大數(shù)據(jù)分析:找合適的瓶,釀新的酒
為什么談到大數(shù)據(jù)����,傳統(tǒng)企業(yè)表現(xiàn)出更多的困惑?其原因是���,企業(yè)決策者并不清楚大數(shù)據(jù)能給業(yè)務(wù)帶來哪些價值�����,也不知道如何學(xué)習(xí)、使用大數(shù)據(jù)分析工具���。而這些大數(shù)據(jù)工具就擺在那里�,誰能先一步學(xué)習(xí)使用�,誰就占有先機。
算起來�����,接觸大數(shù)據(jù)����、和互聯(lián)網(wǎng)之外的客戶談大數(shù)據(jù)也有快2年了�����。也該是時候整理下一些感受��,和大家分享下我看到的國內(nèi)大數(shù)據(jù)應(yīng)用的一些困惑了�����。
云和大數(shù)據(jù)��,應(yīng)該是近幾年IT炒的最熱的兩個話題了����。在我看來���,這兩者之間的不同就是:云是做新的瓶���,裝舊的酒; 大數(shù)據(jù)是找合適的瓶,釀新的酒���。
云說到底是一種基礎(chǔ)架構(gòu)的革命�。原先用物理服務(wù)器的應(yīng)用���,在云中變成以各種虛擬服務(wù)器的形式交付出去��,從而計算�、存儲、網(wǎng)絡(luò)資源都能被更有效率的利用了���。于是���,酒量好無酒不歡的人就可以用個海碗牛飲二鍋頭;酒量小又想嘗嘗微醺小醉風(fēng)情的人也可以端個小杯咂巴咂巴女兒紅。
大數(shù)據(jù)的不同在于�,它其實是把以前人們丟棄不理的數(shù)據(jù)都撿起來,加以重新分析利用����,使之產(chǎn)生新價值的技術(shù)�����。換句話說���,原先20斤的糧食只能出2斤的 酒糟��,現(xiàn)在20斤的糧食都變成或者大部分變成酒糟����。當(dāng)然這酒糟肯定會和原先的酒糟有不一樣,所以釀出來的酒肯定和以前不同�����,喝酒����、裝酒、儲存酒的方法自然 也不同�。
所以,相對于云��,人們對大數(shù)據(jù)使用的困惑更大��。接下來談?wù)勎宜吹降膸最愖疃嗟睦Щ?��,以及我們目前存在哪些問題���。
困惑之一:大數(shù)據(jù)能干什么?
換用前面飲酒來作比方,這新釀出來的酒怎么喝才可以喝得痛快�。這里不再想討論到底哪些數(shù)據(jù)是大數(shù)據(jù)了。 下面這張圖是Gartner 對各行業(yè)對于大數(shù)據(jù)需求的調(diào)查,該統(tǒng)計針對大數(shù)據(jù)通用的3個V ��, 以及未被利用數(shù)據(jù)的需求情況做了分類����。 可見幾乎所有行業(yè)都對大數(shù)據(jù)有著各種各樣的需求。
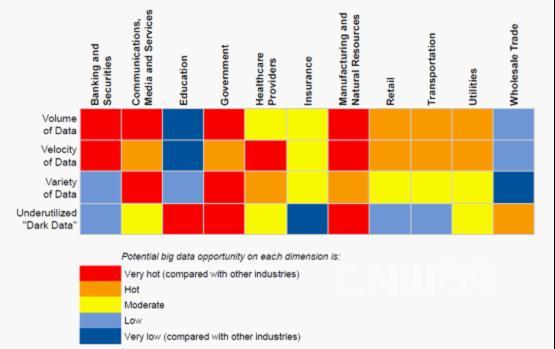
圖片來自Gartner
為什么有這些需求�,是因為以前這些類型的數(shù)據(jù)都因為技術(shù)和成本的原因,用戶沒有收集處理?,F(xiàn)在有了性價比合理的手段可以讓你收集處理這些數(shù)據(jù),怎么 可能說不要?還是以釀酒做比喻���,以前釀兩斤酒糟要浪費18斤的糧食���,現(xiàn)在至少20斤糧食可以有10斤都變成酒糟了,雖然這些酒糟可能和以前不大一樣�,但至 少可以少浪費8斤糧食呢。
現(xiàn)在問題來了�,酒糟多了���,種類不一樣了,怎么根據(jù)新的酒糟釀酒呢?對不起��,這個問題酒作坊就要別人來教了�����。但問題是��,所有酒坊現(xiàn)在可能都面臨這同一 個問題��,于是就沒人可以教你了�����,只能自己慢慢摸索���。這個就是現(xiàn)在各行業(yè)面對大數(shù)據(jù)的最大困惑 — 海量的數(shù)據(jù)收集上來不知道怎么用�����。
這里不妨看看為什么傳統(tǒng)的數(shù)據(jù)倉庫領(lǐng)域沒有這樣的困惑����。如下這張圖很好的說明了傳統(tǒng)和現(xiàn)在的區(qū)別:
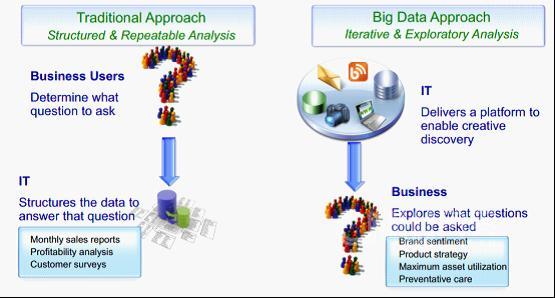
圖片來自Sogeti
從上圖展示的流程可以看出產(chǎn)生困惑的根本原因是:苦逼的IT從業(yè)人員走在了業(yè)務(wù)決策者的前面 (流淚) �。傳統(tǒng)時代,都是業(yè)務(wù)人員希望得到某類型的統(tǒng)計報表或者分析預(yù)測�,于是IT行業(yè)人員為了滿足他們的需求找方案、寫算法�,從而催生出了各種類型的數(shù)據(jù)倉庫和 解決方案���。而現(xiàn)在,在互聯(lián)網(wǎng)的推動下�����,IT人員發(fā)覺原來我們可以通過一些新的方式存儲海量的原先無法處理的數(shù)據(jù)��,但業(yè)務(wù)人員卻沒有準(zhǔn)備好����。所以,當(dāng)你告訴 他們:“嘿�,哥們兒,我這里現(xiàn)在又有了很多數(shù)據(jù)可以幫你了��?�!彼麄円活^霧水不知道這些數(shù)據(jù)對他們有什么用了�。
怎么解決這個問題?先來看傳統(tǒng)廠商Oracle、IBM他們是怎么做的��。方式細(xì)節(jié)略有不同���,但他們的思路基本如下:
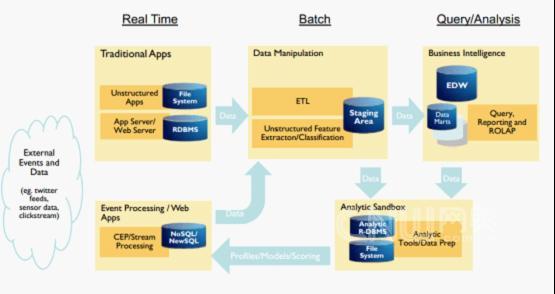
圖片來自HP首席技術(shù)專家 Greg Battas在ABDS2012大會上的 分享
簡單來說,這種處理方式是把Hadoop和其它各類NewSQL、NoSQL方案以ETL�,或外部表的方式引入現(xiàn)有的數(shù)據(jù)分析解決方案架構(gòu)中。這種 方案因為上層的數(shù)據(jù)倉庫沒有大的改變�,客戶可以繼續(xù)使用原先的算法和報表結(jié)構(gòu),即在新的數(shù)據(jù)平臺上繼續(xù)沿用舊的應(yīng)用場景和分析方法�。好處是由于引入了大數(shù) 據(jù)技術(shù),可以處理多種數(shù)據(jù)源���,同時降低原先海量數(shù)據(jù)ETL的成本��。但這種方法依然存在不少問題:
問題一:性能瓶頸依然存在��。
縱觀現(xiàn)在各類NewSQL�����、NoSQL方案���,分布式是一個最顯著的特色。之所以大家 都采用分布式架構(gòu)����,就是因為傳統(tǒng)的縱向擴展方案,在處理海量數(shù)據(jù)時候性能沒法隨著數(shù)據(jù)量的增長而線性擴展�,或者成本代價太高�。而上圖的方案���,雖然通過 Hadoop解決了ETL的性能瓶頸問題�����,但BI還是傳統(tǒng)的數(shù)據(jù)倉庫�����,海量的ETL使得原有數(shù)據(jù)倉庫需要處理的數(shù)據(jù)量大增���,所以必須花很大代價再次升級原 有的數(shù)據(jù)倉庫,否則分析就會跑的比原先還慢�。因此,用戶依然需要升級價格不菲的上層數(shù)據(jù)倉庫�����,向原先效率一般的算法妥協(xié)性能����。
問題二:大數(shù)據(jù)投資被浪費。
舊的分析應(yīng)用場景�����,算法是基于關(guān)系型數(shù)據(jù)庫的�。和大數(shù)據(jù)方案的邏輯模式有很大的不同,這不同主要有兩類�����。
沙里淘金和打磨玉石的區(qū)別�����。我舉過辣子雞的例子來形容Hadoop����,大致是說一盤辣子雞就是大數(shù)據(jù),Hadoop就是辣子雞里剔除尖椒�,找出能吃的 雞塊的方法。其實���,大數(shù)據(jù)的處理就是幫你淘金的過程�����。以前沒有那么合適的“篩子”��,所以只能放棄在沙子里淘金的夢想��,現(xiàn)在有了合適的“篩子”�����,就可以去從 沙灘上比較高效快速的找出那些“閃光”的東西了���。而傳統(tǒng)的數(shù)據(jù)處理方式���,其實已經(jīng)通過人工、半人工的方式�,把很多篩撿工作做了。所以雖然丟棄了大量的數(shù) 據(jù)�,但是保留下的數(shù)據(jù)已經(jīng)是塊“璞玉”了,要做的只是對這塊“璞玉”再精雕細(xì)啄��,使其成為價值連成的“美玉”�。 所以,用傳統(tǒng)的數(shù)據(jù)處理方法來處理大數(shù)據(jù)�,就是拿美工刀去宰一頭牛,即使有人幫你端盤子分部位�,還沒殺死牛人就累死。
動車組和火車的區(qū)別。分布式的大數(shù)據(jù)架構(gòu)�����,其核心思想和三灣改編時的核心思想是一樣的:把支部建到連隊中去����。把黨的有生力量分布到各個戰(zhàn)斗單元中�, 大大提高中央戰(zhàn)略的貫徹執(zhí)行,提高各個戰(zhàn)斗單位的機動性和戰(zhàn)斗力���。就是動車為什么比火車開得快的道理:每節(jié)車廂都有動力��,雖然每節(jié)都不比火車頭強勁�,但車 廂越多就跑的越快����。而火車頭再強勁,也有拖不動更多車廂的時候?�,F(xiàn)有的分析算法��,很多時候都是針對“火車頭”類型的���,很多時候沒辦法拆分成很多小的運算分 布到每個節(jié)點上��。于是�,如果沿用之前的算法,那么就必須增加額外的軟件方案把已經(jīng)分布出去了的數(shù)據(jù)再“集中”起來�,額外增加的環(huán)節(jié),肯定費時費力��,效果不 可能會好�����。
在我看來�,前面提到的傳統(tǒng)廠商解決企業(yè)大數(shù)據(jù)應(yīng)用困惑的方案不是最好的方案。什么是最好的方案呢?其實很簡單���,就是針對新的數(shù)據(jù)集和數(shù)據(jù)庫結(jié)構(gòu)特點 開發(fā)新的應(yīng)用分析場景���,并把這些分析應(yīng)用場景直接跑到大數(shù)據(jù)架構(gòu)上。而不是去削足適履���,拿新的NewSQL�、NoSQL嫁接傳統(tǒng)方案�。
這么做的好處不言而喻,關(guān)鍵是如何實現(xiàn)?這些事不能由搞IT的人來告訴業(yè)務(wù)人員,得讓業(yè)務(wù)人員來告訴我們!大數(shù)據(jù)應(yīng)用要真正在企業(yè)里生根開花����,真的 需要一些數(shù)據(jù)科學(xué)家做需求生成(Demand Generation)的工作。我們要通過他們的幫助�,使這張圖里的大數(shù)據(jù)路徑翻轉(zhuǎn)過來,像傳統(tǒng)數(shù)據(jù)處理一樣���,由業(yè)務(wù)人員告訴我們���,他們想做什么!
我接觸過很多客戶�,去之前得到的需求都是:希望了解Hadoop或者內(nèi)存數(shù)據(jù)庫。但是去了之后都發(fā)覺����,他們其實不知道Hadoop或者內(nèi)存數(shù)據(jù)庫可 以幫他們達到哪些目的,希望我們可以告訴他們�����。但很坦率的說�,這個不是我們這些搞IT基礎(chǔ)架構(gòu)的人該做的事情。我們已經(jīng)“超前”的儲備好了這類技術(shù)手段 了��,怎么用這類技術(shù)真的是應(yīng)該懂業(yè)務(wù)的人去想,而不是我們了�。
所以,在這里我想呼吁IT行業(yè)里�����,處在金字塔頂?shù)膶I(yè)咨詢師����、數(shù)據(jù)分析人員、數(shù)據(jù)科學(xué)家們�,現(xiàn)在是時候走出原先的框架看看新技術(shù)新架構(gòu)下有些新商機 了。不要總是桎梏于傳統(tǒng)的思路和方法�����,讓新的大數(shù)據(jù)思想來做“削足適履”的事情了�。真心希望你們可以利用專業(yè)知識和行業(yè)經(jīng)驗,幫著那些”求大數(shù)據(jù)若渴“的 行業(yè)用戶們好好定位下對他們真正有價值的新應(yīng)用場景��,設(shè)計更多的有意義的分布式算法和機器學(xué)習(xí)模型�����,真正幫助他們解決大數(shù)據(jù)應(yīng)用之惑�����。











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330