學Excel可以不去管函數�����,不去管宏�����,只需把握一個要點就可以了:學會設計一張個標準����、正確的源數據表。
我們使用Excel的最終目的�,是為了得到各式各樣用于決策的分類匯總表,一個源數據表完全可以滿足要求�����。它的設計理念卻很簡單��,就是是一張中規(guī)中矩����、填滿數據的一維明細表。
這個表有三大優(yōu)勢:通用���、簡潔�����、規(guī)范��。無論是銷售��、市場數據���,還是物流���、財務數據,都可以用完全相同的方式存放于源數據表中�����,區(qū)別僅僅在于字段名稱和具體內容�����。
一項工作有時可以牽扯出幾十張Excel表���,大量重復數據,卻又沒有一份是完整的�。相反�����,如果堅持一項工作一張表格的原則��,即便與很多數據打交道����,Excel文件也可以很少�����。這樣你可以輕松找到需要的數據���;最大程度避免重復性工作��;業(yè)務數據容易備份和交接�;還可以將“變”表的技能發(fā)揮得淋漓盡致����。
但是要設計這張?zhí)煜碌谝槐恚钪匾馁Y質是工作經驗�����!如果你只在于技能的學習,而忽略了對工作本身的積累和感悟��,最終還是無法駕馭Excel��。
表格毀容五宗罪(內含源數據表制作方法)
第一宗罪:標題的位置不對
我們常常因為過分強調視覺效果����,或者圖一時方便,情不自禁就做出形態(tài)各異的錯誤表格�����,為后續(xù)工作埋下隱患�����。在Excel默認的規(guī)則里�,連續(xù)數據區(qū)域的首行為標題行�,空白工資表首行也被默認為標題行。
但是標題行和標題不同����,前者代表了每列數據的屬性,是篩選和排序的字段依據;而后者只是讓閱讀該表的人知道這是一張什么表��,除此以外不具備任何功能�。所以,不要讓標題占用工作表首行�����。
第二宗罪:令人糾結的填寫順序
之所以會做出一張順序顛倒的表格�,是因為設計的時候忽略了填表流程和工作流程之間的關系。我們在Excel中的動作���,尤其是數據錄入的動作���,必須與工作順序保持一致。
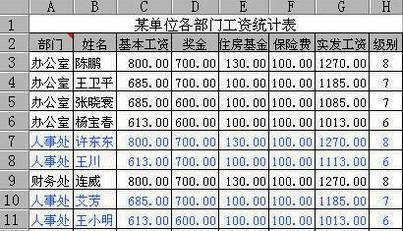
就拿請假這件事來說�,了解員工請假信息的順序通常是:今天是什么日期?請假的是誰�?請的什么假?請幾天�?轉換成Excel字段,就變成日期��、姓名���、請假類型�����、請假天數��。只要把這些字段從左到右依次排列�����,就能得到順序正確的源數據表�。所以只要在設計之前想清楚工作流程,排個順序還不是小case!所謂的設計其實就這么簡單��。
第三宗罪:人為設置的分隔列(類似段落空行)破壞了數據完整性
這種做法會�,在滿足視覺需求的同時,破壞數據的完整性����。
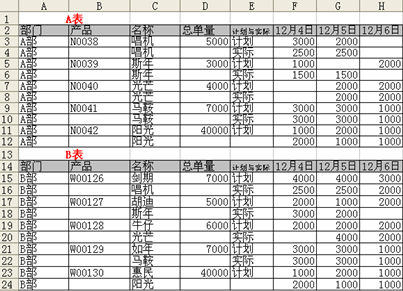
Excel是依據行和列的連續(xù)位置識別數據之間的關聯性,所以當數據被強行分開后����,Excel認為它們之間沒有任何關系����,于是很多分析功能的實現都會受到影響�。姑且不說篩選��、排序��、函數匹配和自動獲得分類匯總表���,一個最直觀的影響就是當你選中一個單元格��,再按Ctrl+A����,本來應該把所有數據全選上的�,現在卻只能選中1/3的數據。僅僅是選中數據這一項工作�,就會因為這些人為的隔斷讓你有得忙。所以�����,對于源數據表�����,保持數據之間的連續(xù)性非常重要。
第四宗罪:合并單元格����。(悲劇啊……身受其害啊……要長記性啊……)
嚴重破壞了數據結構在源數據表中合并單元格,是最常見的操作���?��?蛇@種看似讓數據更加清晰可見的方式,對表格的破壞性卻遠遠勝過前面幾例���。能做出這種表格樣式�,首先是因為缺乏天下第一表的概念����,同時,也離不開對合并功能的長期誤讀����。
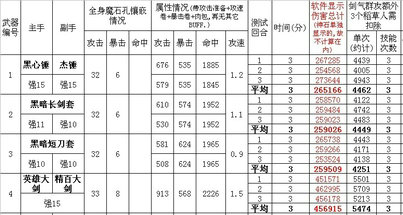
“合并及居中”的使用范圍僅限于需要打印的表單,如招聘表����、調崗申請表����、簽到表等���。而在源數據表中,它被全面禁止使用���,即任何情況下都不需要出現合并單元格���。源數據表里的明細數據必須有一條記錄一條,所有單元格都應該被填滿�,每一行數據都必須完整并且結構整齊,就像話費詳單一樣�。
合并單元格之所以影響數據分析,是因為合并以后�,只有首個單元格有數據,其他的都是空白單元格����。另外,合并單元格還造成整個數據區(qū)域的單元格大小不一����。所以在對數據進行排序時���,Excel會提示錯誤,導致排序功能無法使用�����。
第五宗罪:源數據被分別記錄在不同的工作表
大多數事情都是分時容易聚時難��,Excel也不例外:分開源數據很容易�,合起來就很難。我們就應該把同類型的數據錄入到一張工作表中����,而不要分開記錄。因為源數據表的數據完整性和連貫性����,會直接影響到數據分析的過程和結果。
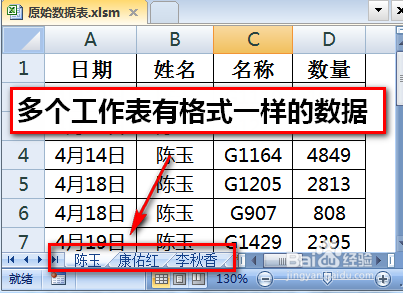
把一年12個月的數據分成12張工作表是出于什么目的�����?為了看著方便���,也容易找到數據�����?錯了�����!放一張工作表里���,篩選一下,也能看著方便��,找著容易�,況且還能運用更多的技能對數據進行分析。
Excel是強大的數據處理軟件����,它有它的規(guī)則。視覺效果固然重要�����,但還是要講究方便實用�。一張工作表提供了數萬行甚至數百萬行(不同版本)的數據空間,足夠你折騰了����。
CDA數據分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�����,點擊>>>
“CDA報名”
了解CDA考試詳情����;
? 想學習CDA考試教材�,點擊>>> “CDA教材” 了解CDA考試詳情;
? 想加入CDA考試題庫���,點擊>>> “CDA題庫” 了解CDA考試詳情��;
? 想了解CDA考試含金量�����,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330