大數(shù)據(jù)驅(qū)動下的微博社會化推薦
不同于搜索����,“推薦”通常不是獨立的互聯(lián)網(wǎng)產(chǎn)品,而是互聯(lián)網(wǎng)產(chǎn)品的核心組件���,為該產(chǎn)品的核心目標(biāo)服務(wù)��,比如電商網(wǎng)站的推薦是為了達(dá)成更多商品交易���。微博推薦同樣如此,其存在價值就是通過梳理和優(yōu)化用戶關(guān)系網(wǎng)絡(luò)���、打通內(nèi)容傳播鏈條����、引爆信息定向傳播���,從而實現(xiàn)加速高價值用戶關(guān)系構(gòu)建�����、優(yōu)質(zhì)內(nèi)容傳播和商業(yè)化營收等微博核心目標(biāo)�。
明確了推薦的角色和定位后,設(shè)計一個合適的推薦系統(tǒng)還需要系統(tǒng)了解微博的數(shù)據(jù)特點����。因為只有清楚數(shù)據(jù)的特點,才能更有針對性地設(shè)計推薦系統(tǒng)產(chǎn)品�、架構(gòu)和算法。


微博的數(shù)據(jù)特點
微博是一個以內(nèi)容消費為核心的偏弱關(guān)系社交網(wǎng)絡(luò)�����,關(guān)系的構(gòu)建多是依托于興趣���。它是半開放的,用戶看到的大部分內(nèi)容����,來自于2層關(guān)注構(gòu)建的網(wǎng)絡(luò)。而對社交網(wǎng)絡(luò)而言��,用戶關(guān)系網(wǎng)絡(luò)結(jié)構(gòu)�����、內(nèi)容信息、用戶是其數(shù)據(jù)三要素����,因此下文也主要會圍繞這3個要素對微博數(shù)據(jù)特點進行闡述。
用戶關(guān)系網(wǎng)絡(luò)結(jié)構(gòu):呈現(xiàn)海量����、社會化、興趣弱關(guān)系�、半開放等4個方面的特點。微博關(guān)系網(wǎng)絡(luò)擁有超過6億個節(jié)點����、1000多億條邊,每天有海量信息通過這張網(wǎng)絡(luò)傳輸�����。它就像一個虛擬社會���,帶著社會化分工����、去中心化、非對等性的屬性;每個用戶都有自己的真實身份和角色�,比如橙V、藍(lán)V����、普通用戶,承擔(dān)不同的職責(zé)并具備不同的話語權(quán)���,在內(nèi)容的生產(chǎn)�、傳播�、消費的過程中,扮演著不同角色����。
內(nèi)容信息:微博的信息是簡短��、豐富而碎片化的�����,同時存在著UGC和媒體內(nèi)容��,具備極快的傳播速度���。微博由點及面和Timeline的Feed流設(shè)計��,使其具備極好的信息傳播能力�����,這是微博的優(yōu)勢�,但同樣也會引發(fā)問題——飛速的傳播讓舊信息很快被淹沒掉,不管其價值多寡�。因此對于推薦系統(tǒng)來說,其主要目標(biāo)就是讓優(yōu)質(zhì)信息沉淀下來并獲得更多的曝光機會�����,這也是之所以要做“錯過的微博”的原因�。
用戶:微博用戶具備個性化的行為和偏好,承擔(dān)著良好的社會化分工角色��。同時�,微博通過基于UID的賬號體系來識別用戶,記錄歷史數(shù)據(jù)并存儲關(guān)系數(shù)據(jù)���,從而精確地了解每一個用戶�����,也為后面?zhèn)€性化推薦打下良好的基礎(chǔ)�。
微博推薦的設(shè)計主要包括產(chǎn)品、架構(gòu)�、算法3個方面,下面首先了解產(chǎn)品的設(shè)計思路���。
產(chǎn)品設(shè)計
微博自然推薦分為用戶和內(nèi)容推薦兩個部分���。
用戶推薦

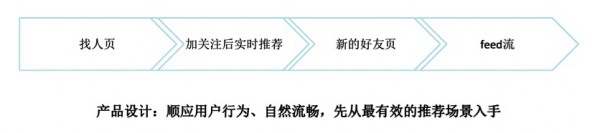
用戶推薦的產(chǎn)品目標(biāo)是優(yōu)化用戶關(guān)系網(wǎng)絡(luò)結(jié)構(gòu),在用戶推薦產(chǎn)品設(shè)計實踐中主要有兩點經(jīng)驗值得和大家分享���。
效果衡量指標(biāo)����。效果衡量指標(biāo)是連接產(chǎn)品定位和算法優(yōu)化方向的橋梁����,而這也是產(chǎn)品設(shè)計中不斷思考和摸索的方向。初始時我們直觀地認(rèn)為�,如果用戶喜歡推薦結(jié)果就會產(chǎn)生較高的點擊率�,從而將CTR作為衡量指標(biāo),但隨后這個思路就被否定���。用戶推薦的初衷是關(guān)系達(dá)成而不是即時愉悅用戶�����,于是衡量指標(biāo)被調(diào)整為RPM(Relation per Thousand Impression����,即千次曝光的用戶關(guān)系達(dá)成量)。在一段時間后我們開始反思一個問題:用戶關(guān)系達(dá)成的意義是什么�����,用戶關(guān)系量是否是越多越好呢?答案顯然是否定的����,受限于精力,推薦必須幫助用戶梳理關(guān)系網(wǎng)絡(luò)結(jié)構(gòu)���,讓用戶可以簡單地構(gòu)建高價值的用戶關(guān)系�����,從而讓用戶可以更好地消費內(nèi)容以及更容易地進行社交互動�����,因此衡量指標(biāo)衍生為關(guān)系達(dá)成后的互動率和用戶行為量�����。
產(chǎn)品設(shè)計原則���。推薦是用戶預(yù)期之外的非自然流量�����,應(yīng)該順應(yīng)用戶的行為�,以自然流暢的方式展現(xiàn)給用戶����。因此,推薦必須從最有效的主動場景入手��,比如微博找人頁用戶帶有明顯關(guān)注新用戶的意圖���,而這里展示用戶推薦正好滿足需求;而Feed流的瀏覽目的是內(nèi)容消費�����,推薦新用戶會打斷內(nèi)容消費的流暢性�����,效果很差����。
內(nèi)容推薦
內(nèi)容推薦的產(chǎn)品目標(biāo)是加速優(yōu)質(zhì)信息傳播以滿足內(nèi)容消費需求��,“錯過的微博���、贊過的微博�、正文頁相關(guān)推薦��、熱點話題”則是其中具有代表性的內(nèi)容推薦產(chǎn)品�����,這里會重點介紹下“錯過的微博”的設(shè)計思路����。
“錯過的微博”前身是一個叫做“智能排序“的推薦產(chǎn)品,主要用于解決信息過載情況下的排序問題����。正常情況下��,微博用戶平均每天會接收到2000+條Feed�,而真正閱讀的內(nèi)容不超過200條���,那么怎樣才能讓用戶看到更多高價值信息���,減少低質(zhì)內(nèi)容曝光,從而提升內(nèi)容消費體驗����,這正是產(chǎn)品的設(shè)計目的?����!爸悄芘判颉辈捎昧撕唵沃苯拥脑O(shè)計思路:Feed流按價值高低整體排序����,這樣做存在兩個問題:
定義及量化信息對用戶的價值。因為用戶對信息價值的理解方式千奇百怪�,因此不論如何調(diào)整算法總會讓部分用戶不滿意。
信息價值和時間順序的平衡�。整體重排序會讓微博丟失Timeline的排列屬性�,從而新的信息有可能排在舊的后面�����,而時間序是保證微博傳播能力和信息新鮮度的關(guān)鍵�����。
所以“智能排序”不是一個優(yōu)雅的解決方案���,而后通過數(shù)據(jù)分析發(fā)現(xiàn):用戶錯過的90+%信息中,只有部分內(nèi)容是對用戶具有極高價值且不容錯過的����,所以這里無需對未讀Feed全排序,只需要將最高價值的信息找出來并推薦給用戶��,其它的Feed仍按正常時間序排列�。這樣做一方面可以讓Feed流整體上符合Timeline的排序,用戶感覺自然流暢;另一方面�����,與用戶對最高價值的信息認(rèn)知上比較接近���,算法效果比較理想�����。產(chǎn)品推出后���,用戶認(rèn)可度很高�����,互動率遠(yuǎn)遠(yuǎn)高于普通Feed�����。
架構(gòu)設(shè)計
推薦系統(tǒng)的架構(gòu)設(shè)計����,包含在線服務(wù)�����,以及數(shù)據(jù)存儲�����、傳輸、計算兩個部分���。
首先看數(shù)據(jù)部分����,整體架構(gòu)分為Online和Offline兩個部分���,其中Online部分通過Kafka/Scribe把用戶的即時行為和發(fā)布內(nèi)容傳輸?shù)搅魇接嬎阆到y(tǒng)Storm中做即時處理,處理的結(jié)構(gòu)化數(shù)據(jù)存儲到Redis中���。而Offline的數(shù)據(jù)���,主要通過Hadoop平臺做基礎(chǔ)的存儲,然后通過Spark/MapReduce等分布式計算后���,將直接應(yīng)用到在線服務(wù)的數(shù)據(jù)存儲到HBase/Lushan/Redis等數(shù)據(jù)庫中����,亦或是存放到在線服務(wù)的本地文件�。
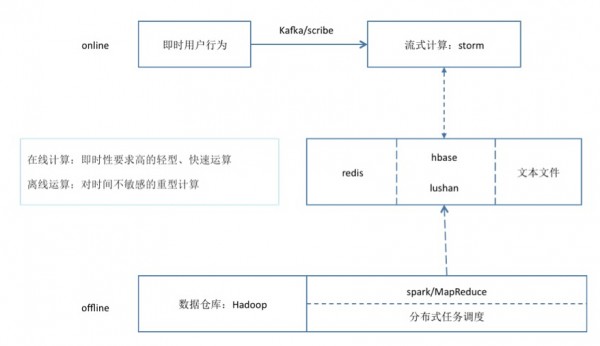
接下來看在線服務(wù)的架構(gòu)設(shè)計,如圖所示����,這里通過UVE(Uniform Value Estimate)來分發(fā)非自然流量——廣告����、運營����、推薦。推薦經(jīng)過應(yīng)用層接入后�����,會進入在線服務(wù)的核心處理模塊lab_common_so�,這個模塊主要實現(xiàn)了3項功能。
-
流量切分:即按滿足同樣數(shù)據(jù)分布的方式切分流量�����,用于算法策略的灰度實驗����。
-
排序:通過LR模型(ctr or RPM or ctr*click_value)實現(xiàn)推薦結(jié)果的精選排序。
-
算法策略選擇:動態(tài)加載更新算法策略庫.so文件��。
微博推薦候選集非常龐大���,架構(gòu)設(shè)計中分為初選與精選兩個模塊�����,精選模塊位于lab_common_so中��,而初選由獨立的功能模塊來承擔(dān)���,來源于3個維度:
-
離線計算:如用戶推薦95%的結(jié)果來自離線計算��。
-
Storm流式計算:實時計算用戶行為觸發(fā)的推薦結(jié)果�,并即時推薦給用戶�。
-
離線計算(生成半加工品的推薦資源數(shù)據(jù))+在線計算(通過索引IDX連接)���。
用于精選排序的ctr預(yù)估模型��,基于Hadoop平臺數(shù)據(jù)�����,通過Spark來分布式訓(xùn)練��。

算法設(shè)計
微博推薦的算法體系如圖所示�����,包含4層:數(shù)據(jù)挖掘��、基礎(chǔ)算法�、核心算法、混合算法技術(shù)��。
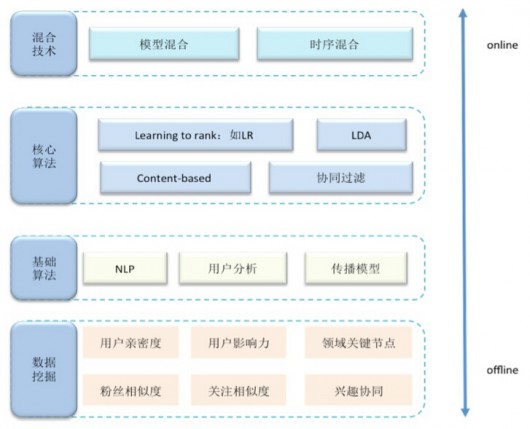
先看數(shù)據(jù)挖掘部分��,這里基于微博社交數(shù)據(jù)建模來完成用戶親密度�、用戶影響力、領(lǐng)域關(guān)鍵節(jié)點���、粉絲相似度�����、關(guān)注相似度�、興趣協(xié)同的量化計算�����,從而數(shù)據(jù)化地描述微博社交網(wǎng)絡(luò)��、用戶關(guān)系、用戶興趣和能力�,并將其作為在線推薦計算的中間結(jié)果數(shù)據(jù)。
基礎(chǔ)算法中���,都是大家比較熟知的NLP����、用戶分析�����、傳播模型等算法�,不做過多介紹。算法設(shè)計和實踐的重點是核心算法和混合技術(shù)�����,接下來會逐個介紹:
協(xié)同過濾
協(xié)同過濾是經(jīng)典的推薦算法���,在微博中廣泛應(yīng)用,共使用過如下4種:
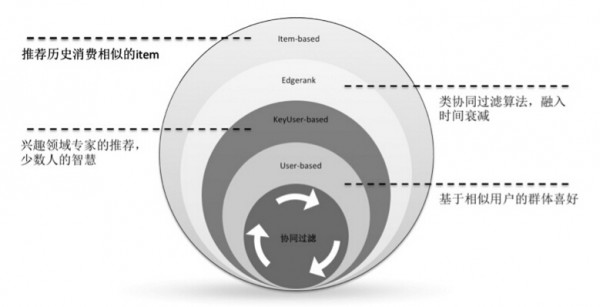
其中�,user-based協(xié)同的應(yīng)用最為廣泛。微博借助UID賬號體系��,經(jīng)過多年積累,存儲了充足的用戶數(shù)據(jù)���,user-based CF結(jié)果精確�����,且有良好的推薦理由;相對而言��,微博信息的時效性很強�,item-based協(xié)同效果不太理想��。此外�����,微博具有良好的社會化屬性�����,擁有大量各個領(lǐng)域的專家和關(guān)鍵節(jié)點���,從而在一些對專業(yè)知識要求較高的場景�����,基于keyUser-based的協(xié)同具有良好的效果����。在智能排序研發(fā)時曾借鑒Facebook的經(jīng)驗,實踐過Edgerank算法(加一些公式描述)��,是相對經(jīng)典的協(xié)同過濾��,引入了時間衰減因素���,來提升推薦結(jié)果的時效性��。
相關(guān)性推薦content-based
Content-based算法廣泛應(yīng)用在內(nèi)容推薦中��,這里將以微博正文頁相關(guān)推薦為例進行介紹�����,如圖所示分為在線和離線兩個部分�����。
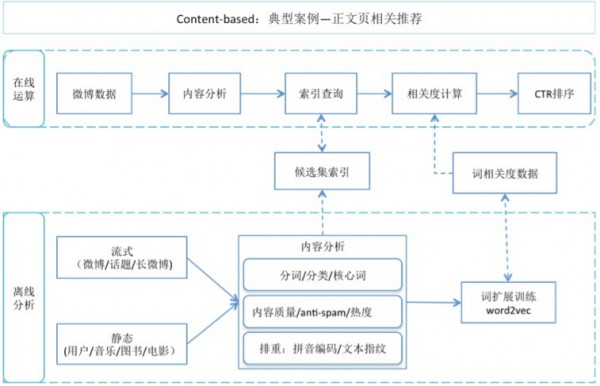
離線部分,多種候選物料(如微博、電影)經(jīng)過NLP結(jié)構(gòu)化處理后選取優(yōu)質(zhì)候選�����,以關(guān)鍵詞�����、分類為key構(gòu)建索引�����。其中微博�、話題、長微博的候選集索引通過流式計算產(chǎn)生��,可以做到分鐘級的實時更新���。此外�����,由于微博內(nèi)容簡短�����,可提取的有效關(guān)鍵詞數(shù)量有限�,為了提升推薦的覆蓋率和準(zhǔn)確度會以優(yōu)質(zhì)微博、長微博�����、話題為訓(xùn)練語料���,離線開展詞擴展����、詞聚類計算(基于word2vec)則用于在線相關(guān)性計算的輔助��。
在線計算���,用戶訪問正文頁后�����,推薦服務(wù)會基于Storm流式計算的分類����、關(guān)鍵詞向量結(jié)果查詢索引獲取推薦候選集��,并計算微博正文同各個推薦候選集的相關(guān)度,選擇相關(guān)而不相似的候選集開展ctr/RPM計算����,并由此排序得到推薦推薦結(jié)果呈現(xiàn)給用戶�。
排序模型
基于機器學(xué)習(xí)的Learning to ranking是推薦中常用解決排序問題的算法技術(shù),微博推薦的排序模型采用經(jīng)典的LR模型�����。
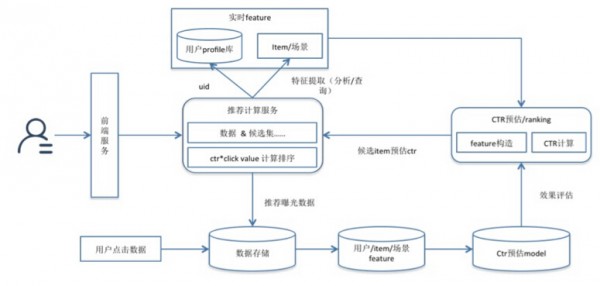
在線計算時的feature向量會隨著推薦服務(wù)日志記錄下來����,尤其是場景相關(guān)的feature,并通過特征工程的ETL框架將各類產(chǎn)品匯集和處理以生成訓(xùn)練樣本�����,開展模型訓(xùn)練���?�;A(chǔ)feature分為用戶��、item�、場景3個維度,而實際應(yīng)用的feature多為交叉特征��。
另外���,對于多種推薦候選集共存的場景���,這里通過ctr*click_value的方式來解決綜合排序問題,click_value的計算主要考慮候選集結(jié)果對用戶產(chǎn)生的長遠(yuǎn)影響�����,如用戶閱讀一篇長文章���、關(guān)注一個新用戶的click_value要遠(yuǎn)高于點擊一個相關(guān)微博����。
時序混合
微博推薦會隨著用戶行為而實時調(diào)整推薦結(jié)果�����,這里通過時序混合算法策略來達(dá)成這一目的�,在不同的階段采用不同的算法。如圖是一個正文頁的例子��。
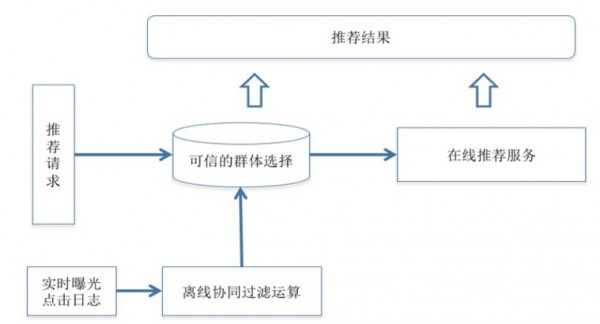
在實際場景中,很多用戶會先后訪問同一個正文頁���,在初始曝光階段��,系統(tǒng)會采用content-based 算法給出推薦結(jié)果,而正文頁得到了充分曝光和足夠多可信用戶的互動行為后��,會采用協(xié)同過濾的算法計算推薦結(jié)果��,并呈現(xiàn)給后續(xù)訪問的用戶���。這個算法思路基于一個樸素的假設(shè):訪問同一個正文頁的用戶存在相似的即時興趣�����,從而這里可以采用user-based CF并結(jié)合貝葉斯平滑來選擇點擊率最好的item做好推薦結(jié)果�,計算方式如下����。

其中為用戶i的歷史點擊率,用以消除不同用戶的點擊率偏差��。
模型融合
單一的算法模型都存在局限性��,為了解決復(fù)雜的社會化推薦問題,通常會采用模型融合的方法來實現(xiàn)模型間的優(yōu)勢互補�����,提供最佳的推薦結(jié)果�。分層模型融合和分片線性模型是微博推薦中應(yīng)用較多的。
分層模型融合��,即上一層模型的輸出作為下一層模型的feature輸入����,通常采用多層LR或LR+GBDT的方式,如圖所示�����。
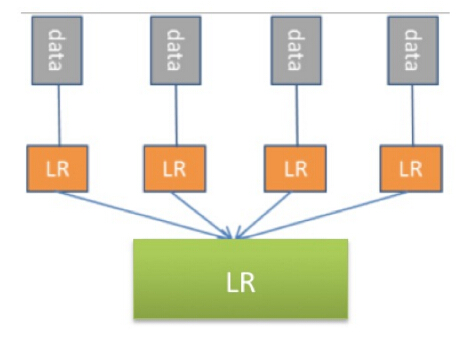
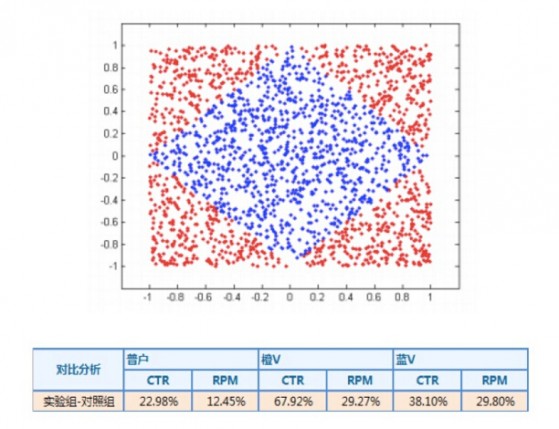
分片線性模型:由于線性模型的局限性�����,很多時候無法學(xué)到泛化效果好的非線性關(guān)系���,為了應(yīng)對各類跨平臺�、分場景的推薦問題,我們引入了分片擬合�����、分而治之的分片線性模型��,即多個模型解決同一個問題����,每個模型應(yīng)用于其效果最好的條件流量。以微博用戶推薦為例���,我們從用戶類型維度將空間/流量劃分為3個局部區(qū)域——藍(lán)V、橙V和普通用戶���,它們各有一個線性預(yù)測模型來分片融合給出推薦結(jié)果���,取得了很好的效果。另外在微博廣告實踐中也從平臺維度劃分流量空間并采用了分片線性模型���,從而大幅提升了CTR預(yù)估的精準(zhǔn)性�。
商業(yè)化設(shè)計—商業(yè)推薦
經(jīng)過多年的發(fā)展���,微博積累了大量高價值用戶��,如明星��、領(lǐng)域?qū)<?����,他們都積累了豐富的社交資產(chǎn)�,具有一呼百應(yīng)的社交影響力。同時��,微博上又有大量的企業(yè)用戶�,希望通過微博平臺推廣和營銷,但自身用戶關(guān)系網(wǎng)絡(luò)狹小�,從而內(nèi)容缺乏自我傳播能力,希望能快速構(gòu)建粉絲關(guān)系網(wǎng)絡(luò)��,借助高價值用戶的關(guān)系網(wǎng)絡(luò)來推廣自己的產(chǎn)品��。另外�,很多用戶都存在偶發(fā)的自我推廣訴求,希望自己的信息被所有的粉絲看到����,甚至能曝光給潛在粉絲,但微博信息更新速度快,信息又很容易被淹沒掉�����。
推薦可以很好地解決上述問題�����,滿足企業(yè)和個人的推廣需求����,來通過“連接”實現(xiàn)商業(yè)化變現(xiàn)。粉絲頭條和漲粉助手是兩個最有代表性的微博商業(yè)推薦產(chǎn)品����。
漲粉助手重點解決高價值粉絲關(guān)系網(wǎng)絡(luò)的快速構(gòu)建問題�����,而粉絲頭條專注于企業(yè)推廣信息的精準(zhǔn)觸達(dá)和有效曝光���,并通過將名人�、關(guān)鍵節(jié)點轉(zhuǎn)化為企業(yè)的產(chǎn)品代言人�����,來達(dá)成高影響力用戶的社交資產(chǎn)變現(xiàn)和企業(yè)用戶的營銷需求,進而將名人的影響力引渡到品牌上���,拉近明星�����、品牌���、用戶的距離。在社交網(wǎng)絡(luò)中��,廣告的效果與信息發(fā)布者有著重要的關(guān)系��,因為用戶影響力不同帶來的信任度也就不同�����。
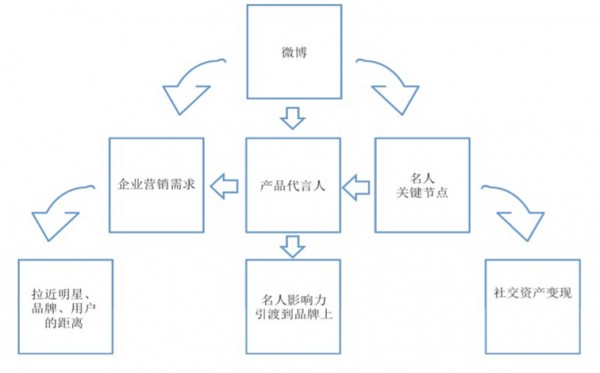
通過系統(tǒng)性的產(chǎn)品設(shè)計來實現(xiàn)特定微博信息的爆炸性定向傳播���,其實現(xiàn)機制如圖所示�����。
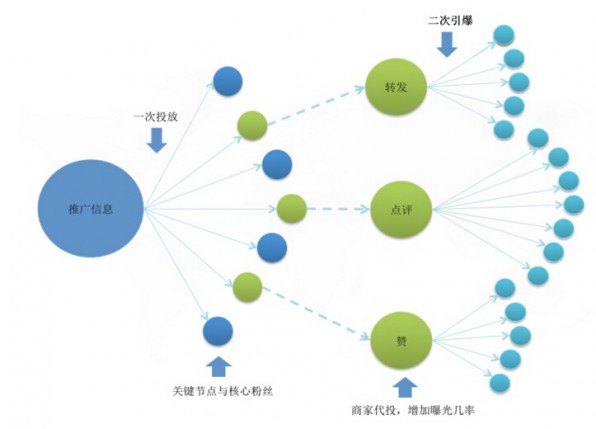
引爆過程包含兩次粉絲頭條投放:第一次將推廣內(nèi)容投放給關(guān)鍵節(jié)點與核心粉絲���,等他們產(chǎn)生轉(zhuǎn)��、評�、贊等行為后���,再代投這些互動內(nèi)容����,借助關(guān)鍵節(jié)點的粉絲資產(chǎn)來定向推廣自己的產(chǎn)品以實現(xiàn)二級粉絲關(guān)系網(wǎng)絡(luò)中的擴散傳播���,星火燎原���。
在算法實現(xiàn)維度會重點介紹最關(guān)鍵的算法模塊:個性化定價與分包。這里主要為客戶提供了4個檔位的粉絲頭條投放包�,而算法需要解決的是提升用戶的購買率和總體收入�����,并保障平臺流量變現(xiàn)效率和客戶ROI之間的均衡�。
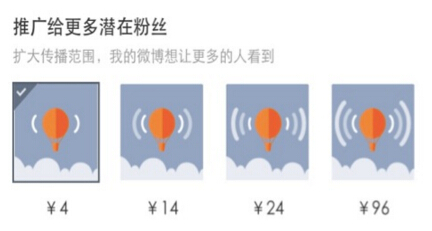
算法設(shè)計的關(guān)鍵是先定價�、后分包�,首先通過客戶心理價格和購買力建模,計算不同用戶在面對不同價格時的購買概率����,進而計算最佳的呈現(xiàn)價格:
-
第一檔:購買率>min_threshold條件下,max{price}
-
第二檔:max{P(購買率|用戶類型����,price1)*price2}
-
第三擋:max{P(購買率|用戶類型,price1,pric2)*price3)
-
最大包:price4 = 受眾包用戶量*1000/eCPM�����。
而分包是在特定價格下需要推廣給多少潛在粉絲�,即綜合考慮訂單復(fù)購率、客戶ROI的最優(yōu)eCPM計算:max{eCPM*(1+P(復(fù)購率|eCPM,ROI))�。
寫在最后
推薦技術(shù)誕生于上世紀(jì)80年代,而真正的繁榮卻源自于大數(shù)據(jù)的推動��。本文從推薦的定位���、微博的數(shù)據(jù)特點�、數(shù)據(jù)驅(qū)動的系統(tǒng)(產(chǎn)品/架構(gòu)/算法)設(shè)計����、推薦的商業(yè)化等4個方面全面闡述微博的社會化推薦實踐���。在這個過程中,架構(gòu)設(shè)計和數(shù)據(jù)存儲建立在成熟的大數(shù)據(jù)工具和解決方案上����,產(chǎn)品和算法設(shè)計則大量應(yīng)用了大數(shù)據(jù)的思路和技術(shù)。通過挖掘社會化數(shù)據(jù)寶藏�,量化“連接”價值,尋找高價值“連接”��,為用戶呈現(xiàn)優(yōu)質(zhì)的個性化推薦結(jié)果����。最后詳細(xì)描述了微博推薦商業(yè)化變現(xiàn)的構(gòu)想和實踐,證明推薦在社交網(wǎng)絡(luò)中依然具備良好的商業(yè)價值����,而不僅僅是電商網(wǎng)站。微博是社會化資產(chǎn)變現(xiàn)的開拓者���,希望我們的經(jīng)驗?zāi)軌驅(qū)ψx者有所啟發(fā)和幫助��,并歡迎大家為我們提出寶貴的建議����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試���,點擊>>>
“CDA報名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情�����;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330