聚類(lèi)分析基礎(chǔ)知識(shí)總結(jié)及實(shí)戰(zhàn)解析
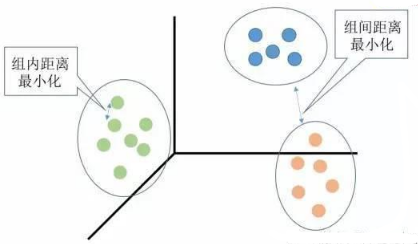
聚類(lèi)分析是沒(méi)有給定劃分類(lèi)別的情況下����,根據(jù)樣本相似度進(jìn)行樣本分組的一種方法,是一種非監(jiān)督的學(xué)習(xí)算法��。聚類(lèi)的輸入是一組未被標(biāo)記的樣本����,聚類(lèi)根據(jù)數(shù)據(jù)自身的距離或相似度劃分為若干組,劃分的原則是組內(nèi)距離最小化而組間距離最大化���,如下圖所示:
常見(jiàn)的聚類(lèi)分析算法如下:
-
K-Means: K-均值聚類(lèi)也稱為快速聚類(lèi)法��,在最小化誤差函數(shù)的基礎(chǔ)上將數(shù)據(jù)劃分為預(yù)定的類(lèi)數(shù)K�。該算法原理簡(jiǎn)單并便于處理大量數(shù)據(jù)。
-
K-中心點(diǎn):K-均值算法對(duì)孤立點(diǎn)的敏感性���,K-中心點(diǎn)算法不采用簇中對(duì)象的平均值作為簇中心�,而選用簇中離平均值最近的對(duì)象作為簇中心��。
-
系統(tǒng)聚類(lèi):也稱為層次聚類(lèi)�����,分類(lèi)的單位由高到低呈樹(shù)形結(jié)構(gòu)����,且所處的位置越低��,其所包含的對(duì)象就越少�����,但這些對(duì)象間的共同特征越多�。該聚類(lèi)方法只適合在小數(shù)據(jù)量的時(shí)候使用,數(shù)據(jù)量大的時(shí)候速度會(huì)非常慢�。
下面我們?cè)敿?xì)介紹K-Means聚類(lèi)算法�����。
K-Means聚類(lèi)算法
K-Means算法是典型的基于距離的非層次聚類(lèi)算法�����,在最小化誤差函數(shù)的基礎(chǔ)上將數(shù)據(jù)劃分為預(yù)定的類(lèi)數(shù)K����,采用距離作為相似性的評(píng)價(jià)指標(biāo)��,即認(rèn)為兩個(gè)對(duì)象的距離越近��,其相似度就越大�����。
算法實(shí)現(xiàn)
選擇K個(gè)點(diǎn)作為初始質(zhì)心
repeat
將每個(gè)點(diǎn)指派到最近的質(zhì)心�����,形成K個(gè)簇
重新計(jì)算每個(gè)簇的質(zhì)心
until 簇不發(fā)生變化或達(dá)到最大迭代次數(shù)
K如何確定
與層次聚類(lèi)結(jié)合�,經(jīng)常會(huì)產(chǎn)生較好的聚類(lèi)結(jié)果的一個(gè)有趣策略是,首先采用層次凝聚算法決定結(jié)果粗的數(shù)目���,并找到一個(gè)初始聚類(lèi)���,然后用迭代重定位來(lái)改進(jìn)該聚類(lèi)�����。
初始質(zhì)心的選取
常見(jiàn)的方法是隨機(jī)的選取初始質(zhì)心�,但是這樣簇的質(zhì)量常常很差���。
(1)多次運(yùn)行�����,每次使用一組不同的隨機(jī)初始質(zhì)心���,然后選取具有最小SSE(誤差的平方和)的簇集���。這種策略簡(jiǎn)單�����,但是效果可能不好����,這取決于數(shù)據(jù)集和尋找的簇的個(gè)數(shù)。
(2)取一個(gè)樣本�����,并使用層次聚類(lèi)技術(shù)對(duì)它聚類(lèi)��。從層次聚類(lèi)中提取K個(gè)簇�����,并用這些簇的質(zhì)心作為初始質(zhì)心�。該方法通常很有效,但僅對(duì)下列情況有效:樣本相對(duì)較?���。籏相對(duì)于樣本大小較小���。
(3)取所有點(diǎn)的質(zhì)心作為第一個(gè)點(diǎn)���。然后,對(duì)于每個(gè)后繼初始質(zhì)心��,選擇離已經(jīng)選取過(guò)的初始質(zhì)心最遠(yuǎn)的點(diǎn)。使用這種方法����,確保了選擇的初始質(zhì)心不僅是隨機(jī)的,而且是散開(kāi)的���。但是����,這種方法可能選中離群點(diǎn)��。
距離的度量
常用的距離度量方法包括:歐幾里得距離和余弦相似度�。歐幾里得距離度量會(huì)受指標(biāo)不同單位刻度的影響,所以一般需要先進(jìn)行標(biāo)準(zhǔn)化�����,同時(shí)距離越大���,個(gè)體間差異越大�;空間向量余弦?jiàn)A角的相似度度量不會(huì)受指標(biāo)刻度的影響�,余弦值落于區(qū)間[-1,1]�,值越大�����,差異越小��。
質(zhì)心的計(jì)算
對(duì)于距離度量不管是采用歐式距離還是采用余弦相似度����,簇的質(zhì)心都是其均值���。
算法停止條件
一般是目標(biāo)函數(shù)達(dá)到最優(yōu)或者達(dá)到最大的迭代次數(shù)即可終止����。對(duì)于不同的距離度量�,目標(biāo)函數(shù)往往不同。當(dāng)采用歐式距離時(shí)�����,目標(biāo)函數(shù)一般為最小化對(duì)象到其簇質(zhì)心的距離的平方和��;當(dāng)采用余弦相似度時(shí)��,目標(biāo)函數(shù)一般為最大化對(duì)象到其簇質(zhì)心的余弦相似度和。
空聚類(lèi)的處理
如果所有的點(diǎn)在指派步驟都未分配到某個(gè)簇���,就會(huì)得到空簇����。如果這種情況發(fā)生�,則需要某種策略來(lái)選擇一個(gè)替補(bǔ)質(zhì)心,否則的話���,平方誤差將會(huì)偏大�����。
(1)選擇一個(gè)距離當(dāng)前任何質(zhì)心最遠(yuǎn)的點(diǎn)�����。這將消除當(dāng)前對(duì)總平方誤差影響最大的點(diǎn)���。
(2)從具有最大SSE的簇中選擇一個(gè)替補(bǔ)的質(zhì)心,這將分裂簇并降低聚類(lèi)的總SSE���。如果有多個(gè)空簇��,則該過(guò)程重復(fù)多次�����。
適用范圍及缺陷
K-Menas算法試圖找到使平方誤差準(zhǔn)則函數(shù)最小的簇��。當(dāng)潛在的簇形狀是凸面的���,簇與簇之間區(qū)別較明顯,且簇大小相近時(shí)�����,其聚類(lèi)結(jié)果較理想�。對(duì)于處理大數(shù)據(jù)集合,該算法非常高效���,且伸縮性較好����。
但該算法除了要事先確定簇?cái)?shù)K和對(duì)初始聚類(lèi)中心敏感外����,經(jīng)常以局部最優(yōu)結(jié)束,同時(shí)對(duì)“噪聲”和孤立點(diǎn)敏感,并且該方法不適于發(fā)現(xiàn)非凸面形狀的簇或大小差別很大的簇�����。
克服缺點(diǎn)的方法:使用盡量多的數(shù)據(jù)����;使用中位數(shù)代替均值來(lái)克服outlier的問(wèn)題。
實(shí)例解析
>>> import pandas as pd
# 載入sklearn包自帶數(shù)據(jù)集
>>> from sklearn.datasets importload_iris
>>> iris = load_iris()
# 需要聚類(lèi)的數(shù)據(jù)150個(gè)樣本��,4個(gè)變量
>>> iris.data
>>> data = pd.DataFrame(iris.data)
# 數(shù)據(jù)標(biāo)準(zhǔn)化(z-score)
>>> data_zs = (data -data.mean())/data.std()
# 導(dǎo)入sklearn中的kmeans
>>> from sklearn.cluster importKMeans
# 設(shè)置類(lèi)數(shù)k
>>> k = 3
# 設(shè)置最大迭代次數(shù)
>>> iteration = 500
# 創(chuàng)建kmeans對(duì)象
>>> model = KMeans(n_clusters=k,n_jobs=4,max_iter=iteration)
# 使用數(shù)據(jù)訓(xùn)練訓(xùn)練model
>>> model.fit(data_zs)
# 每個(gè)類(lèi)別樣本個(gè)數(shù)
>>> pd.Series(model.labels_).value_counts()
# 每個(gè)類(lèi)別的聚類(lèi)中心
>>> pd.DataFrame(model.cluster_centers_)
下面我們用TSNE(高維數(shù)據(jù)可視化工具)對(duì)聚類(lèi)結(jié)果進(jìn)行可視化
>>> import matplotlib.pyplot asplt
>>> from sklearn.manifold importTSNE
>>> tsne = TSNE(learning_rate=100)
# 對(duì)數(shù)據(jù)進(jìn)行降維
>>> tsne.fit_transform(data_zs)
>>> data =pd.DataFrame(tsne.embedding_, index=data_zs.index)
# 不同類(lèi)別用不同顏色和樣式繪圖
>>> d = data[model.labels_==0]
>>> plt.plot(d[0],d[1],'r.')
>>> d = data[model.labels_==1]
>>> plt.plot(d[0],d[1],'go')
>>> d = data[model.labels_==2]
>>> plt.plot(d[0],d[1],'b*')
>>> plt.show()
聚類(lèi)效果圖如下:
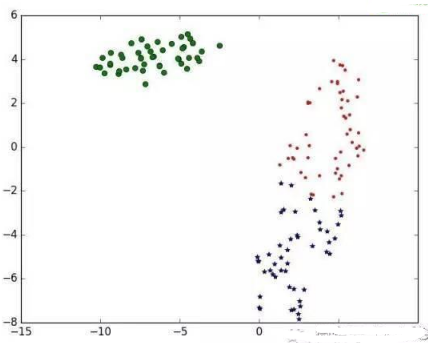
下面我們用PCA降維后���,對(duì)聚類(lèi)結(jié)果進(jìn)行可視化
>>> from sklearn.decompositionimport PCA
>>> pca = PCA()
>>> data =pca.fit_transform(data_zs)
>>> data = pd.DataFrame(data,index=data_zs.index)
>>> d = data[model.labels_==0]
>>> plt.plot(d[0],d[1],'r.')
>>> d = data[model.labels_==1]
>>> plt.plot(d[0],d[1],'go')
>>> d = data[model.labels_==2]
>>> plt.plot(d[0],d[1],'b*')
>>> plt.show()
聚類(lèi)效果圖如下:
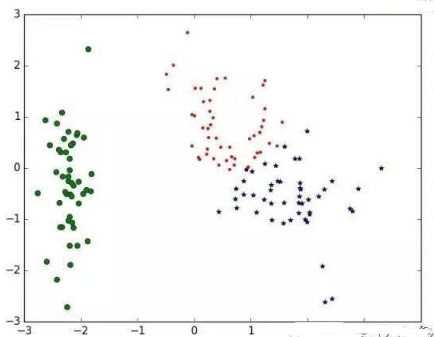
Python主要的聚類(lèi)分析算法總結(jié)
在scikit-learn中實(shí)現(xiàn)的聚類(lèi)算法主要包括K-Means����、層次聚類(lèi)����、FCM、神經(jīng)網(wǎng)絡(luò)聚類(lèi)�����,其主要相關(guān)函數(shù)如下:
KMeans: K均值聚類(lèi)�����;
AffinityPropagation: 吸引力傳播聚類(lèi),2007年提出�����,幾乎優(yōu)于所有其他方法����,不需要指定聚類(lèi)數(shù)K�,但運(yùn)行效率較低;
MeanShift:均值漂移聚類(lèi)算法�;
SpectralClustering:譜聚類(lèi),具有效果比KMeans好�����,速度比KMeans快等特點(diǎn)��;
5. AgglomerativeClustering:層次聚類(lèi)�����,給出一棵聚類(lèi)層次樹(shù)�����;
DBSCAN:具有噪音的基于密度的聚類(lèi)方法;
BIRCH:綜合的層次聚類(lèi)算法����,可以處理大規(guī)模數(shù)據(jù)的聚類(lèi)。
這些方法的使用大同小異�,基本都是先用對(duì)應(yīng)的函數(shù)建立模型,然后用fit()方法來(lái)訓(xùn)練模型�,訓(xùn)練好之后,就可以用labels_屬性得到樣本數(shù)據(jù)的標(biāo)簽��,或者用predict()方法預(yù)測(cè)新樣本的標(biāo)簽����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫(kù),點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情���;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330