用Apache Spark進(jìn)行大數(shù)據(jù)處理—入門篇
Apache Spark 是一個(gè)圍繞速度��、易用性和復(fù)雜分析構(gòu)建的大數(shù)據(jù)處理框架。最初在2009年由加州大學(xué)伯克利分校的AMPLab開發(fā)�����,并于2010年成為Apache的開源項(xiàng)目之一���。
與Hadoop和Storm等其他大數(shù)據(jù)和MapReduce技術(shù)相比���,Spark有如下優(yōu)勢��。
首先�,Spark為我們提供了一個(gè)全面��、統(tǒng)一的框架用于管理各種有著不同性質(zhì)(文本數(shù)據(jù)����、圖表數(shù)據(jù)等)的數(shù)據(jù)集和數(shù)據(jù)源(批量數(shù)據(jù)或?qū)崟r(shí)的流數(shù)據(jù))的大數(shù)據(jù)處理的需求。
Spark可以將Hadoop集群中的應(yīng)用在內(nèi)存中的運(yùn)行速度提升100倍���,甚至能夠?qū)?yīng)用在磁盤上的運(yùn)行速度提升10倍���。
Spark讓開發(fā)者可以快速的用Java、Scala或Python編寫程序����。它本身自帶了一個(gè)超過80個(gè)高階操作符集合。而且還可以用它在shell中以交互式地查詢數(shù)據(jù)����。
除了Map和Reduce操作之外,它還支持SQL查詢,流數(shù)據(jù)����,機(jī)器學(xué)習(xí)和圖表數(shù)據(jù)處理。開發(fā)者可以在一個(gè)數(shù)據(jù)管道用例中單獨(dú)使用某一能力或者將這些能力結(jié)合在一起使用�。
在這個(gè)Apache Spark文章系列的第一部分中,我們將了解到什么是Spark�����,它與典型的MapReduce解決方案的比較以及它如何為大數(shù)據(jù)處理提供了一套完整的工具��。
Hadoop和Spark
Hadoop這項(xiàng)大數(shù)據(jù)處理技術(shù)大概已有十年歷史����,而且被看做是首選的大數(shù)據(jù)集合處理的解決方案。MapReduce是一路計(jì)算的優(yōu)秀解決方案��,不過對于需要多路計(jì)算和算法的用例來說�,并非十分高效。數(shù)據(jù)處理流程中的每一步都需要一個(gè)Map階段和一個(gè)Reduce階段��,而且如果要利用這一解決方案�����,需要將所有用例都轉(zhuǎn)換成MapReduce模式�����。
在下一步開始之前�����,上一步的作業(yè)輸出數(shù)據(jù)必須要存儲(chǔ)到分布式文件系統(tǒng)中��。因此��,復(fù)制和磁盤存儲(chǔ)會(huì)導(dǎo)致這種方式速度變慢��。另外Hadoop解決方案中通常會(huì)包含難以安裝和管理的集群�。而且為了處理不同的大數(shù)據(jù)用例,還需要集成多種不同的工具(如用于機(jī)器學(xué)習(xí)的Mahout和流數(shù)據(jù)處理的Storm)�。
如果想要完成比較復(fù)雜的工作,就必須將一系列的MapReduce作業(yè)串聯(lián)起來然后順序執(zhí)行這些作業(yè)���。每一個(gè)作業(yè)都是高時(shí)延的�,而且只有在前一個(gè)作業(yè)完成之后下一個(gè)作業(yè)才能開始啟動(dòng)��。
而Spark則允許程序開發(fā)者使用有向無環(huán)圖( DAG )開發(fā)復(fù)雜的多步數(shù)據(jù)管道��。而且還支持跨有向無環(huán)圖的內(nèi)存數(shù)據(jù)共享,以便不同的作業(yè)可以共同處理同一個(gè)數(shù)據(jù)���。
Spark運(yùn)行在現(xiàn)有的Hadoop分布式文件系統(tǒng)基礎(chǔ)之上( HDFS )提供額外的增強(qiáng)功能��。它支持 將Spark應(yīng)用部署到 現(xiàn)存的Hadoop v1集群(with SIMR – Spark-Inside-MapReduce)或Hadoop v2 YARN集群甚至是 Apache Mesos 之中�。
我們應(yīng)該將Spark看作是Hadoop MapReduce的一個(gè)替代品而不是Hadoop的替代品��。其意圖并非是替代Hadoop���,而是為了提供一個(gè)管理不同的大數(shù)據(jù)用例和需求的全面且統(tǒng)一的解決方案����。
Spark特性
Spark通過在數(shù)據(jù)處理過程中成本更低的洗牌(Shuffle)方式�����,將MapReduce提升到一個(gè)更高的層次�。利用內(nèi)存數(shù)據(jù)存儲(chǔ)和接近實(shí)時(shí)的處理能力,Spark比其他的大數(shù)據(jù)處理技術(shù)的性能要快很多倍�����。
Spark還支持大數(shù)據(jù)查詢的延遲計(jì)算��,這可以幫助優(yōu)化大數(shù)據(jù)處理流程中的處理步驟���。Spark還提供高級的API以提升開發(fā)者的生產(chǎn)力�����,除此之外還為大數(shù)據(jù)解決方案提供一致的體系架構(gòu)模型��。
Spark將中間結(jié)果保存在內(nèi)存中而不是將其寫入磁盤�,當(dāng)需要多次處理同一數(shù)據(jù)集時(shí)����,這一點(diǎn)特別實(shí)用。Spark的設(shè)計(jì)初衷就是既可以在內(nèi)存中又可以在磁盤上工作的執(zhí)行引擎��。當(dāng)內(nèi)存中的數(shù)據(jù)不適用時(shí)�����,Spark操作符就會(huì)執(zhí)行外部操作�����。Spark可以用于處理大于集群內(nèi)存容量總和的數(shù)據(jù)集���。
Spark會(huì)嘗試在內(nèi)存中存儲(chǔ)盡可能多的數(shù)據(jù)然后將其寫入磁盤����。它可以將某個(gè)數(shù)據(jù)集的一部分存入內(nèi)存而剩余部分存入磁盤。開發(fā)者需要根據(jù)數(shù)據(jù)和用例評估對內(nèi)存的需求�。Spark的性能優(yōu)勢得益于這種內(nèi)存中的數(shù)據(jù)存儲(chǔ)。
Spark的其他特性包括:
·支持比Map和Reduce更多的函數(shù)����。
·優(yōu)化任意操作算子圖(operator graphs)。
·可以幫助優(yōu)化整體數(shù)據(jù)處理流程的大數(shù)據(jù)查詢的延遲計(jì)算��。
·提供簡明��、一致的Scala���,Java和Python API��。
·提供交互式Scala和Python Shell����。目前暫不支持Java�。
Spark是用 Scala程序設(shè)計(jì)語言 編寫而成,運(yùn)行于Java虛擬機(jī)(JVM)環(huán)境之上�����。目前支持如下程序設(shè)計(jì)語言編寫Spark應(yīng)用:
·Scala
·Java
·Python
·Clojure
·R
Spark生態(tài)系統(tǒng)
除了Spark核心API之外,Spark生態(tài)系統(tǒng)中還包括其他附加庫����,可以在大數(shù)據(jù)分析和機(jī)器學(xué)習(xí)領(lǐng)域提供更多的能力���。
這些庫包括:
·Spark Streaming:
Spark Streaming 基于微批量方式的計(jì)算和處理�����,可以用于處理實(shí)時(shí)的流數(shù)據(jù)��。它使用DStream��,簡單來說就是一個(gè)彈性分布式數(shù)據(jù)集(RDD)系列�,處理實(shí)時(shí)數(shù)據(jù)��。
·Spark SQL:
Spark SQL 可以通過JDBC API將Spark數(shù)據(jù)集暴露出去�����,而且還可以用傳統(tǒng)的BI和可視化工具在Spark數(shù)據(jù)上執(zhí)行類似SQL的查詢�����。用戶還可以用Spark SQL對不同格式的數(shù)據(jù)(如JSON,Parquet以及數(shù)據(jù)庫等)執(zhí)行ETL��,將其轉(zhuǎn)化��,然后暴露給特定的查詢�。
·Spark MLlib:
MLlib 是一個(gè)可擴(kuò)展的Spark機(jī)器學(xué)習(xí)庫,由通用的學(xué)習(xí)算法和工具組成����,包括二元分類、線性回歸����、聚類、協(xié)同過濾�、梯度下降以及底層優(yōu)化原語。
·Spark GraphX:
GraphX 是用于圖計(jì)算和并行圖計(jì)算的新的(alpha)Spark API����。通過引入彈性分布式屬性圖(Resilient Distributed Property Graph),一種頂點(diǎn)和邊都帶有屬性的有向多重圖�,擴(kuò)展了Spark RDD。為了支持圖計(jì)算�����,GraphX暴露了一個(gè)基礎(chǔ)操作符集合(如subgraph,joinVertices和aggregateMessages)和一個(gè)經(jīng)過優(yōu)化的Pregel API變體�����。此外�,GraphX還包括一個(gè)持續(xù)增長的用于簡化圖分析任務(wù)的圖算法和構(gòu)建器集合����。
除了這些庫以外,還有一些其他的庫��,如BlinkDB和Tachyon�����。
BlinkDB 是一個(gè)近似查詢引擎���,用于在海量數(shù)據(jù)上執(zhí)行交互式SQL查詢�。BlinkDB可以通過犧牲數(shù)據(jù)精度來提升查詢響應(yīng)時(shí)間���。通過在數(shù)據(jù)樣本上執(zhí)行查詢并展示包含有意義的錯(cuò)誤線注解的結(jié)果���,操作大數(shù)據(jù)集合�。
Tachyon 是一個(gè)以內(nèi)存為中心的分布式文件系統(tǒng)�����,能夠提供內(nèi)存級別速度的跨集群框架(如Spark和MapReduce)的可信文件共享��。它將工作集文件緩存在內(nèi)存中�,從而避免到磁盤中加載需要經(jīng)常讀取的數(shù)據(jù)集。通過這一機(jī)制���,不同的作業(yè)/查詢和框架可以以內(nèi)存級的速度訪問緩存的文件��。
此外���,還有一些用于與其他產(chǎn)品集成的適配器,如Cassandra( Spark Cassandra 連接器 )和R(SparkR)�����。Cassandra Connector可用于訪問存儲(chǔ)在Cassandra數(shù)據(jù)庫中的數(shù)據(jù)并在這些數(shù)據(jù)上執(zhí)行數(shù)據(jù)分析���。
下圖展示了在Spark生態(tài)系統(tǒng)中����,這些不同的庫之間的相互關(guān)聯(lián)。
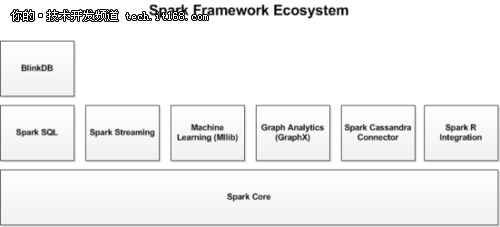
▲圖1 Spark 框架中的庫
我們將在這一系列文章中逐步探索這些Spark庫
Spark體系架構(gòu)
Spark體系架構(gòu)包括如下三個(gè)主要組件:
·數(shù)據(jù)存儲(chǔ)
·API
·管理框架
接下來讓我們詳細(xì)了解一下這些組件��。
數(shù)據(jù)存儲(chǔ):
Spark用HDFS文件系統(tǒng)存儲(chǔ)數(shù)據(jù)��。它可用于存儲(chǔ)任何兼容于Hadoop的數(shù)據(jù)源����,包括HDFS,HBase��,Cassandra等����。
API:
利用API��,應(yīng)用開發(fā)者可以用標(biāo)準(zhǔn)的API接口創(chuàng)建基于Spark的應(yīng)用����。Spark提供Scala,Java和Python三種程序設(shè)計(jì)語言的API�。
下面是三種語言Spark API的網(wǎng)站鏈接。
·Scala API
·Java
·Python
資源管理:
Spark既可以部署在一個(gè)單獨(dú)的服務(wù)器也可以部署在像Mesos或YARN這樣的分布式計(jì)算框架之上。
下圖2展示了Spark體系架構(gòu)模型中的各個(gè)組件��。
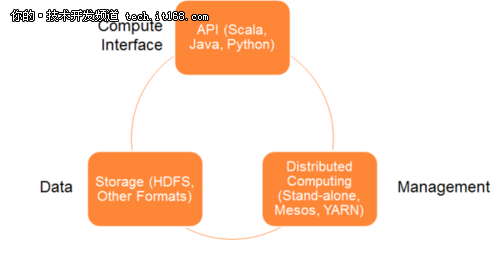
▲圖2 Spark體系架構(gòu)
彈性分布式數(shù)據(jù)集
彈性分布式數(shù)據(jù)集 (基于Matei的 研究論文 )或RDD是Spark框架中的核心概念�����??梢詫?a href='/map/rdd/' style='color:#000;font-size:inherit;'>RDD視作數(shù)據(jù)庫中的一張表。其中可以保存任何類型的數(shù)據(jù)����。Spark將數(shù)據(jù)存儲(chǔ)在不同分區(qū)上的RDD之中。
RDD可以幫助重新安排計(jì)算并優(yōu)化數(shù)據(jù)處理過程��。
此外���,它還具有容錯(cuò)性�,因?yàn)?a href='/map/rdd/' style='color:#000;font-size:inherit;'>RDD知道如何重新創(chuàng)建和重新計(jì)算數(shù)據(jù)集��。
RDD是不可變的����。你可以用變換(Transformation)修改RDD,但是這個(gè)變換所返回的是一個(gè)全新的RDD��,而原有的RDD仍然保持不變。
RDD支持兩種類型的操作:
·變換(Transformation)
·行動(dòng)(Action)
變換: 變換的返回值是一個(gè)新的RDD集合���,而不是單個(gè)值����。調(diào)用一個(gè)變換方法����,不會(huì)有任何求值計(jì)算,它只獲取一個(gè)RDD作為參數(shù)���,然后返回一個(gè)新的RDD�。
變換函數(shù)包括:map�����,filter�����,flatMap�����,groupByKey����,reduceByKey,aggregateByKey��,pipe和coalesce���。
行動(dòng): 行動(dòng)操作計(jì)算并返回一個(gè)新的值��。當(dāng)在一個(gè)RDD對象上調(diào)用行動(dòng)函數(shù)時(shí)��,會(huì)在這一時(shí)刻計(jì)算全部的數(shù)據(jù)處理查詢并返回結(jié)果值�����。
行動(dòng)操作包括:reduce���,collect,count��,first����,take�����,countByKey以及foreach����。
如何安裝Spark
安裝和使用Spark有幾種不同方式�����。你可以在自己的電腦上將Spark作為一個(gè)獨(dú)立的框架安裝或者從諸如 Cloudera ���,HortonWorks或MapR之類的供應(yīng)商處獲取一個(gè)Spark虛擬機(jī)鏡像直接使用���。或者你也可以使用在云端環(huán)境(如 Databricks Cloud )安裝并配置好的Spark����。
在本文中,我們將把Spark作為一個(gè)獨(dú)立的框架安裝并在本地啟動(dòng)它����。最近Spark剛剛發(fā)布了1.2.0版本�����。我們將用這一版本完成示例應(yīng)用的代碼展示。
如何運(yùn)行Spark
當(dāng)你在本地機(jī)器安裝了Spark或使用了基于云端的Spark后�,有幾種不同的方式可以連接到Spark引擎。
下表展示了不同的Spark運(yùn)行模式所需的Master URL參數(shù)�。

如何與Spark交互
Spark啟動(dòng)并運(yùn)行后,可以用Spark shell連接到Spark引擎進(jìn)行交互式數(shù)據(jù)分析�����。Spark shell支持Scala和Python兩種語言�����。Java不支持交互式的Shell�����,因此這一功能暫未在Java語言中實(shí)現(xiàn)��。
可以用spark-shell.cmd和pyspark.cmd命令分別運(yùn)行Scala版本和Python版本的Spark Shell����。
Spark網(wǎng)頁控制臺(tái)
不論Spark運(yùn)行在哪一種模式下,都可以通過訪問Spark網(wǎng)頁控制臺(tái)查看Spark的作業(yè)結(jié)果和其他的統(tǒng)計(jì)數(shù)據(jù)����,控制臺(tái)的URL地址如下:
http://localhost:4040
Spark控制臺(tái)如下圖3所示���,包括Stages,Storage�����,Environment和Executors四個(gè)標(biāo)簽頁
▲圖3 Spark網(wǎng)頁控制臺(tái)
共享變量
Spark提供兩種類型的共享變量可以提升集群環(huán)境中的Spark程序運(yùn)行效率���。分別是廣播變量和累加器����。
廣播變量: 廣播變量可以在每臺(tái)機(jī)器上緩存只讀變量而不需要為各個(gè)任務(wù)發(fā)送該變量的拷貝��。他們可以讓大的輸入數(shù)據(jù)集的集群拷貝中的節(jié)點(diǎn)更加高效�。
下面的代碼片段展示了如何使用廣播變量。
//
// Broadcast Variables
//
val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar.value
累加器: 只有在使用相關(guān)操作時(shí)才會(huì)添加累加器���,因此它可以很好地支持并行���。累加器可用于實(shí)現(xiàn)計(jì)數(shù)(就像在MapReduce中那樣)或求和。可以用add方法將運(yùn)行在集群上的任務(wù)添加到一個(gè)累加器變量中�����。不過這些任務(wù)無法讀取變量的值����。只有驅(qū)動(dòng)程序才能夠讀取累加器的值��。
下面的代碼片段展示了如何使用累加器共享變量:
//
// Accumulators
//
val accum = sc.accumulator(0, "My Accumulator")
sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
accum.value
Spark應(yīng)用示例
本篇文章中所涉及的示例應(yīng)用是一個(gè)簡單的字?jǐn)?shù)統(tǒng)計(jì)應(yīng)用�����。這與學(xué)習(xí)用Hadoop進(jìn)行大數(shù)據(jù)處理時(shí)的示例應(yīng)用相同�����。我們將在一個(gè)文本文件上執(zhí)行一些數(shù)據(jù)分析查詢�����。本示例中的文本文件和數(shù)據(jù)集都很小��,不過無須修改任何代碼����,示例中所用到的Spark查詢同樣可以用到大容量數(shù)據(jù)集之上��。
為了讓討論盡量簡單�����,我們將使用Spark Scala Shell�����。
首先讓我們看一下如何在你自己的電腦上安裝Spark�����。
前提條件:
·為了讓Spark能夠在本機(jī)正常工作����,你需要安裝Java開發(fā)工具包(JDK)�����。這將包含在下面的第一步中���。
·同樣還需要在電腦上安裝Spark軟件���。下面的第二步將介紹如何完成這項(xiàng)工作����。
注: 下面這些指令都是以Windows環(huán)境為例���。如果你使用不同的操作系統(tǒng)環(huán)境,需要相應(yīng)的修改系統(tǒng)變量和目錄路徑已匹配你的環(huán)境�。
I. 安裝JDK
1)從Oracle網(wǎng)站上下載JDK。推薦使用 JDK 1.7版本 ��。
將JDK安裝到一個(gè)沒有空格的目錄下��。對于Windows用戶���,需要將JDK安裝到像c:\dev這樣的文件夾下���,而不能安裝到“c:\Program Files”文件夾下?����!癱:\Program Files”文件夾的名字中包含空格�,如果軟件安裝到這個(gè)文件夾下會(huì)導(dǎo)致一些問題。
注: 不要 在“c:\Program Files”文件夾中安裝JDK或(第二步中所描述的)Spark軟件。
2)完成JDK安裝后�,切換至JDK 1.7目錄下的”bin“文件夾,然后鍵入如下命令���,驗(yàn)證JDK是否正確安裝:
java -version
如果JDK安裝正確�,上述命令將顯示Java版本���。
II. 安裝Spark軟件:
從 Spark網(wǎng)站 上下載最新版本的Spark����。在本文發(fā)表時(shí)��,最新的Spark版本是1.2��。你可以根據(jù)Hadoop的版本選擇一個(gè)特定的Spark版本安裝�����。我下載了與Hadoop 2.4或更高版本匹配的Spark����,文件名是spark-1.2.0-bin-hadoop2.4.tgz。
將安裝文件解壓到本地文件夾中(如:c:\dev)���。
為了驗(yàn)證Spark安裝的正確性���,切換至Spark文件夾然后用如下命令啟動(dòng)Spark Shell���。這是Windows環(huán)境下的命令。如果使用Linux或Mac OS�,請相應(yīng)地編輯命令以便能夠在相應(yīng)的平臺(tái)上正確運(yùn)行。
c:
cd c:\dev\spark-1.2.0-bin-hadoop2.4
bin\spark-shell
如果Spark安裝正確����,就能夠在控制臺(tái)的輸出中看到如下信息�����。
….
15/01/17 23:17:46 INFO HttpServer: Starting HTTP Server
15/01/17 23:17:46 INFO Utils: Successfully started service 'HTTP class server' on port 58132.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Type :help for more information.
….
15/01/17 23:17:53 INFO BlockManagerMaster: Registered BlockManager
15/01/17 23:17:53 INFO SparkILoop: Created spark context..
Spark context available as sc.
可以鍵入如下命令檢查Spark Shell是否工作正常�����。
sc.version
(或)
sc.appName
完成上述步驟之后�,可以鍵入如下命令退出Spark Shell窗口:
:quit
如果想啟動(dòng)Spark Python Shell,需要先在電腦上安裝Python����。你可以下載并安裝 Anaconda �����,這是一個(gè)免費(fèi)的Python發(fā)行版本�����,其中包括了一些比較流行的科學(xué)�、數(shù)學(xué)、工程和數(shù)據(jù)分析方面的Python包���。
然后可以運(yùn)行如下命令啟動(dòng)Spark Python Shell:
c:
cd c:\dev\spark-1.2.0-bin-hadoop2.4
bin\pyspark
Spark示例應(yīng)用
完成Spark安裝并啟動(dòng)后��,就可以用Spark API執(zhí)行數(shù)據(jù)分析查詢了���。
這些從文本文件中讀取并處理數(shù)據(jù)的命令都很簡單。我們將在這一系列文章的后續(xù)文章中向大家介紹更高級的Spark框架使用的用例�。
首先讓我們用Spark API運(yùn)行流行的Word Count示例。如果還沒有運(yùn)行Spark Scala Shell�����,首先打開一個(gè)Scala Shell窗口��。這個(gè)示例的相關(guān)命令如下所示:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val txtFile = "README.md"
val txtData = sc.textFile(txtFile)
txtData.cache()
我們可以調(diào)用cache函數(shù)將上一步生成的RDD對象保存到緩存中���,在此之后Spark就不需要在每次數(shù)據(jù)查詢時(shí)都重新計(jì)算�����。需要注意的是��,cache()是一個(gè)延遲操作�����。在我們調(diào)用cache時(shí)����,Spark并不會(huì)馬上將數(shù)據(jù)存儲(chǔ)到內(nèi)存中。只有當(dāng)在某個(gè)RDD上調(diào)用一個(gè)行動(dòng)時(shí)����,才會(huì)真正執(zhí)行這個(gè)操作����。
現(xiàn)在,我們可以調(diào)用count函數(shù)�����,看一下在文本文件中有多少行數(shù)據(jù)。
txtData.count()
然后����,我們可以執(zhí)行如下命令進(jìn)行字?jǐn)?shù)統(tǒng)計(jì)。在文本文件中統(tǒng)計(jì)數(shù)據(jù)會(huì)顯示在每個(gè)單詞的后面�。
val wcData = txtData.flatMap(l => l.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
wcData.collect().foreach(println)
后續(xù)計(jì)劃
在后續(xù)的系列文章中,我們將從Spark SQL開始�,學(xué)習(xí)更多關(guān)于Spark生態(tài)系統(tǒng)的其他部分。之后����,我們將繼續(xù)了解Spark Streaming,Spark MLlib和Spark GraphX��。我們也會(huì)有機(jī)會(huì)學(xué)習(xí)像Tachyon和BlinkDB等框架��。
小結(jié)
在本文中���,我們了解了Apache Spark框架如何通過其標(biāo)準(zhǔn)API幫助完成大數(shù)據(jù)處理和分析工作��。我們還對Spark和傳統(tǒng)的MapReduce實(shí)現(xiàn)(如Apache Hadoop)進(jìn)行了比較����。Spark與Hadoop基于相同的HDFS文件存儲(chǔ)系統(tǒng)��,因此如果你已經(jīng)在Hadoop上進(jìn)行了大量投資和基礎(chǔ)設(shè)施建設(shè),可以一起使用Spark和MapReduce����。
此外,也可以將Spark處理與Spark SQL��、機(jī)器學(xué)習(xí)以及Spark Streaming結(jié)合在一起�。關(guān)于這方面的內(nèi)容我們將在后續(xù)的文章中介紹。
利用Spark的一些集成功能和適配器����,我們可以將其他技術(shù)與Spark結(jié)合在一起。其中一個(gè)案例就是將Spark�、Kafka和Apache Cassandra結(jié)合在一起,其中Kafka負(fù)責(zé)輸入的流式數(shù)據(jù)����,Spark完成計(jì)算,最后Cassandra NoSQL數(shù)據(jù)庫用于保存計(jì)算結(jié)果數(shù)據(jù)�。
不過需要牢記的是���,Spark生態(tài)系統(tǒng)仍不成熟��,在安全和與BI工具集成等領(lǐng)域仍然需要進(jìn)一步的改進(jìn)����。
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情�����;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情�����;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330