二分類模型中,如何應(yīng)對(duì)分類自變量取值過多
這是個(gè)信息無限充裕的年代�����,是個(gè)數(shù)據(jù)爆炸的年代��,也是數(shù)據(jù)過載的年代。大數(shù)據(jù)之大�����,不僅在于體量巨大�����,更在于結(jié)構(gòu)和內(nèi)容的復(fù)雜��,因此如何處理好數(shù)據(jù)一直是我們工作少為人知����、卻也無法忽視的重點(diǎn)。本期�����,我們就以二分類模型中自變量取值過載為例����,給大家講講應(yīng)對(duì)之道~
在二分類建模過程中,難免會(huì)遇到分類自變量取值過多的情況����,比如用來表示觀測(cè)值地域?qū)傩缘淖宰兞?����,在我?guó)即使選用省級(jí)層面的信息��,最多也可達(dá)31種取值��。處理分類自變量時(shí)�,最常用的方法是將其拆分為若干取值為“0”和”1”的二分變量�,這樣就會(huì)導(dǎo)致模型的維度過多,自由度降低����,不僅對(duì)建模樣本提出了更高的要求,還增加了模型參數(shù)估計(jì)的難度和模型的訓(xùn)練時(shí)間��。因此�����,今天我們基于自己的經(jīng)驗(yàn)��,在這里談?wù)剬?duì)這個(gè)問題的處理思路��。
一����、利用聚類算法進(jìn)行類別合并
既然這個(gè)問題是分類變量取值過多導(dǎo)致的,那么�,最直接的解決思路顯然就是對(duì)類別進(jìn)行合并。當(dāng)然��,合并不能是主觀隨意的�����,而應(yīng)該是基于定量分析之后的結(jié)果���。為了便于敘述��,不妨假設(shè)某個(gè)分類型自變量X有A1���,A2,…,An等取值�,我們可以計(jì)算出每個(gè)類別中實(shí)際的Y=1比例。具體計(jì)算過程如下表所示:
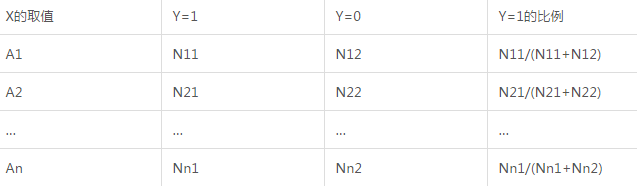
然后就可以利用聚類分析來進(jìn)行類別的合并了��。第一種思路是采用系統(tǒng)聚類法�,將A1,A2�,…,An看做聚類的對(duì)象����,各個(gè)類別的Y=1比例作為指標(biāo)進(jìn)行聚類����,即有n個(gè)聚類對(duì)象,1個(gè)聚類指標(biāo)���。聚類結(jié)束之后���,將聚為一類的類別進(jìn)行合并。當(dāng)然��,究竟聚為幾類最合適����,還可以采用一些指標(biāo)來輔助確定,比如SAS軟件中的R-square�、半偏態(tài)R-square以及偽F統(tǒng)計(jì)量等�,都可以用來輔助確定類的個(gè)數(shù)。
第二種思路就是采用有序樣品的聚類���,長(zhǎng)期關(guān)注我們公眾號(hào)的小伙伴可能還記得����,我們?cè)谇捌诘奈恼轮性?jīng)利用這個(gè)方法來進(jìn)行數(shù)據(jù)離散化,這里我們利用這個(gè)方法進(jìn)行類別的合并����,處理起來也比較簡(jiǎn)單,將各個(gè)類別按照Y=1比例從小到大的順序進(jìn)行排列���,再利用Fisher算法將Y=1比例相近的類別進(jìn)行合并�����。這樣做最大的好處是我們可以根據(jù)信息損失���,得到最優(yōu)的類別個(gè)數(shù)和相應(yīng)的最優(yōu)合并方法。
二�、利用決策樹進(jìn)行類別合并
利用決策樹進(jìn)行類別合并時(shí),首先需要選擇一個(gè)衡量分類變量之間相關(guān)性或影響程度的指標(biāo)�,我們可以使用在前期的文章中曾經(jīng)介紹過IV信息量或一致性比率。這種類別合并的基本步驟可以表示為:
1�、將各個(gè)類別按照Y=1比例從小到大的順序進(jìn)行排列,并將所有類別視為一個(gè)組����;
2�、利用IV信息量(或者一致性比率)���,找出最優(yōu)的二元分割方法��,使得被選中的分組方案是所有分組方案中預(yù)測(cè)能力最強(qiáng)的��,這樣將所有類別分成了兩組�,不妨假設(shè)為組1和組2��;
3�����、將組1按照上一步同樣的步驟分為組11和組12�����,組2分為組21和組22���。再利用IV信息量比較組1和組2的最優(yōu)分組的預(yù)測(cè)能力大小����,取預(yù)測(cè)能力最強(qiáng)的組進(jìn)行分裂����,這樣將所有類別分成了三組,不妨假設(shè)為組1�、組2和組3。
然后��,按照第3步的做法不斷分裂下去��,直到分裂形成的組數(shù)達(dá)到預(yù)先設(shè)定的個(gè)數(shù)為止��。如果因變量是二分變量��,可以使用IV信息量或一致性比率��;如果因變量的取值個(gè)數(shù)大于2�����,那么就可以使用一致性比率來進(jìn)行預(yù)測(cè)力的判斷�。《SAS編程與數(shù)據(jù)挖掘商業(yè)案例》一書種提供了一份觀測(cè)值為32264的數(shù)據(jù)集���,其中因變量是二分變量�,有一個(gè)分類自變量LOCATION有19種可能的取值,我們利用這里介紹的算法對(duì)變量LOCATION進(jìn)行合并����,將合并后的類別個(gè)數(shù)設(shè)定為5,下圖是分裂的具體過程:
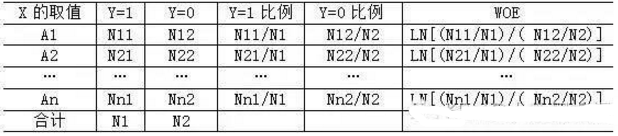
其中原始的19個(gè)變量記為B1����,B2,…�����,B19����,經(jīng)過4次分裂,19個(gè)取值最后被分為5個(gè)組�����,圓圈里面的表示的就是這5個(gè)組里面包括的原始變量名稱�����,每個(gè)方框下面對(duì)應(yīng)的數(shù)字表示該步分裂所對(duì)應(yīng)的順序����。由于采用的是自上而下的分裂算法���,很顯然��,分裂后保留的組數(shù)越多����,算法所耗費(fèi)的時(shí)間也就越長(zhǎng)。
三�、WOE編碼
WOE就是所謂的證據(jù)權(quán)重(weight of evidence),該方法計(jì)算出分類變量每一個(gè)類別的WOE值�,這樣就可以用這個(gè)WOE值組成的新變量來替代原來的分類變量。由于新變量是數(shù)值型變量�,因此該方法實(shí)際是將分類變量轉(zhuǎn)化為數(shù)值變量,不用再生成虛擬變量�����,避免了由此產(chǎn)生的維度過多的問題��。我們用下面的表格來表示W(wǎng)OE值的計(jì)算過程:
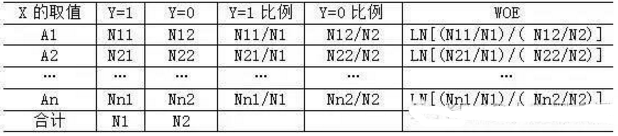
注:LN表示自然對(duì)數(shù)函數(shù)����。
從上表可以看出,WOE值實(shí)際上是該類別中Y=1與Y=0比例之比的自然對(duì)數(shù)。需要注意的是�����,該表的Y=1比例與上一張表的Y=1比例計(jì)算方式是不一樣的�����,上一張表的Y=1比例是該類別中Y=1觀測(cè)個(gè)數(shù)與該類別所有觀測(cè)個(gè)數(shù)之比��,而這一張表示該類別Y=1觀測(cè)個(gè)數(shù)與樣本中所有Y=1觀測(cè)個(gè)數(shù)之比�����。WOE編碼法在利用logistic模型建立信用評(píng)分卡時(shí)應(yīng)用較多��。
四�����、小結(jié)
比較而言���,前兩種類別合并的方法�����,雖然減少了類別個(gè)數(shù)�,但是仍然需要生成若干二分變量;當(dāng)使用一致性比率進(jìn)行預(yù)測(cè)力判斷時(shí)���,第二種方法也適用于多分類模型���;第三種方法將分類變量直接轉(zhuǎn)化為數(shù)值型變量�����,模型簡(jiǎn)潔�,易于操作。但是如果出現(xiàn)類別中Y=1或者Y=0個(gè)數(shù)為零的情況����,將導(dǎo)致WOE值無法計(jì)算。因此�����,也可以將兩種方法結(jié)合起來�����,先進(jìn)行簡(jiǎn)單的類別合并,避免Y=1或者Y=0個(gè)數(shù)為零的情況�,然后再進(jìn)行WOE編碼。
總之�,數(shù)據(jù)的世界是日益復(fù)雜的,大數(shù)據(jù)尤其如此���。在面對(duì)繁復(fù)的海量數(shù)據(jù)時(shí)���,我們需要很多方法和經(jīng)驗(yàn),將數(shù)據(jù)轉(zhuǎn)化成更簡(jiǎn)潔有效的信息����;希望大家能從本文中得到一點(diǎn)啟發(fā)。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試�����,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情����;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330