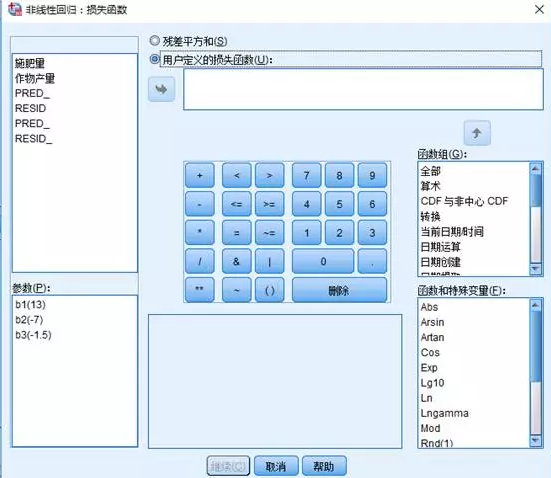
5�����、 參數約束設置�;單擊“約束,定義參數約束�。“約束”是在對解的迭代搜索過程中對參數所允許值的限制����。該對話框有兩個設置選項:“未約束”和“定義參數約束”。
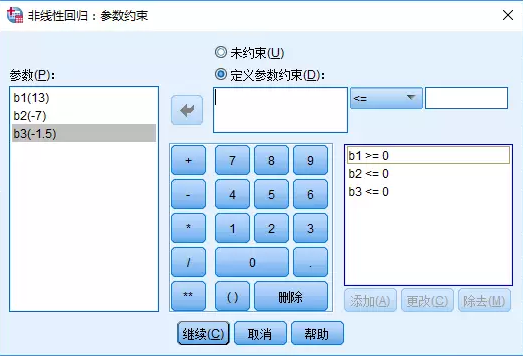
6、 保存設置��;單擊“保存”��,該對話框提供4種用于保存的數據類型�,允許作為新變量的觀測值保存于當前文件中。
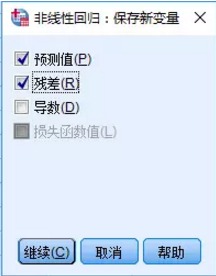
7�����、算法選項設置�;單擊“選項”,該對話框用于設置參數估計的算法和算法的迭代次數�、迭代步長和收斂條件等。
結果解釋
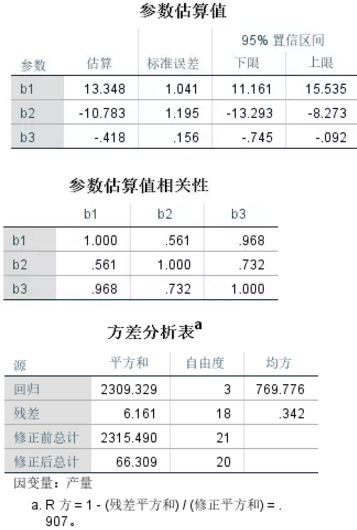
1�����、 如上圖所示�,該案例經過多大20步的迭代估計之后,找到模型的最優(yōu)解����,即 b1、b2��、b3的參數估計值13.348、-10.783和-0.418���,此外還得到了三個參數值的標準誤差和95%置信區(qū)間����,以及三個參數估計值的相關系數��,可以看出各個參數值之間的相關性很高�,尤其是b1和b3的相關系數達到0.968����,屬非常顯著的相關關系。
2��、 根據上表回歸模型的方差分析結果�,表中回歸行的平方和代表該回歸模型所能解釋的模型的方差變化,而殘差行的平方和代表該非線性回歸模型所不能解釋的方差變化����。二者的和即為未修正的總計,它是總的殘差平方和�,而R2=1-(殘差平方和)/(已更正的平方和)=0.907,說明該模型能解釋因變量90.7%的變異量��,即該非線性模型的擬合優(yōu)度很高。根據以上分析可以確定��,該分析所獲得的回歸模型顯著��。
根據線性回歸模型:
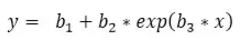
可得回歸方程:
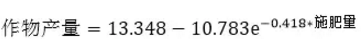
從散點圖可以知道�,目前采集到的數據還不足夠,因為圖中沒有出現明顯的平緩趨勢�。為了找到最合適的施肥量,可以通過得到的回歸方程�����,做出自變量(施肥量)范圍更廣的曲線�����,找出曲線的平緩位置��,這個位置對應的橫軸值就是合理的施肥量�����。數據分析培訓
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330