在機(jī)器學(xué)習(xí)中�,因為決策樹的算法是十分給力,因此使用決策樹能夠幫助我們解決很多的問題���。決策樹的算法分為很多種����,今天小編主要跟大家介紹一下決策樹的分類算法�。
一��、決策樹的概念
決策樹�,根據(jù)名字就能知道�����,是一種樹���,一種依托于策略抉擇而建立起來的樹�。在 機(jī)器學(xué)習(xí)中�,決策樹是一個預(yù)測模型,代表的是對象屬性與對象值之間的一種映射關(guān)系��。從數(shù)據(jù)產(chǎn)生決策樹的機(jī)器學(xué)習(xí)技術(shù)叫做決策樹學(xué)習(xí), 通俗點(diǎn)說就是:決策樹是一種依托于分類�����、訓(xùn)練上的預(yù)測樹��,可以根據(jù)已知�,對未來進(jìn)行預(yù)測、歸類����。
舉一個簡單的例子來說明:
一個女孩選擇相親對象���,通過年齡是否超過30、長相丑或不丑��、收入是否低水平��,以及否是公務(wù)員這幾項���,將相親對象分為兩個類別:見和不見。假設(shè)這個女孩對相親對象的要求為:30歲以下����、長相不丑,而且高收入���,或者中等以上收入的公務(wù)員�,那么女孩的決策邏輯可以用下圖來表示�����,典型的分類決策樹�。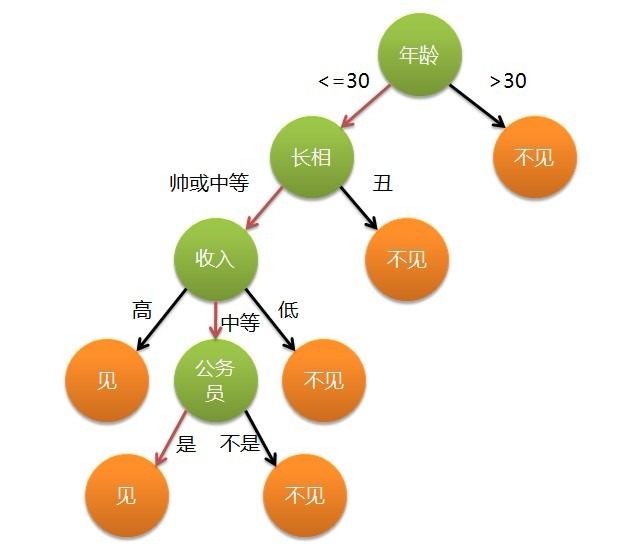
二、決策樹分類算法
決策樹分類主要有ID3.C4.5.CART這三種
1. ID3選取信息增益的屬性遞歸進(jìn)行分類
“熵”表示隨機(jī)變量不確定性的度量���,并且熵只依賴于X的分布�����,與X具體取值無關(guān)����,所以可以表示為,熵越大���,隨機(jī)變量的不確定性就越大:
信息熵: H(X)=-sigma(對每一個x)(plogp)
“條件熵H(Y|X)”表示在已知隨機(jī)變量X的條件下��,隨機(jī)變量Y的不確定性:
H(Y|X)=sigma(對每一個x)(pH(Y|X=xi))
“信息增益”特征A對訓(xùn)練數(shù)據(jù)集D的信息增益g(D,A)�����,具體定義為:集合D的經(jīng)驗熵H(D)�,和特征A給定條件下D的經(jīng)驗條件熵H(D)熵
信息增益:g(D,A)=H(D)-H(D|A) H(D)為整個數(shù)據(jù)集的熵
信息增益率:(H(D)-H(D|X))/H(X)
算法流程:(1)計算每一個屬性的信息增益��,如果信息增益小于閾值��,就將該支置為葉節(jié)點(diǎn)��,選擇其中個數(shù)最多的類標(biāo)簽來作為該類的類標(biāo)簽�。反之��,則選擇其中最大的作為分類屬 性�����。
(2)若果各個分支中都只含有同一類數(shù)據(jù)��,那么就將這支置為葉子節(jié)點(diǎn)�����, 否則 繼續(xù)進(jìn)行(1)。
2. C4.5算法
C4.5算法是ID3的改進(jìn)算法 �����, 是機(jī)器學(xué)習(xí)算法中的另一個分類決策樹算法�,可以說是決策樹核心算法。
C4.5算法特點(diǎn):
C4.5用信息增益率來選擇屬性����。
能處理非離散數(shù)據(jù)。
能夠處理不完整數(shù)據(jù)進(jìn)行
一個可以選擇的度量標(biāo)準(zhǔn)是增益比率gain ratio(Quinlan 1986)��。增益比率度量是用前面的增益度量Gain(S��,A)和分裂信息度量SplitInformation(S,A)來共同定義的�����,如下所示:
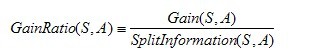
其中����,分裂信息度量被定義為(分裂信息用來衡量屬性分裂數(shù)據(jù)的廣度和均勻):
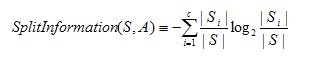
C4.5算法構(gòu)造決策樹過程:
Function C4.5(R:包含連續(xù)屬性的無類別屬性集合,C:類別屬性,S:訓(xùn)練集)
/*返回一棵決策樹*/
Begin
If S為空,返回一個值為Failure的單個節(jié)點(diǎn);
If S是由相同類別屬性值的記錄組成,
返回一個帶有該值的單個節(jié)點(diǎn);
If R為空,則返回一個單節(jié)點(diǎn),其值為在S的記錄中找出的頻率最高的類別屬性值;
[注意未出現(xiàn)錯誤則意味著是不適合分類的記錄];
For 所有的屬性R(Ri) Do
If 屬性Ri為連續(xù)屬性,則
Begin
將Ri的最小值賦給A1:
將Rm的最大值賦給Am;/*m值手工設(shè)置*/
For j From 2 To m-1 Do Aj=A1+j*(A1Am)/m;
將Ri點(diǎn)的基于{< =Aj,>Aj}的最大信息增益屬性(Ri,S)賦給A;
End;
將R中屬性之間具有最大信息增益的屬性(D,S)賦給D;
將屬性D的值賦給{dj/j=1.2...m};
將分別由對應(yīng)于D的值為dj的記錄組成的S的子集賦給{sj/j=1.2...m};
返回一棵樹�,其根標(biāo)記為D;樹枝標(biāo)記為d1.d2...dm;
再分別構(gòu)造以下樹:
C4.5(R-{D},C,S1),C4.5(R-{D},C,S2)...C4.5(R-{D},C,Sm);
End C4.5
3.CART算法:
基尼系數(shù):Gini(p)=sigma(每一個類)p(1-p)
回歸樹:屬性值為連續(xù)實(shí)數(shù)。將整個輸入空間劃分為m塊����,每一塊以其平均值作為輸出。f(x)=sigma(每一塊)Cm*I(x屬于Rm)
回歸樹生成:(1)選取切分變量和切分點(diǎn)����,將輸入空間分為兩份。
(2)每一份分別進(jìn)行第一步�����,直到滿足停止條件����。
切分變量和切分點(diǎn)選?��。簩τ诿恳粋€變量進(jìn)行遍歷,從中選擇切分點(diǎn)�����。選擇一個切分點(diǎn)滿足分類均方誤差最小��。然后在選出所有變量中最小分類誤差最小的變量作為切分 變量����。
分類樹:屬性值為離散值。
分類樹生成:(1)根據(jù)每一個屬性的每一個取值��,是否取該值將樣本分成兩類�����,計算基尼系數(shù)�����。選擇基尼系數(shù)最小的特征和屬性值��,將樣本分成兩份�。
(2)遞歸調(diào)用(1)直到無法分割。完成CART樹生成��。
四���、python實(shí)現(xiàn)
from sklearn.datasets import load_iris
import numpy as np
import math
from collections import Counter
class decisionnode:
def __init__(self, d=None, thre=None, results=None, NH=None, lb=None, rb=None, max_label=None):
self.d = d # d表示維度
self.thre = thre # thre表示二分時的比較值����,將樣本集分為2類
self.results = results # 最后的葉節(jié)點(diǎn)代表的類別
self.NH = NH # 存儲各節(jié)點(diǎn)的樣本量與經(jīng)驗熵的乘積���,便于剪枝時使用
self.lb = lb # desision node,對應(yīng)于樣本在d維的數(shù)據(jù)小于thre時�����,樹上相對于當(dāng)前節(jié)點(diǎn)的子樹上的節(jié)點(diǎn)
self.rb = rb # desision node,對應(yīng)于樣本在d維的數(shù)據(jù)大于thre時��,樹上相對于當(dāng)前節(jié)點(diǎn)的子樹上的節(jié)點(diǎn)
self.max_label = max_label # 記錄當(dāng)前節(jié)點(diǎn)包含的label中同類最多的label
def entropy(y):
'''
計算信息熵��,y為labels
'''
if y.size > 1:
category = list(set(y))
else:
category = [y.item()]
y = [y.item()]
ent = 0
for label in category:
p = len([label_ for label_ in y if label_ == label]) / len(y)
ent += -p * math.log(p, 2)
return ent
def Gini(y):
'''
計算基尼指數(shù)���,y為labels
'''
category = list(set(y))
gini = 1
for label in category:
p = len([label_ for label_ in y if label_ == label]) / len(y)
gini += -p * p
return gini
def GainEnt_max(X, y, d):
'''
計算選擇屬性attr的最大信息增益,X為樣本集,y為label����,d為一個維度��,type為int
'''
ent_X = entropy(y)
X_attr = X[:, d]
X_attr = list(set(X_attr))
X_attr = sorted(X_attr)
Gain = 0
thre = 0
for i in range(len(X_attr) - 1):
thre_temp = (X_attr[i] + X_attr[i + 1]) / 2
y_small_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] <= thre_temp]
y_big_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] > thre_temp]
y_small = y[y_small_index]
y_big = y[y_big_index]
Gain_temp = ent_X - (len(y_small) / len(y)) * \
entropy(y_small) - (len(y_big) / len(y)) * entropy(y_big)
'''
intrinsic_value = -(len(y_small) / len(y)) * math.log(len(y_small) /
len(y), 2) - (len(y_big) / len(y)) * math.log(len(y_big) / len(y), 2)
Gain_temp = Gain_temp / intrinsic_value
'''
# print(Gain_temp)
if Gain < Gain_temp:
Gain = Gain_temp
thre = thre_temp
return Gain, thre
def Gini_index_min(X, y, d):
'''
計算選擇屬性attr的最小基尼指數(shù)����,X為樣本集,y為label�,d為一個維度,type為int
'''
X = X.reshape(-1, len(X.T))
X_attr = X[:, d]
X_attr = list(set(X_attr))
X_attr = sorted(X_attr)
Gini_index = 1
thre = 0
for i in range(len(X_attr) - 1):
thre_temp = (X_attr[i] + X_attr[i + 1]) / 2
y_small_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] <= thre_temp]
y_big_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] > thre_temp]
y_small = y[y_small_index]
y_big = y[y_big_index]
Gini_index_temp = (len(y_small) / len(y)) * \
Gini(y_small) + (len(y_big) / len(y)) * Gini(y_big)
if Gini_index > Gini_index_temp:
Gini_index = Gini_index_temp
thre = thre_temp
return Gini_index, thre
def attribute_based_on_GainEnt(X, y):
'''
基于信息增益選擇最優(yōu)屬性�,X為樣本集,y為label
'''
D = np.arange(len(X[0]))
Gain_max = 0
thre_ = 0
d_ = 0
for d in D:
Gain, thre = GainEnt_max(X, y, d)
if Gain_max < Gain:
Gain_max = Gain
thre_ = thre
d_ = d # 維度標(biāo)號
return Gain_max, thre_, d_
def attribute_based_on_Giniindex(X, y):
'''
基于信息增益選擇最優(yōu)屬性�����,X為樣本集�����,y為label
'''
D = np.arange(len(X.T))
Gini_Index_Min = 1
thre_ = 0
d_ = 0
for d in D:
Gini_index, thre = Gini_index_min(X, y, d)
if Gini_Index_Min > Gini_index:
Gini_Index_Min = Gini_index
thre_ = thre
d_ = d # 維度標(biāo)號
return Gini_Index_Min, thre_, d_
def devide_group(X, y, thre, d):
'''
按照維度d下閾值為thre分為兩類并返回
'''
X_in_d = X[:, d]
x_small_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] <= thre]
x_big_index = [i_arg for i_arg in range(
len(X[:, d])) if X[i_arg, d] > thre]
X_small = X[x_small_index]
y_small = y[x_small_index]
X_big = X[x_big_index]
y_big = y[x_big_index]
return X_small, y_small, X_big, y_big
def NtHt(y):
'''
計算經(jīng)驗熵與樣本數(shù)的乘積���,用來剪枝�,y為labels
'''
ent = entropy(y)
print('ent={},y_len={},all={}'.format(ent, len(y), ent * len(y)))
return ent * len(y)
def maxlabel(y):
label_ = Counter(y).most_common(1)
return label_[0][0]
def buildtree(X, y, method='Gini'):
'''
遞歸的方式構(gòu)建決策樹
'''
if y.size > 1:
if method == 'Gini':
Gain_max, thre, d = attribute_based_on_Giniindex(X, y)
elif method == 'GainEnt':
Gain_max, thre, d = attribute_based_on_GainEnt(X, y)
if (Gain_max > 0 and method == 'GainEnt') or (Gain_max >= 0 and len(list(set(y))) > 1 and method == 'Gini'):
X_small, y_small, X_big, y_big = devide_group(X, y, thre, d)
left_branch = buildtree(X_small, y_small, method=method)
right_branch = buildtree(X_big, y_big, method=method)
nh = NtHt(y)
max_label = maxlabel(y)
return decisionnode(d=d, thre=thre, NH=nh, lb=left_branch, rb=right_branch, max_label=max_label)
else:
nh = NtHt(y)
max_label = maxlabel(y)
return decisionnode(results=y[0], NH=nh, max_label=max_label)
else:
nh = NtHt(y)
max_label = maxlabel(y)
return decisionnode(results=y.item(), NH=nh, max_label=max_label)
def printtree(tree, indent='-', dict_tree={}, direct='L'):
# 是否是葉節(jié)點(diǎn)
if tree.results != None:
print(tree.results)
dict_tree = {direct: str(tree.results)}
else:
# 打印判斷條件
print(str(tree.d) + ":" + str(tree.thre) + "? ")
# 打印分支
print(indent + "L->",)
a = printtree(tree.lb, indent=indent + "-", direct='L')
aa = a.copy()
print(indent + "R->",)
b = printtree(tree.rb, indent=indent + "-", direct='R')
bb = b.copy()
aa.update(bb)
stri = str(tree.d) + ":" + str(tree.thre) + "?"
if indent != '-':
dict_tree = {direct: {stri: aa}}
else:
dict_tree = {stri: aa}
return dict_tree
def classify(observation, tree):
if tree.results != None:
return tree.results
else:
v = observation[tree.d]
branch = None
if v > tree.thre:
branch = tree.rb
else:
branch = tree.lb
return classify(observation, branch)
def pruning(tree, alpha=0.1):
if tree.lb.results == None:
pruning(tree.lb, alpha)
if tree.rb.results == None:
pruning(tree.rb, alpha)
if tree.lb.results != None and tree.rb.results != None:
before_pruning = tree.lb.NH + tree.rb.NH + 2 * alpha
after_pruning = tree.NH + alpha
print('before_pruning={},after_pruning={}'.format(
before_pruning, after_pruning))
if after_pruning <= before_pruning:
print('pruning--{}:{}?'.format(tree.d, tree.thre))
tree.lb, tree.rb = None, None
tree.results = tree.max_label
if __name__ == '__main__':
iris = load_iris()
X = iris.data
y = iris.target
permutation = np.random.permutation(X.shape[0])
shuffled_dataset = X[permutation, :]
shuffled_labels = y[permutation]
train_data = shuffled_dataset[:100, :]
train_label = shuffled_labels[:100]
test_data = shuffled_dataset[100:150, :]
test_label = shuffled_labels[100:150]
tree1 = buildtree(train_data, train_label, method='Gini')
print('=============================')
tree2 = buildtree(train_data, train_label, method='GainEnt')
a = printtree(tree=tree1)
b = printtree(tree=tree2)
true_count = 0
for i in range(len(test_label)):
predict = classify(test_data[i], tree1)
if predict == test_label[i]:
true_count += 1
print("CARTTree:{}".format(true_count))
true_count = 0
for i in range(len(test_label)):
predict = classify(test_data[i], tree2)
if predict == test_label[i]:
true_count += 1
print("C3Tree:{}".format(true_count))
#print(attribute_based_on_Giniindex(X[49:51, :], y[49:51]))
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默認(rèn)字體
mpl.rcParams['axes.unicode_minus'] = False # 解決保存圖像時負(fù)號'-'顯示為方塊的問題
import treePlotter
import matplotlib.pyplot as plt
treePlotter.createPlot(a, 1)
treePlotter.createPlot(b, 2)
# 剪枝處理
pruning(tree=tree1, alpha=4)
pruning(tree=tree2, alpha=4)
a = printtree(tree=tree1)
b = printtree(tree=tree2)
true_count = 0
for i in range(len(test_label)):
predict = classify(test_data[i], tree1)
if predict == test_label[i]:
true_count += 1
print("CARTTree:{}".format(true_count))
true_count = 0
for i in range(len(test_label)):
predict = classify(test_data[i], tree2)
if predict == test_label[i]:
true_count += 1
print("C3Tree:{}".format(true_count))
treePlotter.createPlot(a, 3)
treePlotter.createPlot(b, 4)
plt.show()
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報名CDA認(rèn)證考試�,點(diǎn)擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫��,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量���,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330