引入
一個(gè)機(jī)器可以根據(jù)照片來(lái)辨別鮮花的品種嗎��?在機(jī)器學(xué)習(xí)角度�,這其實(shí)是一個(gè)分類(lèi)問(wèn)題,即機(jī)器根據(jù)不同品種鮮花的數(shù)據(jù)進(jìn)行學(xué)習(xí)���,使其可以對(duì)未標(biāo)記的測(cè)試圖片數(shù)據(jù)進(jìn)行分類(lèi)���。這一小節(jié),我們還是從scikit-learn出發(fā)�����,理解基本的分類(lèi)原則�,多動(dòng)手實(shí)踐�����。
Iris數(shù)據(jù)集
Iris flower數(shù)據(jù)集是1936年由Sir Ronald Fisher引入的經(jīng)典多維數(shù)據(jù)集�����,可以作為判別分析(discriminant analysis)的樣本�。該數(shù)據(jù)集包含Iris花的三個(gè)品種(Iris setosa, Iris virginica and Iris versicolor)各50個(gè)樣本,每個(gè)樣本還有4個(gè)特征參數(shù)(分別是萼片<sepals>的長(zhǎng)寬和花瓣<petals>的長(zhǎng) 寬���,以厘米為單位)���,F(xiàn)isher利用這個(gè)數(shù)據(jù)集開(kāi)發(fā)了一個(gè)線(xiàn)性判別模型來(lái)辨別花朵的品種�?�;贔isher的線(xiàn)性判別模型��,該數(shù)據(jù)集成為了機(jī)器學(xué)習(xí)中各 種分類(lèi)技術(shù)的典型實(shí)驗(yàn)案例���。

現(xiàn)在我們要解決的分類(lèi)問(wèn)題是�,當(dāng)我們看到一個(gè)新的iris花朵�,我們能否根據(jù)以上測(cè)量參數(shù)成功預(yù)測(cè)新iris花朵的品種。
我們利用給定標(biāo)簽的數(shù)據(jù)���,設(shè)計(jì)一種規(guī)則進(jìn)而應(yīng)用到其他樣本中做預(yù)測(cè)��,這是基本的監(jiān)督問(wèn)題(分類(lèi)問(wèn)題)�����。
由于iris數(shù)據(jù)集樣本量和維度都很小����,所以可以方便進(jìn)行可視化和操作。
數(shù)據(jù)的可視化(visualization)
scikit-learn自帶有一些經(jīng)典的數(shù)據(jù)集����,比如用于分類(lèi)的iris和digits數(shù)據(jù)集,還有用于回歸分析的boston house prices數(shù)據(jù)集���??梢酝ㄟ^(guò)下面的方式載入數(shù)據(jù):
from sklearn import datasets
iris = datasets.load_iris()
digits = datasets.load_digits()
該數(shù)據(jù)集是一種字典結(jié)構(gòu)��,數(shù)據(jù)存儲(chǔ)在.data成員中�,輸出標(biāo)簽存儲(chǔ)在.target成員中。
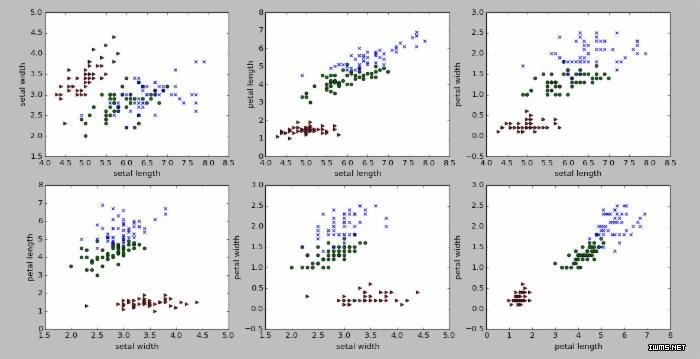
畫(huà)出任意兩維的數(shù)據(jù)散點(diǎn)圖
可以用下面的方式畫(huà)出任意兩個(gè)維度的散點(diǎn)圖�,這里以第一維sepal length和第二維數(shù)據(jù)sepal width為例:
from sklearn import datasets import matplotlib.pyplot as plt import numpy as np
iris = datasets.load_iris()
irisFeatures = iris["data"]
irisFeaturesName = iris["feature_names"]
irisLabels = iris["target"]
def scatter_plot(dim1, dim2): for t,marker,color in zip(xrange(3),">ox","rgb"):
# zip()接受任意多個(gè)序列參數(shù)�����,返回一個(gè)元組tuple列表
# 用不同的標(biāo)記和顏色畫(huà)出每種品種iris花朵的前兩維數(shù)據(jù)
# We plot each class on its own to get different colored markers plt.scatter(irisFeatures[irisLabels == t,dim1], irisFeatures[irisLabels == t,dim2],marker=marker,c=color) dim_meaning = {0:'setal length',1:'setal width',2:'petal length',3:'petal width'}
plt.xlabel(dim_meaning.get(dim1))
plt.ylabel(dim_meaning.get(dim2))
plt.subplot(231)
scatter_plot(0,1)
plt.subplot(232)
scatter_plot(0,2)
plt.subplot(233)
scatter_plot(0,3)
plt.subplot(234)
scatter_plot(1,2)
plt.subplot(235)
scatter_plot(1,3)
plt.subplot(236)
scatter_plot(2,3)
plt.show()
效果如圖:
構(gòu)建分類(lèi)模型
根據(jù)某一維度的閾值進(jìn)行分類(lèi)
如果我們的目標(biāo)是區(qū)別這三種花朵��,我們可以做一些假設(shè)��。比如花瓣的長(zhǎng)度(petal length)好像將Iris Setosa品種與其它兩種花朵區(qū)分開(kāi)來(lái)����。我們可以以此來(lái)寫(xiě)一段小代碼看看這個(gè)屬性的邊界是什么:
petalLength = irisFeatures[:,2] isSetosa = (irisLabels == 0) maxSetosaPlength = petalLength[isSetosa].max()
minNonSetosaPlength = petalLength[~isSetosa].min() print ('Maximum of setosa:{0} '.format(maxSetosaPlength)) print ('Minimum of others:{0} '.format(minNonSetosaPlength)) '''
顯示結(jié)果是:
Maximum of setosa:1.9
Minimum of others:3.0
'''
我們根據(jù)實(shí)驗(yàn)結(jié)果可以建立一個(gè)簡(jiǎn)單的分類(lèi)模型,如果花瓣長(zhǎng)度小于2,就是Iris Setosa花朵���,否則就是其他兩種花朵�。
這個(gè)模型的結(jié)構(gòu)非常簡(jiǎn)單�,是由數(shù)據(jù)的一個(gè)維度閾值來(lái)確定的。我們通過(guò)實(shí)驗(yàn)確定這個(gè)維度的最佳閾值����。
以上的例子將Iris Setosa花朵和其他兩種花朵很容易的分開(kāi)了,然而我們不能立即確定Iris Virginica花朵和Iris Versicolor花朵的最佳閾值�����,我們甚至發(fā)現(xiàn)��,我們無(wú)法根據(jù)某一維度的閾值將這兩種類(lèi)別很完美的分開(kāi)�����。
比較準(zhǔn)確率來(lái)得到閾值
我們先選出非Setosa的花朵���。
irisFeatures = irisFeatures[~isSetosa] labels = irisLabels[~isSetosa] isVirginica = (labels == 2) #label 2 means iris virginica
這里我們非常依賴(lài)NumPy對(duì)于數(shù)組的操作���,isSetosa是一個(gè)Boolean值數(shù)組��,我們可以用它來(lái)選擇出非Setosa的花朵����。最后��,我 們還構(gòu)造了一個(gè)新的Boolean數(shù)組���,isVirginica����。接下來(lái)����,我們對(duì)每一維度的特征寫(xiě)一個(gè)循環(huán)小程序,然后看一下哪一個(gè)閾值能得到更好的準(zhǔn)確 率�。
irisFeatures = irisFeatures[~isSetosa]
labels = irisLabels[~isSetosa]
isVirginica = (labels == 2) bestAccuracy = -1.0 for fi in xrange(irisFeatures.shape[1]):
thresh = irisFeatures[:,fi].copy()
thresh.sort() for t in thresh:
pred = (irisFeatures[:,fi] > t)
acc = (pred == isVirginica).mean() if acc > bestAccuracy:
bestAccuracy = acc;
bestFeatureIndex = fi;
bestThreshold = t; print 'Best Accuracy:\t\t',bestAccuracy print 'Best Feature Index:\t',bestFeatureIndex print 'Best Threshold:\t\t',bestThreshold '''
最終結(jié)果:
Best Accuracy: 0.94
Best Feature Index: 3
Best Threshold: 1.6
'''
這里我們首先對(duì)每一維度進(jìn)行排序�,然后從該維度中取出任一值作為閾值的一個(gè)假設(shè),再計(jì)算這個(gè)假設(shè)的Boolean序列和實(shí)際的標(biāo)簽Boolean 序列的一致情況��,求平均���,即得到了準(zhǔn)確率����。經(jīng)過(guò)所有的循環(huán),最終得到的閾值和所對(duì)應(yīng)的維度�。最后,我們得到了最佳模型針對(duì)第四維花瓣的寬度petal width�,我們就可以得到這個(gè)決策邊界decision boundary。
評(píng)估模型——交叉檢驗(yàn)
上面��,我們得到了一個(gè)簡(jiǎn)單的模型��,并且針對(duì)訓(xùn)練數(shù)據(jù)實(shí)現(xiàn)了94%的正確率�,但這個(gè)模型參數(shù)可能過(guò)于優(yōu)化了。
我們需要的是評(píng)估模型針對(duì)新數(shù)據(jù)的泛化能力�,所以我們需要保留一部分?jǐn)?shù)據(jù),進(jìn)行更加嚴(yán)格的評(píng)估���,而不是用訓(xùn)練數(shù)據(jù)做測(cè)試數(shù)據(jù)���。為此,我們會(huì)保留一部分?jǐn)?shù)據(jù)進(jìn)行交叉檢驗(yàn)��。
這樣我們就會(huì)得到訓(xùn)練誤差和測(cè)試誤差�����,當(dāng)復(fù)雜的模型下,可能訓(xùn)練的準(zhǔn)確率是100%�,但是測(cè)試時(shí)效果可能只是比隨機(jī)猜測(cè)好一點(diǎn)。
交叉檢驗(yàn)
在許多實(shí)際應(yīng)用中����,數(shù)據(jù)是不充足的。為了選擇更好的模型�����,可以采用交叉檢驗(yàn)方法���。 交叉檢驗(yàn)的基本想法是重復(fù)地使用數(shù)據(jù)��;把給定數(shù)據(jù)進(jìn)行切分�,將切分的數(shù)據(jù)集組合為訓(xùn)練集和測(cè)試集���,在此基礎(chǔ)上反復(fù)地進(jìn)行訓(xùn)練�����、測(cè)試以及模型選擇。
S-fold交叉檢驗(yàn)
應(yīng)用最多的是S折交叉檢驗(yàn)(S-fold cross validation)����,方法如下:首先隨機(jī)地將已給數(shù)據(jù)切分為S個(gè)互不相交的大小相同的子集��;然后利用S-1個(gè)子集的數(shù)據(jù)訓(xùn)練模型��,利用余下的子集測(cè)試 模型��;將這一過(guò)程對(duì)可能的S種選擇重復(fù)進(jìn)行���;最后選出S次評(píng)測(cè)中平均測(cè)試誤差最小的模型。

如上圖�,我們將數(shù)據(jù)集分成5部分,即5-fold交叉檢驗(yàn)�����。接下來(lái)��,我們可以對(duì)每一個(gè)fold生成一個(gè)模型���,留出20%的數(shù)據(jù)進(jìn)行檢驗(yàn)�����。
leave-one-out交叉檢驗(yàn)方法
留一交叉檢驗(yàn)(leave-one-out cross validation)是S折交叉檢驗(yàn)的特殊情形�,是S為給定數(shù)據(jù)集的容量時(shí)情形。我們可以從訓(xùn)練數(shù)據(jù)中挑選一個(gè)樣本��,然后拿其他訓(xùn)練數(shù)據(jù)得到模型���,最后看該模型是否能將這個(gè)挑出來(lái)的樣本正確的分類(lèi)���。
def learn_model(features,labels): bestAccuracy = -1.0 for fi in xrange(features.shape[1]):
thresh = features[:,fi].copy()
thresh.sort() for t in thresh:
pred = (features[:,fi] > t)
acc = (pred == labels).mean() if acc > bestAccuracy:
bestAccuracy = acc;
bestFeatureIndex = fi;
bestThreshold = t; '''
print 'Best Accuracy:\t\t',bestAccuracy
print 'Best Feature Index:\t',bestFeatureIndex
print 'Best Threshold:\t\t',bestThreshold
''' return {'dim':bestFeatureIndex, 'thresh':bestThreshold, 'accuracy':bestAccuracy} def apply_model(features,labels,model): prediction = (features[:,model['dim']] > model['thresh']) return prediction error = 0.0 for ei in range(len(irisFeatures)): training = np.ones(len(irisFeatures), bool)
training[ei] = False testing = ~training
model = learn_model(irisFeatures[training], isVirginica[training])
predictions = apply_model(irisFeatures[testing],
isVirginica[testing], model)
error += np.sum(predictions != isVirginica[testing])
上面的程序,我們用所有的樣本對(duì)一系列的模型進(jìn)行了測(cè)試��,最終的估計(jì)說(shuō)明了模型的泛化能力���。
小結(jié)
對(duì)于上面對(duì)數(shù)據(jù)集進(jìn)行劃分時(shí)����,我們需要注意平衡分配數(shù)據(jù)��。如果對(duì)于一個(gè)子集���,所有的數(shù)據(jù)都來(lái)自一個(gè)類(lèi)別����,則結(jié)果沒(méi)有代表性?;谝陨系挠懻?�,我們利用一個(gè)簡(jiǎn)單的模型來(lái)訓(xùn)練����,交叉檢驗(yàn)過(guò)程給出了這個(gè)模型泛化能力的估計(jì)。
參考文獻(xiàn)
Wiki:Iris flower data set
Building Machine Learning Systems with Python
轉(zhuǎn)載請(qǐng)注明作者Jason Ding及其出處
Github主頁(yè)(http://jasonding1354.github.io/)
CSDN博客(http://blog.csdn.net/jasonding1354)
簡(jiǎn)書(shū)主頁(yè)(http://www.jianshu.com/users/2bd9b48f6ea8/latest_articles)
CDA數(shù)據(jù)分析師培訓(xùn)官網(wǎng)
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試��,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情����;
? 想學(xué)習(xí)CDA考試教材,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情��;
? 想加入CDA考試題庫(kù)��,點(diǎn)擊>>> “CDA題庫(kù)” 了解CDA考試詳情���;
? 想了解CDA考試含金量��,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營(yíng)許可證編號(hào):京B2-20210330