HDFS 全稱為Hadoop Distributed File System��,是 hadoop 分布式文件系統(tǒng)�,具體來說,是指被設(shè)計(jì)成適合運(yùn)行在通用硬件(commodity hardware)上的分布式文件系統(tǒng)(Distributed File System)�。最主要的作用是作為 Hadoop 生態(tài)中各系統(tǒng)的存儲(chǔ)服務(wù)。HDFS是Hadoop項(xiàng)目的核心子項(xiàng)目���,為分布式計(jì)算中,數(shù)據(jù)存儲(chǔ)管理的基礎(chǔ)�,HDFS是基于流數(shù)據(jù)模式訪問和處理超大文件的需求被開發(fā)出來的,能夠在廉價(jià)的商用服務(wù)器上運(yùn)行�。HDFS 具有高容錯(cuò)性、高可靠性����、高可擴(kuò)展性�����、高獲得性���、高吞吐率等特征,這些特征使得HDFS為海量數(shù)據(jù)提供了不怕故障的存儲(chǔ)�����,從而為超大數(shù)據(jù)集(Large Data Set)的應(yīng)用處理帶來了很多便利��。
一���、HDFS特征
高度容錯(cuò)性:HDFS 最核心的架構(gòu)目標(biāo)是����,錯(cuò)誤檢測和快速��、自動(dòng)的恢復(fù) ���。數(shù)據(jù)會(huì)自動(dòng)保存多個(gè)副本�。它通過增加副本的形式,而且就算某一副本丟失����,HDFS也能自動(dòng)恢復(fù)。
支持大規(guī)模數(shù)據(jù)集: HDFS 應(yīng)用具有很大的數(shù)據(jù)集�����,可以支持整體上高的數(shù)據(jù)傳輸帶寬����,并且能夠支撐數(shù)以千萬集的文件。
支持流式讀取數(shù)據(jù): 一次寫入���,多次讀取���。而且文件一旦寫入,就不能進(jìn)行修改�,只能追加。這樣很好的保證了數(shù)據(jù)的一致性��。
高吞吐量:吞吐量是指單位時(shí)間內(nèi)完成的工作量��。HDFS通過并行處理數(shù)據(jù)����,從而大大減少了處理時(shí)間,實(shí)現(xiàn)了高吞吐量�����。
移動(dòng)計(jì)算而非移動(dòng)數(shù)據(jù):一個(gè)應(yīng)用的請求��,如果離它操作的數(shù)據(jù)越近就會(huì)越高效�,HDFS會(huì)把數(shù)據(jù)位置暴露給計(jì)算框架, 提供了將它們自己移動(dòng)到數(shù)據(jù)附近的接口�����。
異構(gòu)軟硬件平臺(tái)間的可移植性:平臺(tái)的可移植性���,方便用戶也方便 HDFS 作為大規(guī)模數(shù)據(jù)應(yīng)用平臺(tái)的推廣��。
二�、HDFS 常用命令參數(shù)
|
-help
|
輸出這個(gè)命令參數(shù)手冊
|
|
-ls
|
顯示目錄信息
|
|
-mkdir
|
在hdfs上創(chuàng)建目錄
|
|
-moveFromLocal
|
從本地剪切粘貼到hdfs
|
|
-moveToLocal
|
從hdfs剪切粘貼到本地
|
|
--appendToFile
|
追加一個(gè)文件到已經(jīng)存在的文件末尾
|
|
-cat
|
顯示文件內(nèi)容
|
|
-tail
|
顯示一個(gè)文件的末尾
|
|
-text
|
以字符形式打印一個(gè)文件的內(nèi)容
|
|
-chgrp��、-chmod�����、-chown
|
同linux文件系統(tǒng)中的用法,對(duì)文件所屬權(quán)限
|
|
-copyFromLocal
|
從本地文件系統(tǒng)中拷貝文件到hdfs路徑去
|
|
-copyToLocal
|
從hdfs拷貝到本地
|
|
-cp
|
從hdfs的一個(gè)路徑拷貝hdfs的另一個(gè)路徑
|
|
-mv
|
在hdfs目錄中移動(dòng)文件
|
|
-get
|
等同于copyToLocal���,就是從hdfs下載文件到本地
|
|
-getmerge
|
合并下載多個(gè)文件
|
|
-put
|
等同于copyFromLocal
|
|
-rm
|
刪除文件或文件夾
|
|
-rmdir
|
刪除空目錄
|
|
-df
|
統(tǒng)計(jì)文件系統(tǒng)的可用空間信息
|
|
-du
|
統(tǒng)計(jì)文件夾的大小信息
|
|
-count
|
統(tǒng)計(jì)一個(gè)指定目錄下的文件節(jié)點(diǎn)數(shù)量
|
|
-setrep
|
設(shè)置hdfs中文件的副本數(shù)量
|
三���、HDFS工作機(jī)制
1. HDFS集群包括兩大角色:NameNode、DataNode
2. NameNode負(fù)責(zé)管理整個(gè)文件系統(tǒng)的元數(shù)據(jù)
3. DataNode 負(fù)責(zé)管理用戶的文件數(shù)據(jù)塊
4. 文件會(huì)按照固定的大小(blocksize)切分成若干塊后���,分布式存儲(chǔ)于若干臺(tái)datanode上
5. 每一個(gè)文件塊能夠有多個(gè)副本�,并存放在不同的datanode上
6. Datanode定期會(huì)向Namenode匯報(bào)自身保存的文件block信息�����,而namenode就會(huì)負(fù)責(zé)保持文件的副本數(shù)量
7. HDFS的內(nèi)部工作機(jī)制對(duì)客戶端保持透明�,客戶端請求訪問HDFS都是以通過向namenode申請進(jìn)行的
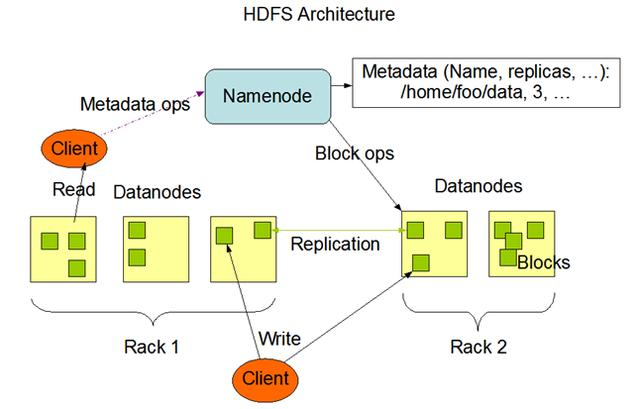
HDFS文件寫入時(shí):首先要跟namenode通信以確認(rèn)可以寫文件并獲得接收文件block的datanode,然后����,客戶端按順序?qū)⑽募饌€(gè)block傳遞給相應(yīng)datanode,并由接收到block的datanode負(fù)責(zé)向其他datanode復(fù)制block的副本
HDFS文件讀?��。簩⒁x取的文件路徑發(fā)送給namenode����,namenode獲取文件的元信息(主要是block的存放位置信息)返回給客戶端����,客戶端根據(jù)返回的信息找到相應(yīng)datanode逐個(gè)獲取文件的block并在客戶端本地進(jìn)行數(shù)據(jù)追加合并從而獲得整個(gè)文件
CDA數(shù)據(jù)分析師考試相關(guān)入口一覽(建議收藏):
? 想報(bào)名CDA認(rèn)證考試,點(diǎn)擊>>>
“CDA報(bào)名”
了解CDA考試詳情�����;
? 想學(xué)習(xí)CDA考試教材�����,點(diǎn)擊>>> “CDA教材” 了解CDA考試詳情���;
? 想加入CDA考試題庫����,點(diǎn)擊>>> “CDA題庫” 了解CDA考試詳情;
? 想了解CDA考試含金量�����,點(diǎn)擊>>> “CDA含金量” 了解CDA考試詳情;











 京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330
京公網(wǎng)安備 11010802034615號(hào)
經(jīng)營許可證編號(hào):京B2-20210330