小談關(guān)聯(lián)規(guī)則的指標(biāo)應(yīng)用
你對關(guān)聯(lián)規(guī)則知道多少呢�����?本文從概念和基本指標(biāo)說起��,向你介紹一些指標(biāo)應(yīng)用的方法���。
關(guān)聯(lián)規(guī)則是產(chǎn)品推薦中最常用的算法之一��,簡單地說��,就是通過客戶的歷史購買信息��,挖掘出客戶在所有產(chǎn)品間按照某種順序進(jìn)行選擇的可能性�����。然而,關(guān)聯(lián)規(guī)則中的常用度量指標(biāo)并不唯一�,三四個指標(biāo)相互聯(lián)系��,如何進(jìn)行合理的排列組合�����、找出值得向客戶推薦的產(chǎn)品呢�?我們將從簡化的實際場景跟大家探討一下究竟如何應(yīng)用這些指標(biāo)去做產(chǎn)品推薦����。
首先���,我們先來了解一下關(guān)聯(lián)規(guī)則中所涉及到的一些指標(biāo):
1. 產(chǎn)品的期望概率
產(chǎn)品期望概率就是對于任意一個客戶來說��,購買某一產(chǎn)品的可能性����。
如果我們現(xiàn)在有兩個產(chǎn)品A和B����,那么A、B的期望概率就是所有客戶中購買了產(chǎn)品A或者產(chǎn)品B的比例,也就是P(A)和P(B)�。
2. 產(chǎn)品的置信度和支持度
置信度是用來衡量客戶在選擇一個產(chǎn)品(即前項產(chǎn)品)后��,又選擇另一個產(chǎn)品(即后項產(chǎn)品)的可能性�����。比如,我們想知道有多少客戶選擇了A之后又選擇了B��,其實就是統(tǒng)計學(xué)中條件概率�,表達(dá)式為:
P(B|A)=P(A,B)/P(A)
分母中P(A,B)的意思為同時選擇A����、B的概率���,也就是關(guān)聯(lián)規(guī)則中的支持度��。從公式中����,我們可以看出,置信度就是支持度與產(chǎn)品A(前項產(chǎn)品)期望概率的比值�����。
3. 產(chǎn)品的提升度
那么�,是不是產(chǎn)品的置信度越高��,我們就越應(yīng)該給買了產(chǎn)品A的客戶推薦產(chǎn)品B呢�?
答案并非如此。舉個例子來說��,如果產(chǎn)品B是一個特別大眾的產(chǎn)品�����,幾乎所有客戶都會購買���,而產(chǎn)品A卻是一種小眾產(chǎn)品�����,只有一小撮人會購買���,那么����,置信度
P(B|A)=P(A,B)/P(A)
會無限接近于1���,相應(yīng)的支持度也會很高�����。也就是說�,雖然購買了產(chǎn)品B客戶客幾乎都會購買產(chǎn)品A�,但產(chǎn)品B的高購買率并非受益于產(chǎn)品A,不是因為客戶先購買了產(chǎn)品A帶來的提升�����。
所以���,為了測量先購買某一產(chǎn)品對另一產(chǎn)品購買度的提升比例�����,關(guān)聯(lián)規(guī)則中提出了提升度這一指標(biāo)�,表達(dá)式為置信度與后項產(chǎn)品期望概率的比值,即
P(B|A)/P(B)=P(A,B)/(P(A)*P(B))
只有當(dāng)提升度大于1���,才能說明購買過產(chǎn)品A的客戶比任意一個客戶有更高可能性去購買產(chǎn)品B��,才有推薦的必要性�。
通常在關(guān)聯(lián)規(guī)則中�����,我們會采用Apriori算法去計算以上指標(biāo)���,篇幅所限,具體算法就不再細(xì)說了����,感興趣的讀者可以尋找相關(guān)資料。下面就展示一個通過算法得到的規(guī)則表吧��,來看看業(yè)務(wù)中會用到的信息究竟長什么樣吧:
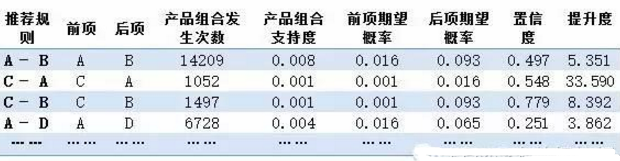
需要注意的是,在算法中我們已經(jīng)自行排除了一些出現(xiàn)概率較低的規(guī)則���,一般會將產(chǎn)品同時發(fā)生率和置信度根據(jù)數(shù)據(jù)本身的情況設(shè)定一個閾值�。
但是���,有了以上幾個指標(biāo)數(shù)據(jù)之后���,我們又要如何給客戶進(jìn)行產(chǎn)品推薦呢?實際應(yīng)用中����,我們可以從兩個方向出發(fā):
1. 以規(guī)則為導(dǎo)向
舉個例子,現(xiàn)在有一個客戶進(jìn)入店中����,我們通過歷史信息知道了他曾經(jīng)購買過何種產(chǎn)品,接下來我們要如何給他做推薦呢����?
以規(guī)則為導(dǎo)向的意思是說,通過篩選購買前項產(chǎn)品的客戶群��,來推薦其購買右邊的產(chǎn)品���。這里其實需要解決兩個問題��,一是客戶購買了多種產(chǎn)品���,那要針對哪一種種前項產(chǎn)品做推薦呢��?二是對于同一前項產(chǎn)品�,又該推薦何種后項產(chǎn)品呢?
解決這兩個問題也就是要解決兩個順序�,即前項產(chǎn)品的推薦排序和相同前項產(chǎn)品下的后項產(chǎn)品排序。前項產(chǎn)品推薦排序方面�����,建議以前項產(chǎn)品的期望概率出發(fā)�,從大到小進(jìn)行排序�。當(dāng)確定了前項產(chǎn)品后,推薦后項產(chǎn)品的順序則應(yīng)該綜合考慮提升度和置信度���。由于提升度的大小是由置信度(分母)和后項期望概率(分子)的比值決定��,所以會存在由于后項期望概率(分子)過小�、而導(dǎo)致提升度反而比較大的情況。因此����,在后項推薦的時候,如果一定要有個先后順序����,則是先篩選出提升度大于1的規(guī)則,隨后再根據(jù)置信度的大小進(jìn)行排序�����。
2. 以產(chǎn)品為導(dǎo)向
以產(chǎn)品為導(dǎo)向��,意味著你有一款待銷的產(chǎn)品��,需要通過回溯規(guī)則的左邊����,找到最有可能購買的客戶。這種情況下��,我們已經(jīng)確定了后項期望概率���,就可以同樣通過提升度大于1的規(guī)則,隨后在根據(jù)置信度的大小進(jìn)行排序�����,找到推薦關(guān)系比較強(qiáng)的產(chǎn)品的購買者���。
以上簡單介紹了關(guān)聯(lián)規(guī)則在實際場景中的指標(biāo)應(yīng)用問題���,希望對大家能夠有所啟發(fā)。當(dāng)然�,關(guān)聯(lián)規(guī)則使用中,有些還會結(jié)合分群客戶協(xié)同過濾的方法����,有機(jī)會再和大家詳細(xì)聊聊。數(shù)據(jù)分析培訓(xùn)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試����,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情;
? 想學(xué)習(xí)CDA考試教材��,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫�����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330