實時計算 流數(shù)據(jù)處理系統(tǒng)簡單分析_數(shù)據(jù)分析師
一. 實時計算的概念
實時計算一般都是針對海量數(shù)據(jù)進行的����,一般要求為秒級。實時計算主要分為兩塊:數(shù)據(jù)的實時入庫����、數(shù)據(jù)的實時計算�����。
主要應用的場景:
1) 數(shù)據(jù)源是實時的不間斷的��,要求用戶的響應時間也是實時的(比如對于大型網站的流式數(shù)據(jù):網站的訪問PV/UV���、用戶訪問了什么內容�����、搜索了什么內容等�����,實時的數(shù)據(jù)計算和分析可以動態(tài)實時地刷新用戶訪問數(shù)據(jù)����,展示網站實時流量的變化情況����,分析每天各小時的流量和用戶分布情況)
2) 數(shù)據(jù)量大且無法或沒必要預算����,但要求對用戶的響應時間是實時的���。比如說:
昨天來自每個省份不同性別的訪問量分布�,昨天來自每個省份不同性別不同年齡不同職業(yè)不同名族的訪問量分布����。
二. 實時計算的相關技術
主要分為三個階段(大多是日志流):
數(shù)據(jù)的產生與收集階段、傳輸與分析處理階段�����、存儲對對外提供服務階段
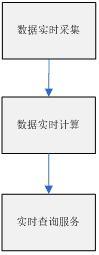
下面具體針對上面三個階段詳細介紹下
1)數(shù)據(jù)實時采集:
需求:功能上保證可以完整的收集到所有日志數(shù)據(jù)����,為實時應用提供實時數(shù)據(jù);響應時間上要保證實時性���、低延遲在1秒左右�����;配置簡單��,部署容易���;系統(tǒng)穩(wěn)定可靠等�����。
目前的產品:Facebook的Scribe、LinkedIn的Kafka�����、Cloudera的Flume����,淘寶開源的TimeTunnel、Hadoop的Chukwa等�,均可以滿足每秒數(shù)百MB的日志數(shù)據(jù)采集和傳輸需求。他們都是開源項目�����。
2)數(shù)據(jù)實時計算
在流數(shù)據(jù)不斷變化的運動過程中實時地進行分析�����,捕捉到可能對用戶有用的信息,并把結果發(fā)送出去���。

實時計算目前的主流產品:
-
Yahoo的S4:S4是一個通用的�、分布式的�����、可擴展的��、分區(qū)容錯的�、可插拔的流式系統(tǒng),Yahoo開發(fā)S4系統(tǒng)��,主要是為了解決:搜索廣告的展現(xiàn)�����、處理用戶的點擊反饋�。
-
Twitter的Storm:是一個分布式的、容錯的實時計算系統(tǒng)����?����?捎糜谔幚硐⒑透聰?shù)據(jù)庫(流處理)�,在數(shù)據(jù)流上進行持續(xù)查詢���,并以流的形式返回結果到客戶端(持續(xù)計算)�,并行化一個類似實時查詢的熱點查詢(分布式的RPC)�����。
-
Facebook 的Puma:Facebook使用puma和HBase相結合來處理實時數(shù)據(jù)���,另外Facebook發(fā)表一篇利用HBase/Hadoop進行實時數(shù)據(jù)處理的論文(ApacheHadoop Goes Realtime at Facebook),通過一些實時性改造����,讓批處理計算平臺也具備實時計算的能力。
關于這三個產品的具體介紹架構分析:http://www.kuqin.com/system-analysis/20120111/317322.html
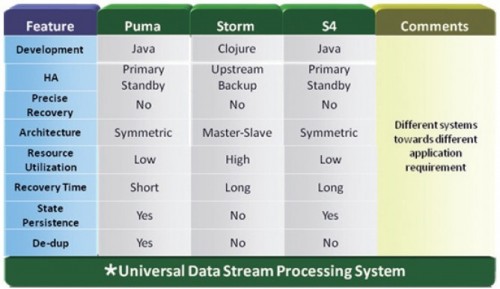
下面是S4和Storm的詳細對比

其他的產品:
早期的:IBM的Stream Base��、 Borealis��、Hstreaming、Esper
4. 淘寶的實時計算�、流式處理
1) 銀河流數(shù)據(jù)處理平臺:通用的流數(shù)據(jù)實時計算系統(tǒng),以實時數(shù)據(jù)產出的低延遲��、高吞吐和復用性為初衷和目標���,采用actor模型構建分布式流數(shù)據(jù)計算框架(底層基于akka)���,功能易擴展、部分容錯�����、數(shù)據(jù)和狀態(tài)可監(jiān)控���。銀河具有處理實時流數(shù)據(jù)(如TimeTunnel收集的實時數(shù)據(jù))和靜態(tài)數(shù)據(jù)(如本地文件����、HDFS文件)的能力���,能夠提供靈活的實時數(shù)據(jù)輸出���,并提供自定義的數(shù)據(jù)輸出接口以便擴展實時計算能力。銀河目前主要是為魔方提供實時的交易、瀏覽和搜索日志等數(shù)據(jù)的實時計算和分析�����。
2) 基于Storm的流式處理���,統(tǒng)計計算����、持續(xù)計算���、實時消息處理����。
在淘寶���,Storm被廣泛用來進行實時日志處理,出現(xiàn)在實時統(tǒng)計�����、實時風控���、實時推薦等場景中����。一般來說,我們從類kafka的metaQ或者基于HBase的timetunnel中讀取實時日志消息�����,經過一系列處理�����,最終將處理結果寫入到一個分布式存儲中����,提供給應用程序訪問。我們每天的實時消息量從幾百萬到幾十億不等��,數(shù)據(jù)總量達到TB級����。對于我們來說,Storm往往會配合分布式存儲服務一起使用�����。在我們正在進行的個性化搜索實時分析項目中,就使用了timetunnel +HBase + Storm + UPS的架構�����,每天處理幾十億的用戶日志信息�����,從用戶行為發(fā)生到完成分析延遲在秒級���。
3) 利用Habase實現(xiàn)的Online應用
4)實時查詢服務
-
半內存:使用Redis�����、Memcache�����、MongoDB���、BerkeleyDB等內存數(shù)據(jù)庫提供數(shù)據(jù)實時查詢服務,由這些系統(tǒng)進行持久化操作�。
-
全磁盤:使用HBase等以分布式文件系統(tǒng)(HDFS)為基礎的NoSQL數(shù)據(jù)庫��,對于key-value引擎,關鍵是設計好key的分布��。
-
全內存:直接提供數(shù)據(jù)讀取服務���,定期dump到磁盤或數(shù)據(jù)庫進行持久化�。
關于實時計算流數(shù)據(jù)分析應用舉例:
對于電子商務網站上的店鋪:
1) 實時展示一個店鋪的到訪顧客流水信息�,包括訪問時間、訪客姓名�、訪客地理位置、訪客IP��、訪客正在訪問的頁面等信息���;
2) 顯示某個到訪顧客的所有歷史來訪記錄��,同時實時跟蹤顯示某個訪客在一個店鋪正在訪問的頁面等信息��;
3) 支持根據(jù)訪客地理位置����、訪問頁面��、訪問時間等多種維度下的實時查詢與分析���。
下面對Storm詳細介紹下:
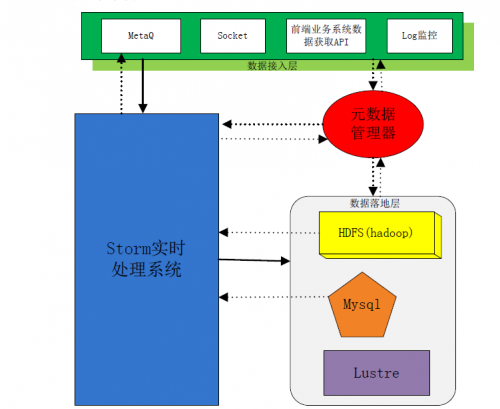
整體架構圖
整個數(shù)據(jù)處理流程包括四部分:
第一部分是數(shù)據(jù)接入該部分從前端業(yè)務系統(tǒng)獲取數(shù)據(jù)���。
第二部分是最重要的Storm 實時處理部分�,數(shù)據(jù)從接入層接入�����,經過實時處理后傳入數(shù)據(jù)落地層��;
第三部分為數(shù)據(jù)落地層�,該部分指定了數(shù)據(jù)的落地方式;
第四部分元數(shù)據(jù)管理器�����。
數(shù)據(jù)接入層
該部分有多種數(shù)據(jù)收集方式�,包括使用消息隊列(MetaQ),直接通過網絡Socket傳輸數(shù)據(jù)�,前端業(yè)務系統(tǒng)專有數(shù)據(jù)采集API,對Log問價定時監(jiān)控�����。(注:有時候我們的數(shù)據(jù)源是已經保存下來的log文件�����,那Spout就必須監(jiān)控Log文件的變化�,及時將變化部分的數(shù)據(jù)提取寫入Storm中,這很難做到完全實時性�����。)
Storm實時處理層
首先我們通過一個 Storm 和Hadoop的對比來了解Storm中的基本概念�。

(Storm關注的是數(shù)據(jù)多次處理一次寫入,而Hadoop關注的是數(shù)據(jù)一次寫入��,多次處理使用(查詢)�����。Storm系統(tǒng)運行起來后是持續(xù)不斷的�,而Hadoop往往只是在業(yè)務需要時調用數(shù)據(jù)。兩者關注及應用的方向不一樣����。)
1. Nimbus:負責資源分配和任務調度。
2. Supervisor:負責接受nimbus分配的任務�����,啟動和停止屬于自己管理的worker進程。
3. Worker:運行具體處理組件邏輯的進程��。
4. Task:worker中每一個spout/bolt的線程稱為一個task. 在Storm0.8之后��,task不再與物理線程對應����,同一個spout/bolt的task可能會共享一個物理線程,該線程稱為executor��。
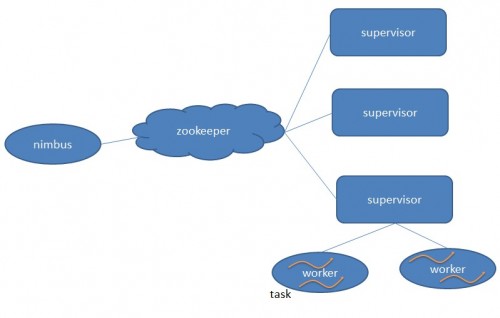
具體業(yè)務需求:條件過濾�、中間值計算、求topN�����、推薦系統(tǒng)�����、分布式RPC�、熱度統(tǒng)計
數(shù)據(jù)落地層:
MetaQ
如圖架構所示,Storm與MetaQ是有一條虛線相連的���,部分數(shù)據(jù)在經過實時處理之后需要寫入MetaQ之中���,因為后端業(yè)務系統(tǒng)需要從MetaQ中獲取數(shù)據(jù)��。這嚴格來說不算是數(shù)據(jù)落地�����,因為數(shù)據(jù)沒有實實在在寫入磁盤中持久化。
Mysql
數(shù)據(jù)量不是非常大的情況下可以使用Mysql作為數(shù)據(jù)落地的存儲對象�。Mysql對數(shù)據(jù)后續(xù)處理也是比較方便的,且網絡上對Mysql的操作也是比較多的���,在開發(fā)上代價比較小����,適合中小量數(shù)據(jù)存儲��。
HDFS
HDFS及基于Hadoop的分布式文件系統(tǒng)����。許多日志分析系統(tǒng)都是基于HDFS搭建出來的,所以開發(fā)Storm與HDFS的數(shù)據(jù)落地接口將很有必要�����。例如將大批量數(shù)據(jù)實時處理之后存入Hive中,提供給后端業(yè)務系統(tǒng)進行處理���,例如日志分析����,數(shù)據(jù)挖掘等等�。
Lustre
Lustre作為數(shù)據(jù)落地的應用場景是,數(shù)據(jù)量很大�����,且處理后目的是作為歸檔處理��。這種情形���,Lustre能夠為數(shù)據(jù)提供一個比較大(相當大)的數(shù)據(jù)目錄�,用于數(shù)據(jù)歸檔保存�。
元數(shù)據(jù)管理器
元數(shù)據(jù)管理器的設計目的是,整個系統(tǒng)需要一個統(tǒng)一協(xié)調的組件��,指導前端業(yè)務系統(tǒng)的數(shù)據(jù)寫入���,通知實時處理部分數(shù)據(jù)類型及其他數(shù)據(jù)描述����,及指導數(shù)據(jù)如何落地。元數(shù)據(jù)管理器貫通整個系統(tǒng)�����,是比較重要的組成部分���。元數(shù)據(jù)設計可以使用mysql存儲元數(shù)據(jù)信息,結合緩存機制開源軟件設計而成�����。
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試�,點擊>>>
“CDA報名”
了解CDA考試詳情�;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情����;
? 想加入CDA考試題庫����,點擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量���,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網安備 11010802034615號
經營許可證編號:京B2-20210330
京公網安備 11010802034615號
經營許可證編號:京B2-20210330