提到噪聲�����,你會(huì)想到什么?刺耳的����,高分貝的聲音?總之就是不好的,不想接受的聲音。小編今天跟大家分享的就是python數(shù)據(jù)清洗中的噪聲數(shù)據(jù)�����,對于這些噪聲數(shù)據(jù)我們應(yīng)該怎樣檢測和處理呢?下面跟小編一起來看吧�。
一����、什么是噪聲數(shù)據(jù)
噪聲數(shù)據(jù)Noisy Data,噪聲值��,指的是數(shù)據(jù)中存在著一個(gè)或中者幾個(gè)錯(cuò)誤的�����,或者偏離期望值的數(shù)據(jù)���,又可以叫做異常值��、或者離群值(outlier)����,這些數(shù)據(jù)會(huì)對數(shù)據(jù)的分析造成了干擾��,我們需要在python數(shù)據(jù)清洗時(shí)將這些數(shù)據(jù)清洗掉。
舉一個(gè)最簡單的例子來理解噪聲數(shù)據(jù)�,在一份統(tǒng)計(jì)顧客年齡的名單中,有數(shù)據(jù)為顧客年齡:-50.顯然這個(gè)數(shù)據(jù)就是噪聲數(shù)據(jù)����。
二、噪聲數(shù)據(jù)檢測
噪聲數(shù)據(jù)的檢測方法有很多�,小編這這里介紹三種最常用的方法。
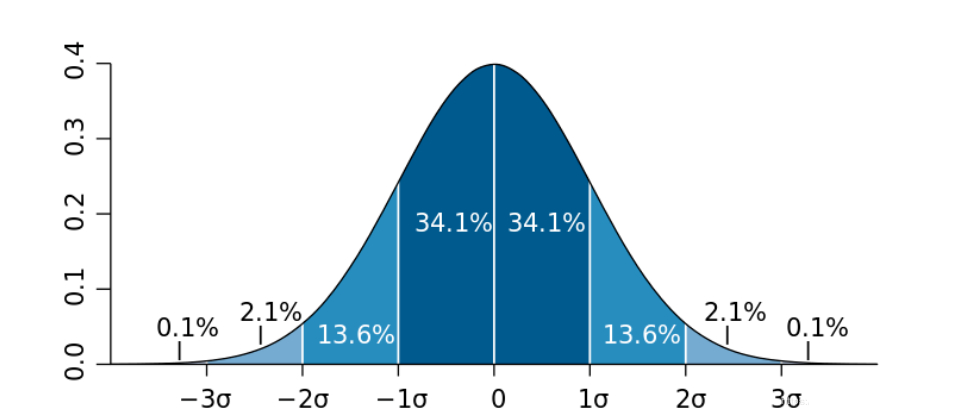
1.3?原則
數(shù)據(jù)需要服從正態(tài)分布�����。若一個(gè)數(shù)據(jù)分布近似正態(tài)��,則大約 68% 的數(shù)據(jù)值會(huì)在均值的一個(gè)標(biāo)準(zhǔn)差范圍內(nèi)����,大約 95% 會(huì)在兩個(gè)標(biāo)準(zhǔn)差范圍內(nèi),大約 99.7% 會(huì)在三個(gè)標(biāo)準(zhǔn)差范圍內(nèi)����。在3?原則下,異常值如超過3倍標(biāo)準(zhǔn)差�,那么可以將其視為異常值。如果數(shù)據(jù)不服從正態(tài)分布�����,我們就可以通過遠(yuǎn)離平均距離多少倍的標(biāo)準(zhǔn)差來判定(多少倍的取值需要根據(jù)經(jīng)驗(yàn)和實(shí)際情況來決定)。
2.箱線圖是通過數(shù)據(jù)集的四分位數(shù)形成的圖形化描述���。是非常簡單而且效的可視化離群點(diǎn)的一種方法�。上下須為數(shù)據(jù)分布的邊界���,只要是高于上須,或者是低于下觸須的數(shù)據(jù)點(diǎn)都可以認(rèn)為是離群點(diǎn)或異常值�。
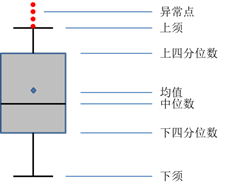
下四分位數(shù):25%分位點(diǎn)所對應(yīng)的值(Q1)
中位數(shù):50%分位點(diǎn)對應(yīng)的值(Q2)
上四分位數(shù):75%分位點(diǎn)所對應(yīng)的值(Q3)
上須:Q3+1.5(Q3-Q1)
下須:Q1-1.5(Q3-Q1)
其中Q3-Q1表示四分位差
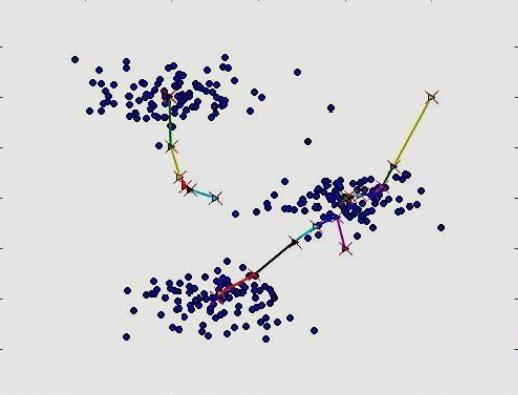
3.k-means
k-means是基于聚類的離群點(diǎn)識別方法,其主要思想是一個(gè)對象是基于聚類的離群點(diǎn)�����,如果該對象不強(qiáng)屬于任何簇�����,那么該對象屬于離群點(diǎn)�����。
三����、噪聲數(shù)據(jù)處理
噪聲數(shù)據(jù)最直接簡單的方法是:找到這些孤立于其他數(shù)據(jù)的記錄直接刪除�����。但是這樣做有很大的缺點(diǎn)�,很可能會(huì)都是大量有用�、干凈的信息。小編在這里整理了幾種python數(shù)據(jù)清洗時(shí)常用的噪聲數(shù)據(jù)處理方法�,希望對大家有所幫助。
1.分箱
分箱法通過考察數(shù)據(jù)的“近鄰”來光滑有序數(shù)據(jù)的值����。有序值分布到一些桶或箱中。
分箱法包括等深分箱:每個(gè)分箱中的樣本量一致;等寬分箱:每個(gè)分箱中的取值范圍一致�。直方圖其實(shí)首先對數(shù)據(jù)進(jìn)行了等寬分箱,再計(jì)算頻數(shù)畫圖��。
分箱方法是一種簡單而且常用的python數(shù)據(jù)清洗方法�,通過考察近鄰數(shù)據(jù)來確定最終值?��!胺窒洹逼鋵?shí)也就是指按照屬性值劃分的子區(qū)間�,一個(gè)屬性值如果處于某個(gè)子區(qū)間范圍內(nèi)��,就當(dāng)做把該屬性值放進(jìn)這個(gè)子區(qū)間所代表的“箱子”內(nèi)。按照一定的規(guī)則將待處理的數(shù)據(jù)(某列屬性值)放進(jìn)一些箱子中��,考察每個(gè)箱子里的數(shù)據(jù)���,并且采用某種方法對各個(gè)箱子中的數(shù)據(jù)分別進(jìn)行處理��。采用分箱技術(shù)的兩個(gè)關(guān)鍵問題是:(1)如何分箱(2)如何對每個(gè)箱子中的數(shù)據(jù)進(jìn)行平滑處理�����。
分箱的方法通常有4種�����,分別為:等深分箱法、等寬分箱法�、最小熵法和用戶自定義區(qū)間法。
(1)等深分箱法��,又叫做統(tǒng)一權(quán)重����,是指將數(shù)據(jù)集按記錄行數(shù)分箱,每箱樣本量一致����。最簡單的一種分箱方法�。
(2)等寬分箱法�,統(tǒng)一區(qū)間,使數(shù)據(jù)集在整個(gè)屬性值的區(qū)間上平均分布��,也就是每個(gè)分箱中的取值范圍一致����。
(3)用戶自定義區(qū)間,用戶可以根據(jù)實(shí)際情況自定義區(qū)間�����,使用這種方法能幫助當(dāng)用戶明確觀察到某些區(qū)間范圍內(nèi)的數(shù)據(jù)分布�。
2.回歸
發(fā)現(xiàn)兩個(gè)相關(guān)的變量之間的變化模式,通過使數(shù)據(jù)適合一個(gè)函數(shù)來平滑數(shù)據(jù)��。
若是變量之間存在依賴關(guān)系�,也就是y=f(x),那么就可以設(shè)法求出依賴關(guān)系f�����,再根據(jù)x來預(yù)測y��,這也是回歸問題的實(shí)質(zhì)。實(shí)際問題中更常為見的假設(shè)是p(y)=N(f(x))����,N為正態(tài)分布。假設(shè)y是觀測值并且存在噪聲數(shù)據(jù)�,根據(jù)我們求出的x和y之間的依賴關(guān)系,再根據(jù)x來更新y的值���,這樣就能去除其中的隨機(jī)噪聲�,這就是回歸去噪的原理 �����。
相信讀完上文��,你對隨機(jī)森林算法已經(jīng)有了全面認(rèn)識�。若想進(jìn)一步探索機(jī)器學(xué)習(xí)的前沿知識���,強(qiáng)烈推薦機(jī)器學(xué)習(xí)之半監(jiān)督學(xué)習(xí)課程�。

學(xué)習(xí)入口:https://edu.cda.cn/goods/show/3826?targetId=6730&preview=0
涵蓋核心算法���,結(jié)合多領(lǐng)域?qū)崙?zhàn)案例�����,還會(huì)持續(xù)更新�,無論是新手入門還是高手進(jìn)階都很合適。趕緊點(diǎn)擊鏈接開啟學(xué)習(xí)吧����!
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情���;
? 想學(xué)習(xí)CDA考試教材����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫�,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情���;
? 想了解CDA考試含金量����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330
京公網(wǎng)安備 11010802034615號
經(jīng)營許可證編號:京B2-20210330