分類-回歸樹模型(CART)在R語言中的實現
CART模型 ,即Classification And Regression Trees��。它和一般回歸分析類似���,是用來對變量進行解釋和預測的工具,也是數據挖掘中的一種常用算法���。如果因變量是連續(xù)數據��,相對應的分析稱為回歸樹�����,如果因變量是分類數據���,則相應的分析稱為分類樹。
決策樹是一種倒立的樹結構���,它由內部節(jié)點���、葉子節(jié)點和邊組成�����。其中最上面的一個節(jié)點叫根節(jié)點�����。 構造一棵決策樹需要一個訓練集����,一些例子組成�����,每個例子用一些屬性(或特征)和一個類別標記來描述��。構造決策樹的目的是找出屬性和類別間的關系�����,一旦這種關系找出���,就能用它來預測將來未知類別的記錄的類別���。這種具有預測功能的系統(tǒng)叫決策樹分類器。其算法的優(yōu)點在于:
1)可以生成可以理解的規(guī)則��。
2)計算量相對來說不是很大����。
3)可以處理多種數據類型。
4)決策樹可以清晰的顯示哪些變量較重要�。
下面以一個例子來講解如何在R語言中建立樹模型。為了預測身體的肥胖程度��,可以從身體的其它指標得到線索�,例如:腰圍、臀圍����、肘寬、膝寬�、年齡。
#首先載入所需軟件包
library(mboost)
library(rpart)
library(maptree)
#讀入樣本數據
data('bodyfat')
#建立公式
formular=DEXfat~age+waistcirc+hipcirc+elbowbreadth+kneebreadth
#用rpart命令構建樹模型���,結果存在fit變量中
fit=rpart(formula,method='avova',data=bodyfat)
#直接調用fit可以看到結果
n= 71
node), split, n, deviance, yval
* denotes terminal node
1) root 71 8535.98400 30.78282
2) waistcirc< 88.4 40 1315.35800 22.92375
4) hipcirc< 96.25 17 285.91370 18.20765 *
5) hipcirc>=96.25 23 371.86530 26.40957
10) waistcirc< 80.75 13 117.60710 24.13077 *
11) waistcirc>=80.75 10 98.99016 29.37200 *
3) waistcirc>=88.4 31 1562.16200 40.92355
6) hipcirc< 109.9 13 136.29600 35.27846 *
7) hipcirc>=109.9 18 712.39870 45.00056 *
#也可以用畫圖方式將結果表達得更清楚一些
draw.tree(fit)
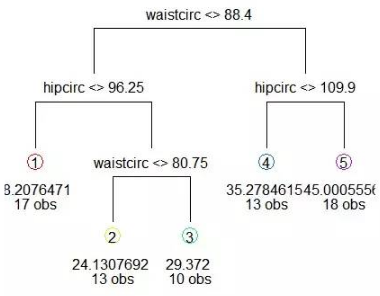
#建立樹模型要權衡兩方面問題����,一個是要擬合得使分組后的變異較小,另一個是要防止過度擬合�����,而使模型的誤差過大�,前者的參數是CP,后者的參數是Xerror�。所以要在Xerror最小的情況下,也使CP盡量小����。如果認為樹模型過于復雜,我們需要對其進行修剪
#首先觀察模型的誤差等數據
printcp(fit)
Regression tree:
rpart(formula = formula, data = bodyfat)
Variables actually used in tree construction:
[1] hipcirc waistcirc
Root node error: 8536/71 = 120.23
n= 71
CP nsplit rel error xerror xstd
1 0.662895 0 1.00000 1.01364 0.164726
2 0.083583 1 0.33710 0.41348 0.094585
3 0.077036 2 0.25352 0.42767 0.084572
4 0.018190 3 0.17649 0.31964 0.062635
5 0.010000 4 0.15830 0.28924 0.062949
#調用CP(complexity parameter)與xerror的相關圖��,一種方法是尋找最小xerror點所對應的CP值�,并由此CP值決定樹的大小,另一種方法是利用1SE方法���,尋找xerror+SE的最小點對應的CP值����。
plotcp(fit)
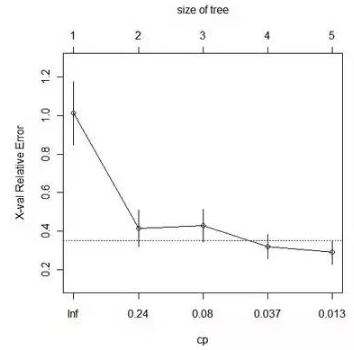
#用prune命令對樹模型進行修剪(本例的樹模型不復雜����,并不需要修剪)
pfit=prune(fit,cp= fit$cptable[which.min(fit$cptable[,"xerror"]),"CP"])
#模型初步解釋:腰圍和臀圍較大的人��,肥胖程度較高,而其中腰圍是最主要的因素�。
#利用模型預測某個人的肥胖程度
ndata=data.frame(waistcirc=99,hipcirc=110,elbowbreadth=6,kneebreadth=8,age=60)
predict(fit,newdata=ndata)
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學習CDA考試教材�����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量��,點擊>>> “CDA含金量” 了解CDA考試詳情�;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330