大數(shù)據(jù)精準(zhǔn)營銷中的個性化推薦與應(yīng)用
亞馬遜通過個性化推薦所獲取的交易額占總交易額的20%;雙十一期間,天貓和淘寶通過對數(shù)據(jù)的挖掘�����,使用了“千人千面”的個性化推薦;阿里CEO張勇在之后的媒體溝通會上肯定贊揚了個性化推薦所取得的成績…….���。
這一切表明�����,個性化推薦所突顯的作用越來越受到企業(yè)的重視����。
何為個性化推薦��?概括來說“人-場景-商品”這三個維度是人性化推薦的基礎(chǔ)��。推薦的過程就是通過尋找這三個維度之間的相關(guān)性���,提供“人-場景-商品”的最佳組合���。
個性化推薦可分為兩類:基于內(nèi)容的推薦、協(xié)同過濾推薦��,下面我們來分別了解一下���。
一���、基于內(nèi)容的推薦(Content-based Recommendations)
第一步是統(tǒng)計相應(yīng)的內(nèi)容材料,確定樣本集的正例和負(fù)例�。舉個栗子:如果要將iphone6s 推薦給相應(yīng)的客戶,那么樣本集正例就是那些購買過iphone6s的人��,樣本集負(fù)例就是那些沒購買過iphone6s的人����。
第二步就是引用學(xué)習(xí)算法,基于內(nèi)容的推薦的學(xué)習(xí)算法主要有:Rocchio算法����、決策樹算法、線性分類算法��、樸素貝葉斯算法、GBDT�����。這些學(xué)習(xí)算法都可以在網(wǎng)上找到相應(yīng)的代碼�,可以根據(jù)相應(yīng)的數(shù)據(jù)特點和所要應(yīng)用的商業(yè)場景選擇相應(yīng)的學(xué)習(xí)算法。
第三步是確定模型的特征變量����,這需要先為每一個item(場景下的商品)提取出相應(yīng)的特征數(shù)據(jù),并且統(tǒng)計樣本中的人對于每一個item的特征偏好(喜歡和不喜歡)�����,這樣學(xué)習(xí)算法可以算出特征變量對于模型的卡方和增益��,卡方越大�����,說明該特征變量對于模型樣本的區(qū)分度越高�,增益越大,說明該特征變量給模型帶來的信息熵越高���。舉個栗子:對于”iphone6s目標(biāo)客戶“模型�,有地域�����、收入���、年齡����、學(xué)歷�、歷史購買均單價等特征變量,其中卡方的大?���。菏杖?gt;歷史購買均單價>學(xué)歷>年齡>地域,那么對于“iphone6s目標(biāo)客戶“模型來說����,特征變量的重要性大小:收入>歷史購買均單價>學(xué)歷>年齡>地域��。需要說明的是����;選擇特征變量時�,要結(jié)合樣本集的數(shù)據(jù)量��,因為當(dāng)樣本集數(shù)據(jù)量過大�,而特征變量太少,就會導(dǎo)致內(nèi)容推薦模型欠擬合�����,當(dāng)樣本集數(shù)據(jù)量太少��,而特征變量又多���,則會導(dǎo)致內(nèi)容推薦模型過擬合����。過擬合和欠擬合都會影響推薦模型的準(zhǔn)確性�����。
第四步是訓(xùn)練模型�����,可以通過調(diào)參數(shù)的方式優(yōu)化模型的正確率��,正確率越高,表示模型的質(zhì)量越高�。
簡要的說:基于內(nèi)容的推薦是就是通過機器學(xué)習(xí)產(chǎn)生相應(yīng)的規(guī)則模型�,然后用模型預(yù)測用戶在特定場景下對商品的偏好度。
基于這樣的思維方式����,我們可以在各個場景下針對不同的商品構(gòu)建出不同的模型,有了這些模型集��,當(dāng)新的用戶進(jìn)來��,跑下各個模型����,就可以判斷該用戶是哪個商品的目標(biāo)客戶,從而判斷給她推薦什么商品���。
二��、協(xié)同過濾(Collaborative Filtering Recommendation)
第一種是基于用戶的協(xié)同過濾���,這種一般基于用戶有足夠的社會屬性數(shù)據(jù)。舉個栗子:用戶凱文對iphone6s沒有相應(yīng)信息記錄����,那么可以(采用皮爾森系數(shù))找到和凱文社會屬性相似的曉華, 統(tǒng)計曉華對iPhone6s 的偏好度( 對比曉華對于所有商品的偏好度)��。最后預(yù)測出凱文對于iphone6s的偏好度�����。
第二種是基于物品的協(xié)同過濾�����,這種多應(yīng)用于電商業(yè)務(wù)中��,再舉個栗子:用戶凱文對于iphone6s沒有相應(yīng)的信息記錄����,那么可以(采用余弦算法)找到和iPhone6s具有相同的產(chǎn)品特征的商品x, 統(tǒng)計凱文于商品x的偏好度(對比凱文對于所有商品的偏好度)����,最后預(yù)測出凱文對于iphone6s的偏好度。
協(xié)同過濾的算法主要有:皮爾森算法�����,杰西卡算法,余弦距離相似算法����,歐式距離算法等。在此不做贅述��,本文重點對個性化推薦相關(guān)分類內(nèi)容進(jìn)行闡述����,以此拋磚引玉���,期待與大家進(jìn)一步深入探討�����。
三�����、案例
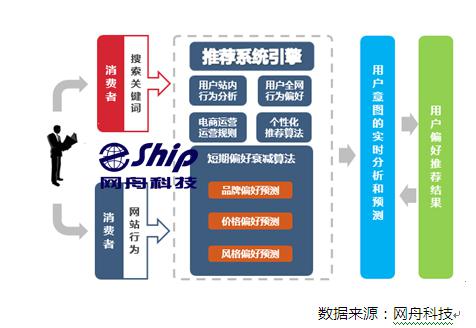
網(wǎng)舟科技為客戶提供的個性化薦服務(wù)�����,通過對用戶線上線下數(shù)據(jù)的聚類���、關(guān)聯(lián)和協(xié)同過濾�����,建立了不同使用場景的推薦機制�,實現(xiàn)推薦引擎從傳統(tǒng)的大眾化推薦向差異化推薦轉(zhuǎn)變�����,協(xié)助企業(yè)實現(xiàn)智能商品導(dǎo)購����,提升了用戶購買過程的體驗,增加了商品的銷量���。通過分析大量用戶行為日志����,精準(zhǔn)把握消費偏好���,針對用戶整個瀏覽過程中的各個頁面��,給用戶提供個性化頁面展示�。在用戶購買最佳的時間,為用戶推薦最適合的商品�����,從而提高網(wǎng)站的點擊率和轉(zhuǎn)化率�����。達(dá)到拉動銷售額增長���,增加交叉/向上銷售�,提升客戶滿意度的效果(如圖所示)�����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情��;
? 想學(xué)習(xí)CDA考試教材��,點擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�,點擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330