今天跟大家介紹的是SVM算法原理以及實現(xiàn)���,廢話不多說�,直接來看干貨吧!
一���、SVM概念
SVM的全稱為Support Vector Machine,也就是我們經(jīng)常提到的支持向量機��,主要被用來解決模式識別領(lǐng)域中的數(shù)據(jù)分類問題�����,是一種有監(jiān)督學習算法。
具體解釋一下:
Support Vector�,支持向量,指的是訓練樣本集中的某些訓練點�,這些訓練點非常靠近分類決策面�,因此是最難分類的數(shù)據(jù)點。SVM中最優(yōu)分類標準為:這些點與分類超平面之間的距離達到最大值;
Machine“機”���,指的是機器學習領(lǐng)域?qū)σ恍┧惴ǖ慕y(tǒng)稱�,通常我們把算法看做一個機器或?qū)W習函數(shù)����。SVM是一種有監(jiān)督的學習方法,主要是針對小樣本數(shù)據(jù)的學習�、分類和預(yù)測。
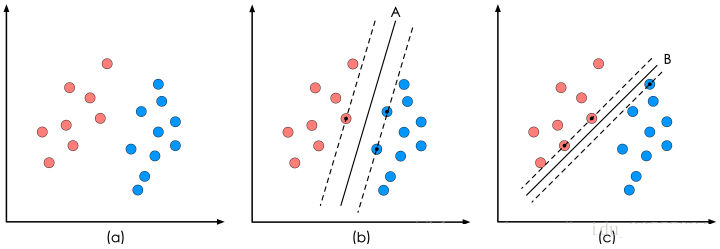
二����、SVM的優(yōu)點
1、需要的樣本數(shù)量不是很大����,但這并不表示SVM訓練樣本的絕對量很少,只是說與其他訓練分類算法相比,在同樣的問題復(fù)雜度情況下��,SVM對樣本的需求相對是較少的�。而且SVM引入了核函數(shù),因此即使是高維的樣本����,SVM也能輕松應(yīng)對。
2�、結(jié)構(gòu)風險最小。這種風險指的是分類器對問題真實模型的逼近�����,以及問題真實解之間的累積誤差����。
3、非線性��,指的是:SVM非常擅長應(yīng)付樣本數(shù)據(jù)線性不可分的情況�����,通常是利用松弛變量(或者叫懲罰變量)以及核函數(shù)技術(shù)來實現(xiàn)的����,這也是SVM的精髓所在。
三����、SVM的原理
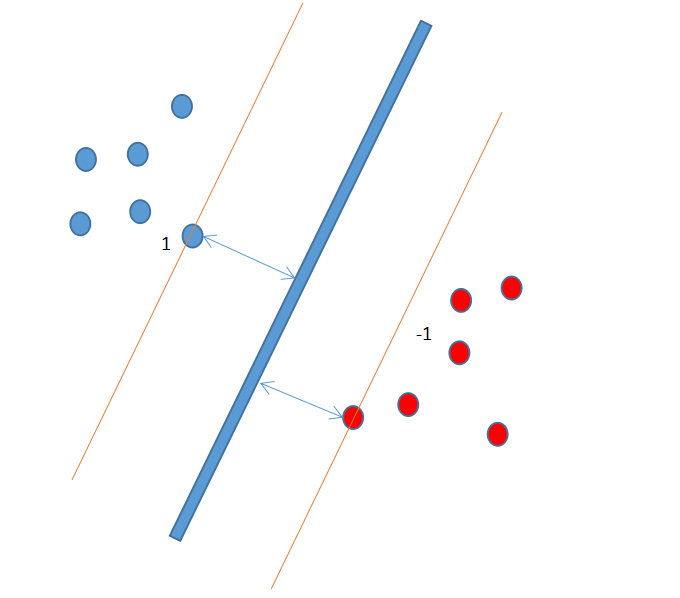
1.點到超平面的距離公式
超平面的方程也可以寫成一下形式: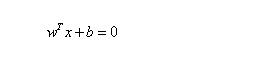
假設(shè)P(x1.x2...xn)為樣本的中的一個點,其中xi表示為第個特征變量����。那么該點到超平面的距離d就可以用如下公式進行計算: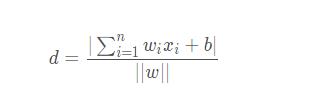
其中||w||為超平面的2范數(shù),也就是w向量的模長����,常數(shù)b類似于直線方程中的截距。
2.最大間隔的優(yōu)化模型
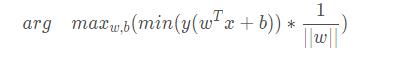
其中y代表數(shù)據(jù)點的標簽�����,并且其為-1或1.若數(shù)據(jù)點在平面的正方向(也就是+1類)�����,那么就是一個正數(shù)��,而如果數(shù)據(jù)點在平面的負方向的情況下(即-1類)�,仍然是一個正數(shù),這樣就可以保證始終大于0了。我們需要注意�,如果w和b等比例放大,d的結(jié)果不會改變����。令u=y(wTx+b),所有支持向量的u為1.那么其他點的u大于1.我們可以通過調(diào)節(jié)w和b求到����。這樣一來,上面的問題可以簡化為:
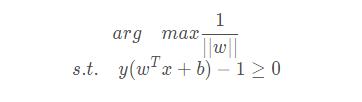
等價替換為:
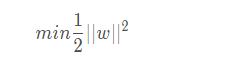
這是一個有約束條件的優(yōu)化問題���,我們通常會用拉格朗日乘子法來求解�����。令:
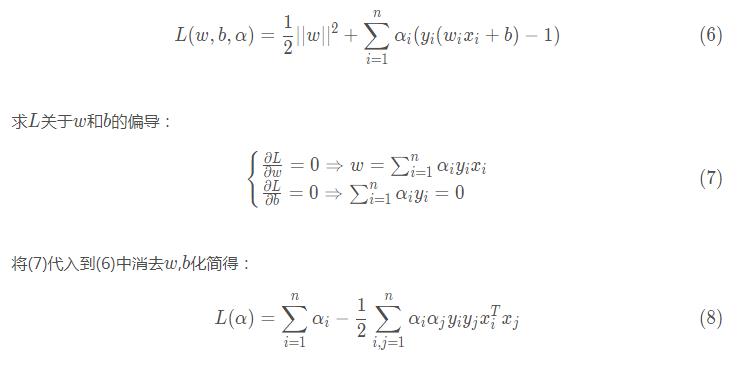

四���、python實現(xiàn)
#svm算法的實現(xiàn)
from numpy import*
import random
from time import*
def loadDataSet(fileName):#輸出dataArr(m*n),labelArr(1*m)其中m為數(shù)據(jù)集的個數(shù)
dataMat=[];labelMat=[]
fr=open(fileName)
for line in fr.readlines():
lineArr=line.strip().split('\t')#去除制表符,將數(shù)據(jù)分開
dataMat.append([float(lineArr[0]),float(lineArr[1])])#數(shù)組矩陣
labelMat.append(float(lineArr[2]))#標簽
return dataMat,labelMat
def selectJrand(i,m):#隨機找一個和i不同的j
j=i
while(j==i):
j=int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):#調(diào)整大于H或小于L的alpha的值
if aj>H:
aj=H
if aj<L:
aj=L
return aj
def smoSimple(dataMatIn,classLabels,C,toler,maxIter):
dataMatrix=mat(dataMatIn);labelMat=mat(classLabels).transpose()#轉(zhuǎn)置
b=0;m,n=shape(dataMatrix)#m為輸入數(shù)據(jù)的個數(shù)�����,n為輸入向量的維數(shù)
alpha=mat(zeros((m,1)))#初始化參數(shù)���,確定m個alpha
iter=0#用于計算迭代次數(shù)
while (iter<maxIter):#當?shù)螖?shù)小于最大迭代次數(shù)時(外循環(huán))
alphaPairsChanged=0#初始化alpha的改變量為0
for i in range(m):#內(nèi)循環(huán)
fXi=float(multiply(alpha,labelMat).T*\
(dataMatrix*dataMatrix[i,:].T))+b#計算f(xi)
Ei=fXi-float(labelMat[i])#計算f(xi)與標簽之間的誤差
if ((labelMat[i]*Ei<-toler)and(alpha[i]<C))or\
((labelMat[i]*Ei>toler)and(alpha[i]>0)):#如果可以進行優(yōu)化
j=selectJrand(i,m)#隨機選擇一個j與i配對
fXj=float(multiply(alpha,labelMat).T*\
(dataMatrix*dataMatrix[j,:].T))+b#計算f(xj)
Ej=fXj-float(labelMat[j])#計算j的誤差
alphaIold=alpha[i].copy()#保存原來的alpha(i)
alphaJold=alpha[j].copy()
if(labelMat[i]!=labelMat[j]):#保證alpha在0到c之間
L=max(0,alpha[j]-alpha[i])
H=min(C,C+alpha[j]-alpha[i])
else:
L=max(0,alpha[j]+alpha[i]-C)
H=min(C,alpha[j]+alpha[i])
if L==H:print('L=H');continue
eta=2*dataMatrix[i,:]*dataMatrix[j,:].T-\
dataMatrix[i,:]*dataMatrix[i,:].T-\
dataMatrix[j,:]*dataMatrix[j,:].T
if eta>=0:print('eta=0');continue
alpha[j]-=labelMat[j]*(Ei-Ej)/eta
alpha[j]=clipAlpha(alpha[j],H,L)#調(diào)整大于H或小于L的alpha
if (abs(alpha[j]-alphaJold)<0.0001):
print('j not move enough');continue
alpha[i]+=labelMat[j]*labelMat[i]*(alphaJold-alpha[j])
b1=b-Ei-labelMat[i]*(alpha[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[i,:].T-\
labelMat[j]*(alpha[j]-alphaJold)*\
dataMatrix[i,:]*dataMatrix[j,:].T#設(shè)置b
b2=b-Ej-labelMat[i]*(alpha[i]-alphaIold)*\
dataMatrix[i,:]*dataMatrix[i,:].T-\
labelMat[j]*(alpha[j]-alphaJold)*\
dataMatrix[j,:]*dataMatrix[j,:].T
if (0<alpha[i])and(C>alpha[j]):b=b1
elif(0<alpha[j])and(C>alpha[j]):b=b2
else:b=(b1+b2)/2
alphaPairsChanged+=1
print('iter:%d i:%d,pairs changed%d'%(iter,i,alphaPairsChanged))
if (alphaPairsChanged==0):iter+=1
else:iter=0
print('iteraction number:%d'%iter)
return b,alpha
#定義徑向基函數(shù)
def kernelTrans(X, A, kTup):#定義核轉(zhuǎn)換函數(shù)(徑向基函數(shù))
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #線性核K為m*1的矩陣
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- \
That Kernel is not recognized')
return K
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei):
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei]
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy()
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print("L==H"); return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0: print("eta>=0"); return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print("j not moving enough"); return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
#smoP函數(shù)用于計算超平的alpha,b
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #完整的Platter SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0#計算循環(huán)的次數(shù)
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print("fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print("non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged))
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print("iteration number: %d" % iter)
return oS.b,oS.alphas
#calcWs用于計算權(quán)重值w
def calcWs(alphas,dataArr,classLabels):#計算權(quán)重W
X = mat(dataArr); labelMat = mat(classLabels).transpose()
m,n = shape(X)
w = zeros((n,1))
for i in range(m):
w += multiply(alphas[i]*labelMat[i],X[i,:].T)
return w
#值得注意的是測試準確與k1和C的取值有關(guān)�。
def testRbf(k1=1.3):#給定輸入?yún)?shù)K1
#測試訓練集上的準確率
dataArr,labelArr = loadDataSet('testSetRBF.txt')#導入數(shù)據(jù)作為訓練集
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]#找出alphas中大于0的元素的位置
#此處需要說明一下alphas.A的含義
sVs=datMat[svInd] #獲取支持向量的矩陣�����,因為只要alpha中不等于0的元素都是支持向量
labelSV = labelMat[svInd]#支持向量的標簽
print("there are %d Support Vectors" % shape(sVs)[0])#輸出有多少個支持向量
m,n = shape(datMat)#數(shù)據(jù)組的矩陣形狀表示為有m個數(shù)據(jù)��,數(shù)據(jù)維數(shù)為n
errorCount = 0#計算錯誤的個數(shù)
for i in range(m):#開始分類���,是函數(shù)的核心
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))#計算原數(shù)據(jù)集中各元素的核值
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b#計算預(yù)測結(jié)果y的值
if sign(predict)!=sign(labelArr[i]): errorCount += 1#利用符號判斷類別
### sign(a)為符號函數(shù):若a>0則輸出1�����,若a<0則輸出-1.###
print("the training error rate is: %f" % (float(errorCount)/m))
#2��、測試測試集上的準確率
dataArr,labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr)#labelMat = mat(labelArr).transpose()此處可以不用
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print("the test error rate is: %f" % (float(errorCount)/m))
def main():
t1=time()
dataArr,labelArr=loadDataSet('testSet.txt')
b,alphas=smoP(dataArr,labelArr,0.6,0.01,40)
ws=calcWs(alphas,dataArr,labelArr)
testRbf()
t2=time()
print("程序所用時間為%ss"%(t2-t1))
if __name__=='__main__':
main()
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認證考試����,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330