如何用R語言從網(wǎng)上讀取多樣格式數(shù)據(jù)
生活中��,我們面臨著各種各樣的數(shù)據(jù):比如你的成績單��,比如公司的財務報表,比如朋友圈的一些狀態(tài)��,比如微信里的一段語音……我們生活的大數(shù)據(jù)時代的一個重要特征便是數(shù)據(jù)的多樣化(variety)。
也許你期待的數(shù)據(jù)是這樣的:
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3.0 1.4 0.2 setosa
## 3 4.7 3.2 1.3 0.2 setosa
然而事實上我們面臨的數(shù)據(jù)確實這樣的:
@HWI-EAS121:4:100:1783:550#0/1
CGTTACGAGATCGGAAGAGCGGTTCAGCAGGAATGCCGAGACGGATCTCGTATGCGGTCTGCTGCGTGACAAGACAGGGG
+HWI-EAS121:4:100:1783:550#0/1
aaaaa`b_aa`aa`YaX]aZ`aZM^Z]YRa]YSG[[ZREQLHESDHNDDHNMEEDDMPENITKFLFEEDDDHEJQMEDDD
@HWI-EAS121:4:100:1783:1611#0/1
GGGTGGGCATTTCCACTCGCAGTATGGGTTGCCGCACGACAGGCAGCGGTCAGCCTGCGCTTTGGCCTGGCCTTCGGAAA
還有這樣的:
{
"uid": 10438,
"result": [
{
"day": "2011-12-12",
"followers_count": "63", //粉絲數(shù)
"v_followers_count": "18", //V粉絲數(shù)
"daren_followers_count": "18", //達人粉絲數(shù)
"friends_count": "58", //關注數(shù)
"v_friends_count": "58", //V關注數(shù)
"statuses_count": "258", //微博數(shù)
"bi_followers_count": "18", //互粉數(shù)
"repost_count": "115", //轉發(fā)數(shù)
"comments_count": "178", //評論數(shù)
},
...
]
}
那么我們如何去處理這些數(shù)據(jù)�����,我們如何分析這些數(shù)據(jù)�,從數(shù)據(jù)中找到我們想要的東西呢?我們將從如何將這些數(shù)據(jù)導入R中開始����,慢慢學習如何處理,分析我們身邊的大數(shù)據(jù)�。
第一章 數(shù)據(jù)的導入
面對各種各樣紛雜的數(shù)據(jù)��,我們分析的第一步便是獲取數(shù)據(jù)并將其導入R中��。
從網(wǎng)上獲取數(shù)據(jù)
大數(shù)據(jù)的一個重要數(shù)據(jù)源便是互聯(lián)網(wǎng)����。從網(wǎng)絡上獲取數(shù)據(jù)并用來分析是非常重要的。為了得到這些數(shù)據(jù)�����,一個普通青年的做法便是來到一個網(wǎng)站����,找到數(shù)據(jù)連接�����,然后右鍵->目標另存為,最后從本地文件夾中導入R�。但是如果要下載的數(shù)據(jù)文件數(shù)目比較多,再這么做就從一個普通青年降級為了二逼青年�����。
為了應對需要下載多個文件的情況��,R提供了函數(shù)download.file()�,使得R可以從互聯(lián)網(wǎng)上直接把數(shù)據(jù)拽下來。其調用格式為:
download.file(url, destfile, method, quiet = FALSE, mode = "w",
cacheOK = TRUE,
extra = getOption("download.file.extra"))
主要的參數(shù)為:
url:文件的所在地址
destfile:下載后文件的保存地址�,默認為工作目錄
method: 提供"internal", "wget", "curl" 和 "lynx"四種method,在windows上通常internal就能解決大多數(shù)的問題�����,少數(shù)搞不定的如Cygwin, gnuwin32這種的"wget"就可以搞定�����;windows的二進制文件用“curl”,這個method對于Mac的用戶來說是都要設置的��;“l(fā)ynx”主要針對historical interest���。
用法舉例:獲取上市公司資產(chǎn)負債表
比如說我們要獲取一系列的上市公司財務數(shù)據(jù)����,我們就要得到他們的資產(chǎn)負債表����。當然,如果花錢買wind數(shù)據(jù)庫�����,一切也就不用操心了�����。但是如果不在學校����,用不了數(shù)據(jù)庫的話,一個可以替代的辦法就是從新浪財經(jīng)里面拽數(shù)據(jù):以安信信托(600816) 資產(chǎn)負債表為例�,你可以訪問新浪財經(jīng)就能看個明白�,還可以下載���。我們如果還要其他的股票���,我們都可以如法炮制。那么我們通過R用download.file寫一個函數(shù)來實現(xiàn)輸入股票代碼����,將資產(chǎn)負債表下載到指定目錄:
getbalancesheets=function(symbol,file){pre="http://money.finance.sina.com.cn/corp/go.php/vDOWN_BalanceSheet/displaytype/4/stockid/";end="/ctrl/all.phtml";url=paste(pre,symbol,end,sep="");destfile=paste(file,"BalanceSheet_",symbol,".xls",sep="");
download.file(url,destfile);
}
值得注意的是:
凡是以http開頭的����,放心大膽的使用download.file()
凡是以https開頭的,這個函數(shù)可能失效
在設置路徑時可以通過file.exists來查看文件夾是否存在����,如果不存在可以使用dir.create來創(chuàng)建它,避免找不到路徑的煩惱����。
使用getwd獲取當前工作路徑,setwd可以改變它
讀入XML
XML可以說是我們非常熟悉的一類數(shù)據(jù)���。我們通常在網(wǎng)上看到的電子表格便是XML文件的一部分�����。我們可以看到XML文件大抵是長這樣的.

如何打開這樣的一個文件��?其實最簡單的就是用EXCEL表格打開了���,我們只要在打開文件時作為 XML 列表打開文件����。當打開 XML 源時��,Excel 會查找 XML 樣式表 (XSL) 的標記���。XSL 說明數(shù)據(jù)的顯示方式�����。如果存在相應的標記�����,Excel 將會提示您選擇是否應用樣式表����。如果選擇應用 XSL,則 XSL 將指示數(shù)據(jù)的顯示方式�。
關于XML這種可擴展性標記語言,我們不再贅述�,可以參閱wiki.這里我們關注的是在得到XML文件后如何分析處理。
R提供了XML包供我們來讀取這樣一個文件����。我們將XML包的主要函數(shù)介紹如下:
xmlTreeParse(file, ignoreBlanks=TRUE, handlers=NULL, replaceEntities=FALSE,
asText=FALSE, trim=TRUE, validate=FALSE, getDTD=TRUE,
isURL=FALSE, asTree = FALSE, addAttributeNamespaces = FALSE,
useInternalNodes = FALSE, isSchema = FALSE,
fullNamespaceInfo = FALSE, encoding = character(),
useDotNames = length(grep("^\\.", names(handlers))) > 0,
xinclude = TRUE, addFinalizer = TRUE, error = xmlErrorCumulator(),
isHTML = FALSE, options = integer(), parentFirst = FALSE)
xmlRoot(x, skip = TRUE, ...)
## S3 method for class 'XMLDocumentContent'
xmlRoot(x, skip = TRUE, ...)
## S3 method for class 'XMLInternalDocument'
xmlRoot(x, skip = TRUE, addFinalizer = NA, ...)
## S3 method for class 'HTMLDocument'
xmlRoot(x, skip = TRUE, ...)
xmlTreeParse函數(shù)主要是用于解析XML或HTML文件包含XML / HTML內容或字符串,并生成一個R代表XML / HTML樹結構。xmlRoot函數(shù)主要是用于提供方便地訪問由解析一個XML文檔產(chǎn)生的頂級XMLNode對象.
我們
下面就來一步一步的分析如何讀取一個XML或者HTML文件:
獲取網(wǎng)頁數(shù)據(jù)
這時你需要用到RCurl包的getURL函數(shù)來下載相關網(wǎng)頁����,我們以最近BBC上最火的Robin Williams的一則新聞為例說說怎樣讀取HTML文件(因為中文有些網(wǎng)站會出現(xiàn)亂碼,為了避免不必要的麻煩��,我們暫時使用英文網(wǎng)站�����,稍后的例子會有中文的):
library(RCurl)
library(XML)url<-"http://www.bbc.com/news/entertainment-arts-28761353"SOURCE<-getURL(url,encoding="UTF-8")#Download the page## Error: transfer closed with 78288 bytes remaining to read#this is a very very long line. Let's not print it. Instead:substring (SOURCE,1,200)## Error: 找不到對象'SOURCE'PARSED<-htmlParse(SOURCE)#Format the html code d## Error: 找不到對象'SOURCE'
獲取HTML的元素
我們可以通過XPath的相關函數(shù)來獲取HTML的相關信息:
xpathSApply(PARSED,"http://h1")## Error: 找不到對象'PARSED'
這樣的標題由于含有HTML標記��,讓我們很不爽�����,我們可以通過下面函數(shù)來去掉它:
xpathSApply(PARSED,"http://h1",xmlValue)## Error: 找不到對象'PARSED'
相應的函數(shù)調用格式如下:
xpathApply(doc, path, fun, ... ,
namespaces = xmlNamespaceDefinitions(doc, simplify = TRUE),
resolveNamespaces = TRUE, addFinalizer = NA)
xpathSApply(doc, path, fun = NULL, ... ,
namespaces = xmlNamespaceDefinitions(doc, simplify = TRUE),
resolveNamespaces = TRUE, simplify = TRUE, addFinalizer = NA)
主要參數(shù):
doc:XMLInternalDocument類型的數(shù)據(jù)��,htmlParse函數(shù)產(chǎn)生的對象
path:XPath 表達式��,常用的有 "/" 表示根節(jié)點處尋找;"http://"表示文檔任意處尋找;"@"表示選擇相應的屬性
我們可以通過抓取HTML里的關鍵詞來發(fā)現(xiàn)很多東西���,比如我們想知道這個頁面有多少條鏈接��,我們只需要運行:
length(xpathSApply(PARSED, "http://a/@href"))
再比如我們想要知道新聞的日期���,我們可以運行:
xpathSApply(PARSED, "http://span[@class='date']",xmlValue)
最后要說的是,你的挖掘一定要對HTML的結構十分的熟悉���,比如頁面有哪些元素�����,這是第幾級的結構等�,方便在使用@時確定能找到有關屬性���,比如說我想知道BBC報道了哪些最近的關于中國的新聞���,我們就可以運行以下代碼:
url="http://www.bbc.co.uk/search/news/?q=China&search_form=in-page-search-form"SOURCE<-getURL(url,encoding="UTF-8")PARSED<-htmlParse(SOURCE)targets<-unique(xpathSApply(PARSED,"http://a[@class='title linktrack-title']/@href"))
head(targets)## [1] "http://www.bbc.co.uk/news/world-europe-28755656"
## [2] "http://www.bbc.co.uk/news/business-28767854"
然而,對于上面那篇文章,"http://a[@class='title linktrack-title']/@href"是找不到任何東西的����。進一步地,對于每一個鏈接���,如果我們還想知道標題與日期��,我們可以使用sapply函數(shù):
bbcScraper2<-function(url){title=date=NA#Return empty values in case field not foundSOURCE<-getURL(url,encoding="UTF-8")PARSED<-htmlParse(SOURCE)title=(xpathSApply(PARSED,"http://h1[@class='story-header']",xmlValue))date=(xpathSApply(PARSED,"http://meta[@name='OriginalPublicationDate']/@content"))if(is.null(date)){date=(xpathSApply(PARSED,"http://span[@class='date']",xmlValue))
}return(c(title,as.character(date)))
}targets<-as.data.frame(targets)
t(sapply(targets[1:5,],bbcScraper2))## [,1]
## [1,] "Pope Francis faces greatest challenge yet in Asia"
## [2,] "Alibaba sells off loan business ahead of share sale"
## [3,] "Conservatives misguided after Ferguson shooting"
## [4,] "Q&A: Edinburgh's giant pandas"
## [5,] "In pictures: Framing Hope"
## [,2]
## [1,] "2014/08/13 01:51:58"
## [2,] "2014/08/13 01:18:39"
## [3,] "2014/08/12 17:05:25"
## [4,] "2014/08/12 16:00:21"
## [5,] "2014/08/12 14:55:21"
讀取網(wǎng)頁表格
很多網(wǎng)站并不提供直接的數(shù)據(jù)下載�,而是提供一個網(wǎng)頁表格供你在線觀看�����。那么我們有沒有簡單一點的辦法把他們拽下來呢�?readHTMLTable函數(shù)可以幫我們把東西輕而易舉的辦到,我們先來看看函數(shù)的調用格式:
readHTMLTable(doc, header = NA,
colClasses = NULL, skip.rows = integer(), trim = TRUE,
elFun = xmlValue, as.data.frame = TRUE, which = integer(),
...)
我們以保利地產(chǎn)的分紅情況為例來說明函數(shù)的使用:
url<-"http://money.finance.sina.com.cn/corp/go.php/vISSUE_ShareBonus/stockid/600048.phtml"data<-readHTMLTable(url,header=NA,which=19)data## V1 V2 V3 V4 V5 V6 V7 V8 V9
## 1 2014-05-16 0 5 2.94 瀹炴柦 2014-05-22 2014-05-21 -- 鏌ョ湅
## 2 2013-05-28 0 0 2.32 瀹炴柦 2013-06-03 2013-05-31 -- 鏌ョ湅
## 3 2012-06-12 0 2 2.15 瀹炴柦 2012-06-18 2012-06-15 -- 鏌ョ湅
## 4 2011-05-11 0 3 2.13 瀹炴柦 2011-05-17 2011-05-16 -- 鏌ョ湅
對于中文來說�����,出現(xiàn)了亂碼����,這是我們不希望看到的��,一個簡單地辦法就是將文件寫入一個txt文件,再重新讀取出來�,即:
write.table(data,"F:/table.txt")
read.table("F:/table.txt",encoding="UTF-8")## V1 V2 V3 V4 V5 V6 V7 V8 V9
## 1 2014-05-16 0 5 2.94 實施 2014-05-22 2014-05-21 -- 查看
## 2 2013-05-28 0 0 2.32 實施 2013-06-03 2013-05-31 -- 查看
## 3 2012-06-12 0 2 2.15 實施 2012-06-18 2012-06-15 -- 查看
## 4 2011-05-11 0 3 2.13 實施 2011-05-17 2011-05-16 -- 查看
看表格很完整的展現(xiàn)在我們面前了。
應用舉例:中超預測
雖然中國足球沒什么看點�,但是還是有一些槽點,對于買彩票的如果沒有假球的話還有一些競猜的價值�����。我們想要推斷首先就得從網(wǎng)上獲取相應數(shù)據(jù)����,我們還是用簡單的readHTMLTable函數(shù)從網(wǎng)易載入中超賽程數(shù)據(jù):
library(XML)CslData<-readHTMLTable("http://cs.sports.163.com/fixture/",header=T)CslPoint<-CslData[[31]]CslData[[31]]<-NULLCslFixture<-do.call(rbind, lapply(CslData,function(x) subset(x[,3:5])))
colnames(CslFixture)<-iconv(colnames(CslFixture),"UTF-8")
colnames(CslPoint)<-iconv(colnames(CslPoint),"UTF-8")
head(CslFixture)## 主隊 比分 客隊
## NULL.1 山東魯能 1 - 0 哈爾濱毅騰
## NULL.2 廣州恒大 3 - 0 河南建業(yè)
## NULL.3 北京國安 1 - 0 長春亞泰
## NULL.4 江蘇舜天 0 - 0 貴州茅臺
## NULL.5 杭州綠城 1 - 1 大連阿爾濱
## NULL.6 遼寧宏運 1 - 1 上海上港head(CslPoint)## 名次 球隊 比賽 積分
## 1 1 廣州恒大 20 45
## 2 2 北京國安 19 41
## 3 3 廣州富力 19 34
這樣我們就得到了中超的數(shù)據(jù),之后就可以利用我們之前在博客里講的MCMC��,logistic����,SVM之類的辦法去預測了。
這個例子節(jié)選自虎撲體育的《恒大奪冠100%�,卓爾降級99%——用R語言輕松模擬中超剩余比賽》,那篇帖子也給了一個簡單地預測辦法,雖然不見得準確�����,也可以為我們的預測提供一個思路���。
應用舉例:獲取當當網(wǎng)的圖書定價
在比價的過程中��,我們首要的任務就是從網(wǎng)上獲取價格數(shù)據(jù)���。我們該如何從當當?shù)膱D書頁面獲取價格數(shù)據(jù)呢���?
library(XML)
library(RCurl)book_price=NULLfor(iin1:2){url_i<-paste0("http://category.dangdang.com/pg",i,"-cp01.00.00.00.00.00.html",sep="")url_i<-htmlParse(url_i,encoding="GBK")#asText=TRUE,node_i<-getNodeSet(url_i,"http://li[@class]/div[@class=\"inner\"]/a")Attr_i<-sapply(node_i,xmlGetAttr,name="href")for(jinAttr_i){url_j=htmlParse(j,encoding="GBK")node_title=getNodeSet(url_j,"http://div[@class]/img[@id]")if(length(node_title)>0){title=xmlGetAttr(node_title[[1]],"alt")title=iconv(title,"UTF-8","gbk")
}else{next}node_price=getNodeSet(url_j,"http://span[@id=\"salePriceTag\"]")if(length(node_price)>0){price=as.numeric(xmlValue(node_price[[1]]))
}else{next}book_price=rbind(book_price,cbind(j,title,price))
}
}
colnames(book_price)=c("URL","書名","價格")
write.csv(book_price,"F:/book_price.csv")
讀入json 數(shù)據(jù)
json數(shù)據(jù)的一個典型的代表就是微博數(shù)據(jù),然而除了微博外也有很多其他的網(wǎng)站因為json采用完全獨立于語言的文本格式��,但是也使用了類似于C語言家族的習慣使JSON成為理想的數(shù)據(jù)交換語言被許多的API使用���。比如github的數(shù)據(jù)�����,Wikipedia article traffic statistics的數(shù)據(jù)也采用了json格式��。
我們以github的API數(shù)據(jù)為例��,下面是我的github的代碼倉庫部分數(shù)據(jù)的json格式信息����,完整版本在這里
{
"id": 20472818,
"name": "courses",
"full_name": "yujunbeta/courses",
"owner": {
"login": "yujunbeta",
"id": 7315956,
"avatar_url": "https://avatars.githubusercontent.com/u/7315956?v=2",
"gravatar_id": "e8569ebac320c9aed1764a7d693e5a87",
"url": "https://api.github.com/users/yujunbeta",
"html_url": "https://github.com/yujunbeta",
"followers_url": "https://api.github.com/users/yujunbeta/followers",
"following_url": "https://api.github.com/users/yujunbeta/following{/other_user}",
"gists_url": "https://api.github.com/users/yujunbeta/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yujunbeta/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yujunbeta/subscriptions",
"organizations_url": "https://api.github.com/users/yujunbeta/orgs",
"repos_url": "https://api.github.com/users/yujunbeta/repos",
"events_url": "https://api.github.com/users/yujunbeta/events{/privacy}",
"received_events_url": "https://api.github.com/users/yujunbeta/received_events",
"type": "User",
"site_admin": false
},
"private": false,
"html_url": "https://github.com/yujunbeta/courses",
"description": "Course materials for the Data Science Specialization: https://www.coursera.org/specialization/jhudatascience/1",
"fork": true,
"url": "https://api.github.com/repos/yujunbeta/courses",
"forks_url": "https://api.github.com/repos/yujunbeta/courses/forks",
"keys_url": "https://api.github.com/repos/yujunbeta/courses/keys{/key_id}",
R的jsonlite包提供了函數(shù)fromJSON來讀取JSON數(shù)據(jù)�。以我的github的JSON數(shù)據(jù)為例:
library(jsonlite)jsonData<-fromJSON("https://api.github.com/users/yujunbeta/repos")
我們可以通過操作jsonData來獲取我的github的相應信息:
names(jsonData)#獲取JSON數(shù)據(jù)的一級結構,類似于hush表的關鍵字## [1] "id" "name" "full_name"
## [4] "owner" "private" "html_url"
## [7] "description" "fork" "url"
## [10] "forks_url" "keys_url" "collaborators_url"
## [13] "teams_url" "hooks_url" "issue_events_url"
## [16] "events_url" "assignees_url" "branches_url" names(jsonData$owner)#獲取所有者的基本信息## [1] "login" "id" "avatar_url"
## [4] "gravatar_id" "url" "html_url"
## [7] "followers_url" "following_url" "gists_url" jsonData$owner$login#獲取登陸信息## [1] "yujunbeta" "yujunbeta" "yujunbeta" "yujunbeta" "yujunbeta"
## [6] "yujunbeta" "yujunbeta" "yujunbeta" "yujunbeta" "yujunbeta"
## [11] "yujunbeta" "yujunbeta" "yujunbeta" "yujunbeta" "yujunbeta"
## [16] "yujunbeta" "yujunbeta" "yujunbeta"
應用舉例:分析Wikipedia讀者搜索趨勢
在股票交易中我們經(jīng)常會聽到“概念股”這樣一個名詞�����,那么什么樣的概念最可能走紅��,什么樣的概念股最有可能獲得多數(shù)股民的購買呢��,當然就是被議論的最多的�,人們最關心的,比如習大大上臺時提的“美麗中國”在當時很是紅火�����,現(xiàn)在最近新聞里提及的“金融改革”估計也會成為新的股市寵兒�����。
我們這里使用Wikipedia article traffic statistics提供的數(shù)據(jù)來看看最近人們對某一概念的關注程度如何����。當然,要獲得人們關注什么���,什么概念在股市中最紅火�,靠wiki的搜索指數(shù)是遠遠不夠的,用下面的程序賺錢還是夠嗆����。
我們這里以最近比較紅火的數(shù)據(jù)科學這一概念為例,我們來看看人們對它的關注程度:
url<-"http://stats.grok.se/json/en/latest90/data%20science"raw.data<-readLines(url,warn="F")
library(rjson)rd<-fromJSON(raw.data)rd.views<-rd$daily_viewsrd.views<-unlist(rd.views)df<-as.data.frame(rd.views)
head(df)## rd.views
## 2014-06-30 620
## 2014-06-21 355
## 2014-06-20 474library(ggplot2)df$date<-as.Date(rownames(df))
colnames(df)<-c("views","date")
ggplot(df, aes(date,views))+geom_line()+geom_smooth()+theme_bw(base_size=20)
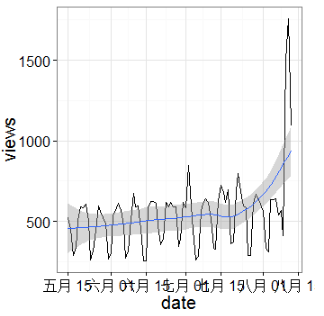
從圖中我們可以看到data science最近真的是紅火的不行����,然而我們再來看看相關的statistic被人們關注的程度如何?
## rd.views
## 2014-06-30 288
## 2014-06-21 212
## 2014-06-20 233
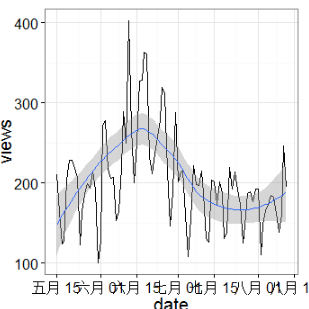
顯然statistic被人關注的程度真是少的可憐���。類似的我們還可以看看big data���,machine learning,statistical learning這些相近的詞匯的關注度���,這里我們不在贅述����。
應用舉例:《后會無期》能統(tǒng)計什么?
曾經(jīng)見過網(wǎng)上一個有意思的評論:我們可以通過統(tǒng)計觀看《小時代》的人數(shù)來統(tǒng)計究竟有多少腦殘�。當然,這只是一家之言�。但是我們仍然可以利用關聯(lián)規(guī)則的思想:如果”小時代“的狀態(tài)里出現(xiàn)”腦殘“的概率很高,那么就基本上可以相信那條評論很有道理�����。
為了避免一些不必要的爭端���,我們不妨利用微博數(shù)據(jù)來看看國民岳父的《后會無期》究竟與什么相關���,觀影人數(shù)又能代表什么?
這里我們利用lijian大神的Rweibo包來看看:
require(Rweibo)res<-web.search.content("后會無期",page=20,sleepmean=10,sleepsd=1)$Weiborequire(Rwordseg)
insertWords("后會無期")n<-length(res)res<-res[res!=""]words<-unlist(lapply(X=res,FUN=segmentCN))word<-lapply(X=words,FUN=strsplit,"")wordfreq<-table(unlist(word))wordfreq<-sort(wordfreq,decreasing=TRUE)
現(xiàn)在我們來看看去掉一些單字詞匯(如“你”���,“是”之類)后的詞匯頻率超過20的大概有:
TFBOYS 房間 今天 電影 偶像 手記 臺灣 后會無期 遙控 大家 年輕
64 39 33 32 32 32 32 28 26 24 24
從著些關聯(lián)詞匯來看����,國民岳父的《后會無期》正在被最近風頭正勁的TFBOYS演唱的《后會無期》取代�,TFBOYS的《后會無期》成了新的熱門。不過畢竟后會無期已經(jīng)上演了那么長的時間����,沒有人會去溫習那些經(jīng)典的“道理”,因為大家都知道:無論你知道多少道理��,仍有可能過不好這一生����。那么目前跟電影《后會無期》相關的東西可以肯定的就只有”電影“本身以及電影9月的”臺灣“之行��。
我們不僅可以讀入JSON數(shù)據(jù)也可以通過函數(shù)toJSON將數(shù)據(jù)框寫為JSON格式�,例如將鳶尾花數(shù)據(jù)集寫為JSON格式(輸出結果較長���,在此從略):
data(iris)
toJSON(iris, pretty=TRUE)
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫�����,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330