在商業(yè)分析中�,我們經(jīng)常會遇到以下問題:
不知道如何進行用戶行為分析,對用戶進行分類?
不知道哪些是重要價值客戶�����,他們能帶來什么��,應該如何維護?
這時候就需要用到用戶行為分析模型也就是我們通常所說的RFM模型了�。小編今天就給大家分享一下RFM模型的構建以及應用�����,希望對大家商業(yè)分析有所幫助。
一�、RFM模型簡介
RFM模型,是根據(jù)客戶活躍程度以及交易金額的貢獻����,對客戶價值進行細分的一種方法,是客戶關系管理中常應用到的一種操作模型���。RFM模型從R�����、F���、M�����、這3個維度來描述客戶的價值�����,下面來具體解釋一下R���、F�����、M�����、這3個維度����。
R:上一次消費 (Recency),客戶上一次消費的時間�����,時間越是接近就表示該客戶越有價值�,對于提供的即時商品或是服務,這些客戶是最有可能反應的�。
F:消費頻率 (Frequency),一段時間之內(nèi)對產(chǎn)品的消費頻次���,也就是客戶在限定的期間內(nèi)的購買的次數(shù)���。通常來說�����,客戶消費頻率越高�����,也就表示該客戶忠誠度越高�。
M:消費金額 (Monetary)����,用戶的貢獻價值,交易金額越高�����,該客戶價值越高�。帕雷托法則認為公司80%收入來自20%的客戶。

二���、RFM模型使用場景
RFM模型3個維度可根據(jù)實際需求變化,例如:
R:最近一次登錄時間�����、最近一次發(fā)帖時間、最近一次投資時間�、最近一次觀看時間
F:瀏覽次數(shù)、發(fā)帖次數(shù)����、評論次數(shù)
M:充值金額、打賞金額�、評論數(shù)��、點贊數(shù)
互動行為:最近一次互動時間���、互動頻次����、用戶的互動次數(shù);
直播行為:最近一次觀看直播時間���、直播觀看頻次��、觀看直播累計時長;
內(nèi)容行為:最近一次觀看內(nèi)容時間��、觀看內(nèi)容頻次���、觀看內(nèi)容字數(shù);
評論行為:最近一次評論時間��、評論頻次��、累計評論次數(shù)等等等等����。
三����、RFM模型搭建
1.計算每個客戶的RFM指標?��?梢岳肅RM軟件或者BI分析工具計算出每個客戶的R����,F(xiàn)����,M
2.根據(jù)實際業(yè)務需求,確定具體的R�,F(xiàn)�,M的度量范圍��。
3.在RFM表格中添加細分的段號。
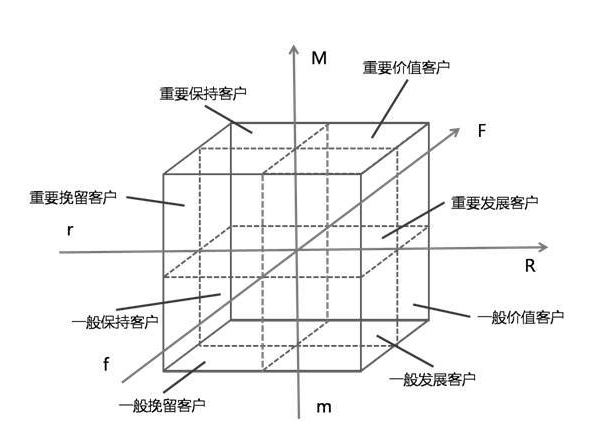
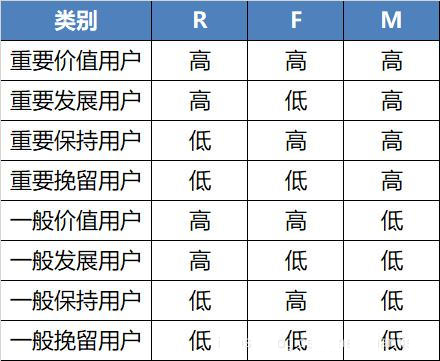
因為有R���,F(xiàn)����,M三個變量,所以我們需要使用三維坐標系來進行展示���,X軸表示R�����,Y 軸表示F�,Z軸表示M,坐標系的8個象限分別表示8類用戶也就是:重要價值客戶�、重要保持客戶、重要發(fā)展客戶�、重要挽留客戶、一般價值客戶�����、一般保持客戶�、一般發(fā)展客戶、一般挽留客戶�����,我們可以用如下圖形進行描述:
四����、簡單示例
import pandas as pd
import numpy as np
import time
#todo 讀取數(shù)據(jù)
data = pd.read_csv('RFM_TRAD_FLOW.csv',encoding='gbk')
# print(ret)
# todo RFM------>R(最近一次消費)
#todo 時間與字符串相互轉換
data['time'] = data['time'].map(lambda x:time.mktime(time.strptime(x,'%d%b%y:%H:%M:%S')))
# print(data)
# todo 分組
groupby_obj = data.groupby(['cumid','type'])
# for name,data in groupby_obj:
# print(name)
# print(data)
# todo 取值
R = groupby_obj[['time']].max()
# print(
# todo 轉為透視表
r_trans = pd.pivot_table(R,index='cumid',columns='type',values='time')
# print(data_trans)
# todo 替換缺失值 有缺失值�����,替換成最遠的值
r_trans[['Special_offer','returned_goods']] = r_trans[['Special_offer','returned_goods']].apply(lambda x:x.replace(np.nan,min(x)),axis = 0)
# print(data_trans)
r_trans['r_max'] = r_trans.apply(lambda x:sum(x),axis=1)
# print(r_trans)
# todo RFM------>F(消費頻率)
# 取值
F =groupby_obj[['transID']].count()
# print(F)
#轉為透視表
f_trans = pd.pivot_table(F,index='cumid',columns='type',values='transID')
# print(f_trans)
#替換缺失值
f_trans[['Special_offer','returned_goods']]= f_trans[['Special_offer','returned_goods']].fillna(0)
# print(f_trans)
#
f_trans['returned_goods'] = f_trans['returned_goods'].map(lambda x:-x)
# print(f_trans)
f_trans['f_total'] = f_trans.apply(lambda x:sum(x),axis=1)
# print(f_trans)
# todo RFM------>M(消費金額)
# 取值
M =groupby_obj[['amount']].sum()
# print(M)
#轉為透視表
m_trans = pd.pivot_table(M,index='cumid',columns='type',values='amount')
# print(f_trans)
#替換缺失值
m_trans[['Special_offer','returned_goods']]= m_trans[['Special_offer','returned_goods']].fillna(0)
# print(f_trans)
#
m_trans['m_total'] = m_trans.apply(lambda x:sum(x),axis=1)
# print(m_trans)
# 合并
RFM=pd.concat([r_trans["r_max"],f_trans['f_total'],m_trans['m_total']],axis=1)
print(RFM)
r_score = pd.cut(RFM.r_max,3,labels=[0,1,2])
f_score = pd.cut(RFM.r_max,3,labels=[0,1,2])
m_score = pd.cut(RFM.r_max,3,labels=[0,1,2])
CDA數(shù)據(jù)分析師考試相關入口一覽(建議收藏):
? 想報名CDA認證考試,點擊>>>
“CDA報名”
了解CDA考試詳情���;
? 想學習CDA考試教材����,點擊>>> “CDA教材” 了解CDA考試詳情�;
? 想加入CDA考試題庫,點擊>>> “CDA題庫” 了解CDA考試詳情�;
? 想了解CDA考試含金量,點擊>>> “CDA含金量” 了解CDA考試詳情��;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330